Group Policy
Optimizing Group Policy Performance
Darren Mar-Elia
At a Glance:
- Monolithic vs. functional GPOs
- How to process group policy entries
- What happens when GP changes occur
I am frequently asked the question, "From a performance perspective, is it better to have fewer, bigger GPOs or a lot of smaller ones?" That question and others related to Group Policy design and performance are the focus of this article. And, as with most sweeping questions,
I can tell you the answer in advance: "It depends." While this may seem evasive, my goal is to illuminate the mechanisms that underlie Group Policy processing so you can make informed decisions about your Group Policy design, regardless of whether you are just starting out or looking to optimize an environment with hundreds of existing GPOs.
Monolithic vs. Functional GPOs
Let's start by describing the different ways you can implement your GPOs. The terms "monolithic" and "functional" refer to how you design them. Monolithic GPOs contain settings from many different areas. For example, a monolithic GPO might contain settings from Administrative Templates, Internet Explorer Maintenance, and Software Installation policies—all within a single GPO. By contrast, functional GPOs typically do one thing. For example, a functional GPO may do only Software Installation or enforce Security settings. I've even seen functional GPOs that contain only one policy setting! But that is probably the extreme. Figure 1 shows some of the advantages and disadvantages of each approach.
Figure 1 Comparing monolithic and functional GPOs
| Issue | Monolithic GPOs | Functional GPOs |
| Delegation/Isolation | Difficult, since each GPO can contain settings from multiple areas, and you can only delegate at the GPO level, not the settings level. | Easy, since each GPO contains a single policy area, you can delegate, for example, the software installation GPO to the deployment administrator, the security GPO to the security officer, and so on. |
| Manageability & Complexity | Potentially simpler and easier to manage, because each GPO contains all settings in a single place. | Potentially more difficult because more GPOs mean more places to look to track down problems and more complexity determining the resultant set of policy for a given user or computer. |
| Performance | Potentially slower because, for a given client-side extension, if one GPO changes, all extensions would need to run against all GPOs in scope. | Depends upon how many GPOs are in use, and how often they change. Performance could be better in dynamic environments compared to monolithic GPOs. |
As you can see, there is no cut-and-dried answer to which approach—monolithic or functional—is best in all cases. In your environment, you will likely need both. For example, you might find the functional approach preferable when you are creating security policy for your entire domain. Having a single GPO that contains only security settings makes it easy to delegate control of that GPO to your security administrators where no one else can touch it. By the same token, if you delegate GP administration to OU administrators, then establishing one monolithic GPO for each OU gives those administrators a single place where they can go to manage all of their policy settings. That can reduce complexity for them and allow you to moderate the number of GPOs created for a given OU's users and computers.
How do these high-level design decisions affect the performance of Group Policy processing, and how can you make smart decisions about GP design that minimize performance impacts? The first step in maximizing the performance of your Group Policy infrastructure is understanding how Group Policy processing works under the covers.
Understanding Group Policy Processing
Group Policy processing is a complex set of interactions involving many pieces of your Windows® and Active Directory® infrastructure. At a high level, there are two parts to Group Policy processing. The first is called Core, or Group Policy Infrastructure processing. In this phase, a Windows Group Policy client queries its closest domain controller to determine what the link speed to the DC is, where it lives in the Active Directory hierarchy (that is, which site, domain, and OU the client is a member of), and which GPOs apply to the computer or currently logged-on user. (It's important to note that in this context a client could be a server or workstation participating in an Active Directory domain.) Once the list of GPOs has been created, the next phase kicks in—Client-Side Extension (CSE) processing. During the CSE phase, each registered CSE processes the list of GPOs that have implemented settings in its area. For example, the Registry or Administrative Template CSE runs first in all cases and processes all GPOs that apply to the given computer or user and that have implemented registry policy within them.
The list that follows details the steps the Group Policy processing cycle goes through, including network interactions between the client and domain controller. It's important to remember that Group Policy applies to both computers and users. Therefore, each time policy processes—for example during a background refresh of Group Policy—the cycle I enumerate below will be repeated for both the computer and the currently logged on user account on a given system, since each can have a different set of policies applying to them. When this happens, Windows actually performs the processing cycle simultaneously for both computer and user, with each cycle running on a different thread within the Group Policy engine process. (The Winlogon process for Windows 2000, Windows XP, and Windows Server® 2003, and the Group Policy Client service in Windows Vista® and Windows Server 2008.)
Processing a GP is a six-step procedure:
- The client performs Internet Control Message Protocol (ICMP) slow-link detection to a domain controller in its site to determine link speed. In Windows Vista, the use of ICMP for slow-link detection is replaced by the Network Location Awareness (NLA) service.
- The client reads CSE status information from its local registry to determine which GPOs were processed last.
- The client uses LDAP to search the gpLink attribute in Active Directory on each container object within its location in the Active Directory hierarchy—first at the OU level (including all nested OUs), then at the domain, and finally at the Active Directory site level. From the results of this search, it builds a list of GPOs that must be evaluated for processing.
- Each GPO is then searched in Active Directory to determine whether the client (user or computer) has the necessary permissions to process it. Its version number, the path to the Group Policy Template (GPT) portion of the GPO in SYSVOL, and what CSEs are implemented in that GPO are also evaluated.
- The client then uses the Server Message Block (SMB) protocol to read the contents of the GPT and get the GPO's version number from the gpt.ini file. The version numbers in the Group Policy Container (GPC) and GPT are one factor that is used to determine whether a GPO has changed since the last processing cycle.
- Each CSE runs in the order that is registered under HKLM\Software\Microsoft\Windows NT\CurrentVersion\Winlogon\GPExtensions, and processes the GPOs that implement that CSE if the GPO has changed since last processing cycle (as determined during core processing). Each CSE also logs Resultant Set of User Policy (RSOP) data to Windows Management Instrumentation (WMI) during each refresh, if available.
Let's dissect this process and look at how performance can be impacted. The first thing to realize is that there is a difference between foreground and background processing. Foreground processing occurs for computers during a system restart and for users during a user logon. Background refreshes occur on workstations and member servers by default every 90 minutes plus up to 30 minutes in a randomized value. Background refreshes occur on domain controllers every 5 minutes by default. In Windows Vista, you can also have NLA-based refreshes, which are essentially background refresh events that are triggered by a previous failure of Group Policy processing due to the lack of access to a domain controller (as when the client was offline when a background interval occurred). Why are these distinctions important? Primarily because certain CSEs (for instance, the Software Installation and Folder Redirection CSEs) will not run during a background refresh. Likewise, logon/logoff or startup/shutdown scripts do not run during a background refresh.
Similarly, in Step 1 of this process, I mentioned the slow-link detection process. In pre-Windows Vista systems, this process relies on clients using ICMP to ping the domain controller to determine its availability and link speed. If the calculated link speed falls below a certain threshold value (the default is 500Kb/s) the link is considered to be slow and, again, certain CSEs, such as Software Installation, Folder Redirection, and Internet Explorer Maintenance, will not run. All of these conditions can have an impact on performance as well as on the expected delivery of policy.
Probably the aspect of the policy processing cycle with the greatest impact on performance is the logic that determines whether GPOs applying to a computer or user have changed. The Group Policy engine has a built-in optimization that says that if nothing has changed for a computer or user since the last time GP was processed, then no processing occurs. This can obviously have a tremendous impact on the time it takes your clients to process policy, especially if your GP environment is fairly static. Let's look in more detail at what constitutes a change.
When Group Policy Change Occurs
So, what constitutes a change in terms of Group Policy processing? There are a number of factors but the most obvious is that if you make a change to a GPO, clients processing that GPO will detect the change and reprocess that GPO. How does a client know that a GPO has changed? It relies on version numbers on the GPO and within the client to figure it out.
A GPO is composed of two pieces—the GPC stored in Active Directory under the CN=Policies, CN=System container within each domain, and the GPT stored in SYSVOL under the "Policies" folder. Each piece of the GPO contains a version number. For the GPC, this version number is stored in the versionNumber attribute on the GPC object. For the GPT, it's stored within the gpt.ini file at the root of a given GPT. The client also keeps a record of the version numbers of the GPOs it has processed (both per-computer and per-user) within its registry. This version information is held under HKLM\Software\Microsoft\Windows\Currentversion\Group Policy\History for the computer and HKLM\Software\Microsoft\Windows\Currentversion\Group Policy\<SID of User> for the user on each client.
When Group Policy processing occurs, one of the parts is to examine the version numbers of all GPOs that the computer or user are subject to and compare them to any processed during the last cycle, as found in the registry. If any of the version numbers of the current GPOs are different (note that they only have to be different—they could be bigger or smaller!), those GPOs will be processed during the current processing cycle. If not, they are not processed unless one of the other change conditions are met. Those other change conditions are as follows:
- A change in the list of GPOs that apply to a user or computer (a GPO has been added or removed)
- A change in the security group membership of a user or computer
- A change in a WMI filter linked to a GPO (a WMI filter has been added or removed)
If any of these change conditions are met, the client will reprocess policy during that cycle. But there are subtleties in this process that you need to be aware of, since they can have a significant impact on performance. For a given CSE, if 1 GPO out of 10 changes, then all GPOs must be processed for that CSE. Remember that processing happens on a per-CSE basis. However, CSEs must process policy in the order of precedence that controls processing (local GPOs first, then site-linked GPOs, then domain-linked GPOs, then OU-linked GPOs). Given this requirement, let's say a user has 10 GPOs that apply, each linked at different levels of the Active Directory hierarchy. And let's say that each of those 10 GPOs implement some Administrative Template policy settings. Now, an administrator comes along and changes a GPO linked to the domain—adding a new Administrative Template policy setting. Then the computer or user goes to process policy and notices that the version number of that changed GPO is greater than the last time it was processed, so the GPO needs to be processed again. But in order to maintain the order of precedence of GP processing, it must process all of the Administrative Template settings that apply to all of the GPOs. So a simple change to one GPO can have a potentially significant performance impact for that client.
Comparing Performance of Monolithic and Functional GPOs
Now that we've looked at the processing cycle and at how changes to your Group Policy environment impacts processing, let's loop back to our discussion of monolithic versus functional GPOs and how each approach impacts performance.
Monolithic GPOs can have a hidden performance penalty due to the way Group Policy versioning works. The reasons for this are not altogether obvious, but they have to do with the fact that there is no concept of per-CSE versioning within Group Policy processing. Let's say a user has three GPOs that apply to him. Each GPO is monolithic in that it implements several policy areas. For example, let's assume that each GPO implements Administrative Template policy, Software Installation policy and Folder Redirection policy. Now let's say that an administrator makes a change to Administrative Template policy in one of these GPOs. Its version number is advanced by that change. Then the user comes along and processes Group Policy. The Administrative Template CSE starts up and sees that one of the GPOs has changed, so it processes those three GPOs again.
When the Software Installation and Folder Redirection CSEs run, they also look at the GPO version numbers and notice the new version number on one of the GPOs. But because that version number doesn't tell them about what policy area was changed in that GPO, they go ahead and process all three GPOs again, just in case. The result is that, in a monolithic GPO implementation, making changes to one area of policy can cause processing activity in another area.
True, in the case of software installation or folder redirection policy, those CSEs may not actually perform any work because, for example, if an application has already been installed it's not going to be installed again. But the point is that this behavior can happen with any CSE and should be taken into account when you are designing monolithic GPOs. If you have a policy area that changes frequently, you might consider keeping GPOs that implement that policy area separate from other policy areas.
From a functional GPO perspective, the performance considerations are more obvious. If you have more GPOs per user or computer (because the functional approach typically involves more GPOs for a given set of policy settings), it means that the Group Policy engine has to spend more time enumerating those GPOs during the core phase of Group Policy processing. However, as we'll see in the next section, this may not necessarily impact performance in a significant way.
Measuring Group Policy Performance
Ultimately, in order to make good decisions about the performance of your Group Policy infrastructure, you need to be able to measure how Group Policy is performing in your real-life environment. Modeling or predicting Group Policy performance is nearly impossible, given the large number of factors that can impact a given processing cycle. For that reason, empirical measurement is your best bet for discovering if GP processing performance is a problem. What constitutes bad performance? Well, bad performance is any situation where Group Policy processing impacts your users' experience on their systems. This may be different for every organization, but the key is knowing you have a problem.
So how do you measure the duration of a given Group Policy processing cycle? Well, again, the answer is not simple. If you are running Windows Vista or Windows Server 2008, you can take advantage of the new Event Viewer Operational Logs. The Group Policy operational log within the Event Viewer, found under Applications and Services Logs\Microsoft\Windows\Group Policy\Operational, provides excellent instrumentation of each step of the Group Policy processing cycle, including time spent during each phase of processing (see Figure 2).
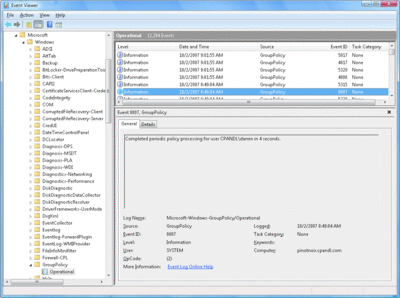
Figure 2 Group Policy Operational Log Event showing policy processing time (Click the image for a larger view)
However, if you are not working in a Windows Vista or Windows Server 2008 environment, the mechanisms for measuring policy processing times are less direct. In that case, your choices are to enable verbose userenv logging (see the Microsoft support article at support.microsoft.com/kb/221833) and view the timestamps within that file for a given processing cycle, or to use the values held in the registry on the client that indicate start and stop times for policy processing. These values are stored in the following for the computer
HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\
Group Policy\State\Machine\Extension-List\
{00000000-0000-0000-0000-000000000000}
and here for the user:
HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\
Group Policy\State\<SID of User>\Extension-List\
{00000000-0000-0000-0000-000000000000}
The values are stored in FILETIME format and must be converted to a normal date and time. You can also use the free GPTime.exe utility I wrote (available at gpoguy.com/tools.htm#GP_Time_Utility) to get the same information.
If you don't have a Windows Vista or Windows Server 2008 environment, but do have access to a userenv log, you can still get valuable information about how much time has been spent in each policy processing cycle. For example, Figure 3 displays a snippet of the userenv log showing part of the core phase of Group Policy processing.
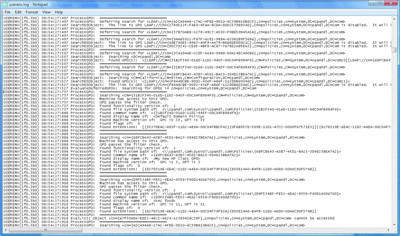
Figure 3 A portion of the userenv log (Click the image for a larger view)
Note that each line of the log file includes a timestamp. The core part of the Group Policy processing cycle begins when you see an event that says something like "ProcessGPOs: Starting user Group Policy (Background) processing ..." The CSE part of the processing cycle begins when you see the line "ProcessGPOs: Processing extension Registry." You can use this log and the timestamps within it to determine how long each part of a policy cycle takes.
General Observations on Performance
When you spend enough time looking at userenv log files, you begin to see patterns emerge, and though you can't predict how long policy processing will take, you can start to make some general observations about where time is spent in a given processing cycle. For example, during a policy processing event, when policy changes are being processed and CSEs have work to do because of a change, the time spent in the core part of GP processing is typically much smaller compared to the CSE part.
This is true for most policy areas because most CSEs need to perform tasks that run longer than the core portion of their processing, whose most expensive operations are querying Active Directory and SYSVOL. For example, there's no comparison between time spent in core processing versus the Software Installation CSE running a Microsoft® Office install. However, for a normal background refresh of policy where nothing has changed since the last cycle, the core part of the processing cycle takes roughly the same time as the CSE portion. The exception to this is registry policy processing—which is actually fairly fast unless you have tens or hundreds of registry policy settings in place for a given user or computer.
In addition, disabling the computer or user side of a GPO because it is unused has little effect on policy processing performance. If a policy side is unused, the only overhead will be in querying Active Directory to determine that, and the same query must be performed to view the disable option as the one that occurs to determine whether any CSEs have been implemented for that side of the GPO. The effect of disabling a side is negligible.
Design Recomendations for Optimal GP Performance
Now that we've looked at many aspects of Group Policy processing performance, there are some design recommendations that can directly impact performance. These are summarized in four key points.
- If you are making frequent changes to your GPOs, keep in mind the effect mentioned earlier, where a change to one CSE can impact the processing of all CSEs. To that end, if you plan to make frequent changes to, for example, registry policy, it makes more sense to put your registry policy into functional GPOs (GPOs that only do registry policy) as that will isolate other CSEs from processing when changes occur.
- When thinking about how many GPOs are too many, keep in mind that policy processing only occurs during changes, and "expensive" CSEs like Software Installation, Folder Redirection, or handling a large number of registry policies or setting permissions on large file or registry trees take up the most time. The time spent querying Active Directory for the list of GPOs during core processing is often the smallest part of the processing cycle. So, 30 GPOs that apply to a given user but do minimal registry policy changes and don't change frequently could take less time to process than 5 GPOs that are running expensive CSEs on a regular basis because those GPOs are changing frequently.
- Avoid behaviors that force obvious slowdowns in policy processing performance. For example, you can set policy to force CSEs to process even if a GPO has not changed (under Computer Configuration\Administrative Templates\System\Group Policy). However, if you do this, expect policy processing to take longer during each cycle.
- Keep in mind the trade-offs of disabling Fast Logon Optimization in Windows XP and Windows Vista (this is done by enabling the policy at Computer Configuration\Administrative Templates\System\Logon\Always wait for the network at computer startup and user logon). When this policy is enabled, foreground processing switches from asynchronous to synchronous. This means that computer and user policy must run to completion before the user gets control of the computer and desktop. However, it can also be beneficial because it gets around the problem of requiring two or more restarts or logons for Software Installation and Folder Redirection policy to take effect.
Wrap-Up
While Group Policy processing performance is not an exact science, there is some insight you can bring to your design process that can mitigate performance issues.
Understanding how the processing cycle works and where time is spent can go a long way toward tracking down performance issues. Use the Windows Vista or Windows Server 2008 Operational logs (or userenv logs in earlier versions of Windows) to get instrumented information about the processing cycle. Keep in mind the vagaries of CSE processing and what constitutes a change in policy from a CSE perspective. And remember that, in dynamic environments with lots of changes, functional GPOs may make more sense than monolithic ones. But the bottom line is that Group Policy is a technology designed to help you better manage your Windows environment. It's very important that your business needs drive your Group Policy design rather than the other way around. Keeping in mind some of the performance behaviors discussed here can help you accomplish that goal.
Darren Mar-Eliais a Microsoft Group Policy MVP, creator of the popular Group Policy site—www.gpoguy.com and coauthor of Microsoft Windows Group Policy Guide (Microsoft Press, 2005). He is also CTO and founder of SDM Software, Inc. Reach him at Darren@gpoguy.com.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.