Windows Administration
A Guide to Active Directory Replication
Laura E. Hunter
At a Glance:
- Transitioning to Active Directory
- Maintaining consistency
- Handling conflict resolution
- Changes in Windows Server 2008
Prior to the introduction of Windows 2000 Server and Active Directory, many corporate environments relied on Windows NT for their server infrastructure and identity and access
management. By the time Windows NT® 4.0 rolled out, it was a solid offering in the network operating system (NOS) space, but it had a number of drawbacks that made it difficult to deploy across a large enterprise.
For starters, Windows NT utilized a flat namespace to store network resources, which meant that there wasn't a good way to separate resources into smaller subsets or to configure any sort of granular administration. You could not, for example, configure a departmental container for the resources in your marketing department or configure a local administrator who had rights to reset passwords for the users within that department only. In this manner, Windows NT security was largely all-or-nothing; if you wanted to delegate administrative tasks to a desktop support engineer, you often were forced to grant far more permissions than you would have otherwise.
In addition, Windows NT stored all of its information in a Security Accounts Manager (SAM) database that was not meant to grow beyond 40MB in size. If your SAM database grew beyond this recommended maximum (this happened around 25,000-40,000 objects, depending on your configuration), you needed to split your environment into multiple separate domains, which complicated both administering the network and providing resource access to users. Each NT domain contained a single Primary Domain Controller (PDC), which contained the only read/write copy of the SAM database; while you could deploy one or more Backup Domain Controllers (BDCs) for fault tolerance, these BDCs were read-only and could not perform any update, such as changing a user's password, that required a write operation.
Finally, Windows NT relied on NetBIOS name resolution, which was broadcast-based and often generated a great deal of traffic as users browsed for network resources, particularly if they needed to do so across a slow or heavily-utilized WAN link.
A New Model Emerges
In the year 2000, Microsoft released Windows® 2000, which included a substantial overhaul of its previous NOS offerings. The new NOS service, Active Directory®, was as different from Windows NT as you could imagine. Rather than relying on a flat namespace, Active Directory was built on the X.500 standard, which created a hierarchical organizational structure; you could now organize resources into multiple Organizational Units within a single domain and delegate administration of each OU at a task-based level.
Another significant departure from Windows NT was the new model of multi-master replication. Gone was the single writeable PDC and its associated BDCs; in Active Directory, each domain controller had the ability to write to the Active Directory database.
However, while this created a great deal more flexibility in terms of supporting a large and/or decentralized environment, it also generated new challenges for maintaining the integrity of Active Directory. If John Smith and Jane Dow make a change to the same object in offices at opposite ends of the country, what happens if those changes are in conflict? The Active Directory replication model defines the ways in which updates are communicated to all domain controllers within an environment, as well as how to handle any conflicts that arise as a result of this multi-master ability to make changes from practically anywhere.
The Mechanics of Active Directory Replication
For the purpose of these examples, we will be discussing only intrasite replication. Basically, intrasite replication is designed to replicate changes quickly to DCs within the same site and is performed using change notification. In the case of intrasite replication, DC1 will notify DC2 that it has changes that need to be replicated, after which DC2 will pull those changes from DC1. Likewise, DC2 will notify DC1 when DC2 has any changes, after which DC1 will pull those changes from DC2. As you can see, all Active Directory replication takes place in pull operations, not pushes.
Since Active Directory can scale to hundreds of thousands or even millions of objects, it's necessary to carve up the Active Directory database into sections, called naming contexts. At minimum, each domain controller stores three NCs in its local copy of the Active Directory database.
Schema NC This NC is replicated to every other domain controller in the forest. It contains information about the Active Directory schema, which in turn defines the different object classes and attributes within Active Directory.
Configuration NC Also replicated to every other DC in the forest, this NC contains forest-wide configuration information pertaining to the physical layout of Active Directory, as well as information about display specifiers and forest-wide Active Directory quotas.
Domain NC This NC is replicated to every other DC within a single Active Directory domain. This is the NC that contains the most commonly-accessed Active Directory data: the actual users, groups, computers, and other objects that reside within a particular Active Directory domain.
In order to better optimize replication traffic, each naming context is replicated separately so that an NC that changes infrequently, such as the Schema NC, is not taking away network bandwidth that's needed by the Domain NC, which is likely to change on a much more frequent basis.
Since directory changes can be made from any Active Directory DC, there are two types of write operations that Active Directory replication needs to track. One type is originating writes, which is when a particular change was performed directly on a particular DC. For instance, if you connect to DC1 and change a user's password, that change is considered an originating write on DC1. Active Directory must also track replicated writes—as you might imagine, this means that a particular change was replicated in from another domain controller. The change that was considered an originating write on DC1 will be considered a replicated write when that change is replicated to DC2, DC3, and any other DCs throughout the domain.
Active Directory domain controllers manage the transmission of directory changes through the use of replication metadata. This means that, in addition to communicating the actual data that has been changed from one DC to another (John Smith's description was changed to 'HR Director'), Active Directory also transmits additional information about that change to allow domain controllers to manage replication in the most efficient manner, such as the DC that the change originated from, the time at which the change was made, and other key pieces of information.
The first item of replication metadata we'll discuss is the Update Sequence Number (USN). Each domain controller maintains a USN that is specific to that domain controller. Whenever a change is made to Active Directory from that DC, the USN is incremented by 1. So if a DC has a USN of 1000 at 11:00 a.m., and 1005 at 11:30 a.m., you know that 5 changes have been made to the Active Directory database on that DC. Exactly what these changes were is unimportant as far as the USN is concerned—you could have modified 5 different objects, created 5 objects, deleted 5 objects or any combination thereof, the DC's USN will still increase by 5. Moreover, USNs are internal to a specific domain controller only, and don't have any relevance when compared with other DCs. One DC in a domain might make a change at 11:30 a.m. that it assigns a USN of 1051, and a second DC in the same domain might make a change at precisely the same moment that it assigns a USN of 5084. While these two DCs clearly have radically different USNs for a change made at roughly the same time, this fact is irrelevant to how these changes are replicated; the Update Sequence Number of one DC has no meaning to any other DCs in terms of comparing one change to another.
But this is not the only way that a DC's USN can be incremented. Remember that a change to the Active Directory database can consist of an originating write or a replicated write. The Update Sequence Number on a domain controller is incremented by both types of write operations, which means that it is incremented whenever changes are replicated in from another DC. Now, clearly each DC needs a way to keep track of which changes have already been replicated, otherwise each DC would be sending the entire Active Directory database across the wire at every replication. To prevent this, each Active Directory domain controller maintains a value called the high watermark vector (HWMV) for other domain controllers that it is replicating with. Each DC will associate this high watermark vector with the Globally Unique Identifier (GUID) of the remote DC, to prevent any confusion if a remote domain controller is renamed or removed from the directory.
Let's start with a simple example, where you have two domain controllers configured in the contoso.com domain, dc1.contoso.com and dc2.contoso.com. Since there are only two DCs in the contoso.com domain, DC1 and DC2 replicate with each other only. (Note that this is a simplified example that doesn't tell the whole story of Active Directory replication yet; we will be adding onto it as we explain further details.)
Let's further say that DC1's current USN is 3000, DC2's current USN is 4500, and that these two DCs are fully up-to-date with one another as we begin our example:
Step 1: DC1 and DC2 are current with each other. DC1 has a high watermark vector for DC2 of 4500, and DC2 has a high watermark vector for DC1 of 3000, as shown in Figure 1.
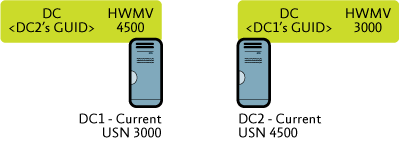
Figure 1 Current state of two DCs
Step 2: An administrator creates a new object on DC1, and DC1's USN is incremented to 3001, as shown in Figure 2. Notice that the HWMV of DC1 hasn't changed on DC2, because DC1 hasn't yet notified DC2 that it has changes waiting.
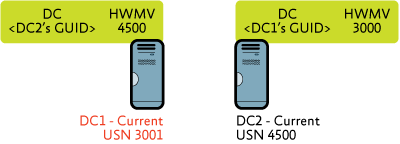
Figure 2 A new object is added
Step 3: DC1 notifies DC2 that it has changes available. DC2 then initiates replication with DC1 to request any updates that are available. As a part of this request, DC2 sends DC1 the high watermark vector that it has stored for DC1, as shown in Figure 3.
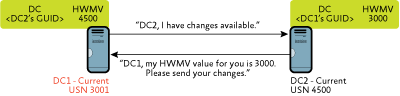
Figure 3 Notification of changes (Click the image for a larger view)
Step 4: DC1 sends DC2 the change that corresponds with USN 3001, that is, the object that was created on DC1 in Step 2. DC2 updates its own USN to 4501 and its HWMV for DC1 to 3001, as shown in Figure 4.
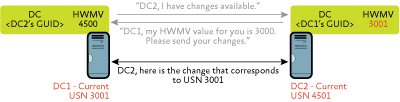
Figure 4 Changes and updates (Click the image for a larger view)
So far, so good, right? But now there's a problem. DC2 has a change that it needs to replicate. If the only thing to go on were USNs and high watermark vectors, at this point DC2 would contact DC1 to replicate the same change back to DC1 that DC1 just replicated to DC2, which would create an endless cycle of replication and chew up progressively more and more bandwidth. To combat this, we need to a few more pieces to the puzzle, the first of which is the up-to-dateness vector (UTD vector, or just UTDV).
The UTDV is another piece of replication metadata that is used for propagation dampening; that is, its purpose is to prevent the same change from wasting bandwidth by being replicated across the network over and over again. Each DC maintains a UTDV table for every other DC that stores a replica of the naming context in question. For the Domain NC, each DC in a domain maintains a UTDV for every DC in the domain; for the Configuration and Schema NC, this is maintained for every DC in the forest. The UTDV table keeps track, not only of the highest USN that each DC has received from its replication partners, but also the highest USN value that it has received from every DC that is replicating a given NC. To allow for this, each replicated change also includes the following information:
- The GUID of the DC that is replicating the change. This can be a change that is being replicated as an originating write or as a replicated write.
- The USN from the DC that is replicating the change. Again, this can be from either an originating or a replicated write.
- The GUID of the DC that originated the change. If this GUID is the same as the GUID of the DC that is replicating the change, then this is an originating write. Otherwise, the UTDV table comes into play.
- The USN from the DC that originated the change. Again, if this USN is the same as the USN of the DC that is replicating the change, then this is an originating write. Otherwise, it's off the UTDV table.
To better illustrate this process, we'll increase the complexity of our example by adding a third domain controller, DC3. In this instance, DC1, DC2, and DC3 are all replication partners with one another; DC1 replicates with DC2 and DC3, DC2 with DC1 and DC3, and DC3 with DC1 and DC2:
Step 1: DC1, DC2 and DC3 are all current with each other.
Step 2: DC3 performs a single originating write by resetting the password for the jsmith user account. DC3 notifies DC1 and DC2 that it has changes available. DC1 and DC2 pull in the originating write from DC3, and then update their HWMV and UTDV tables for DC3 as shown in Figure 5.
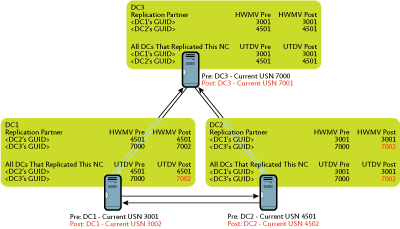
Figure 5 Updating HWMV and UTDV tables (Click the image for a larger view)
Step 3: Here's where the up-to-dateness vector comes into play. DC2 notifies DC1 that it has changes available. DC1 then contacts DC2 requesting any new changes by sending DC2 the following information:
- DC1's high watermark value for DC2, in this case 4501.
- DC1's UTDV table (shown in Figure 6), indicating the highest originating USN that it has received from all DCs including DC3.
Figure 6 UTDV table
| All DCs That Replicate This NC | UTDV |
| <DC2's GUID> | 4501 |
| <DC3's GUID> | 7002 |
Based on the HWMV of 4501, DC2 sees that it has not replicated the change in question to DC1 (see Figure 7).
Figure 7 A change needs to be replicated
| Property | Value | Local DC's GUID | Local USN | Originating DC's GUID | Originating USN |
| jsmith Password Property | %#FH%2rfg2 | <DC2's GUID> | 4501 | <DC3's GUID> | 7002 |
However, based on the UTDV table that DC1 transmitted before replication began, DC2 determines that DC1 doesn't actually require this change, since DC1 has already received this change from DC3. At this point, DC1 simply updates its HWMV entry for DC2 to reflect the incremented USN, as shown in Figure 8. However, to conserve bandwidth, the actual data is not sent over the wire.
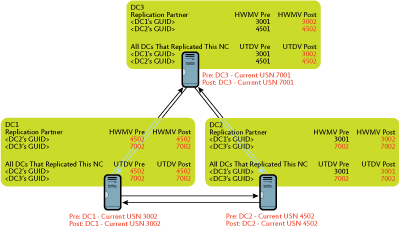
Figure 8 Propagation dampening (Click the image for a larger view)
Step 4: This same propagation dampening will take place when DC2 notifies DC3 that it has changes available, and when DC1 similarly notifies DC2 and DC3. All three DCs will update their respective HWMV entries for their replication partners as shown in Figure 8, but the actual data will not traverse the wire again since it has already been transmitted to each DC in Step 2.
Conflict Resolution in a Multi-Master Environment
Thus far our examples have existed in a perfect world, where only one administrator is making changes to a DC at a time and nobody ever steps on anyone else's toes. In the real world, we know this is seldom the case. Since updates to an Active Directory object can come from any domain controller in the domain, what happens if two administrators make conflicting updates from two different domain controllers? There are three types of conflicts that can occur in an Active Directory environment, each of which uses a different method of conflict resolution.
Conflicting property changes . This conflict occurs if two administrators update the same object in a way that conflicts: one administrator sets a user's description to "Marketing," while another administrator on a different DC sets that user's description to "Sales and Marketing."
Creating new objects that conflict . This conflict occurs if two administrators create an object with the same name at the same time, such as two users named jsmith.
Moving an object into a deleted container . This type of conflict is much rarer, and takes place if one administrator creates or moves an object within a container, such as an OU, at the same time that another administrator on a different DC deletes that container.
To address the first two types of conflicts, it's time to introduce two more pieces of replication metadata that are used primarily for conflict resolution. The versionID value is assigned to each individual attribute on an object, with a starting value of 1 when the object is first created. The versionID gets incremented by 1 whenever an individual attribute is modified from any DC. So if the description attribute of a particular user gets updated from its default value (blank or <not set>) to "Marketing Department," the description attribute will have a versionID of 2. If the description is later modified to "Sales and Marketing Department," the description attribute will have a versionID of 3, and so on. This versionID is included with every replication entry along with the other pieces of metadata that we've already introduced.
The versionID can also be used to further cut down on replication traffic. For instance, if an administrator on DC2 has made multiple changes to a single attribute (perhaps he or she mistyped the change a few times) such that DC2 has originating writes corresponding to versionIDs 2, 3, 4, and 5, DC2 will only replicate the write that corresponds to the latest one, versionID 5. Since the earlier changes would simply be overwritten anyway, this provides a shortcut to reduce unnecessary bandwidth utilization.
Every change to Active Directory also includes the second additional piece of metadata used for conflict resolution, a timestamp, as part of the replication metadata, indicating when the modification was made.
The timestamp attribute is also used as a proactive measure of Active Directory replication health. If a DC hasn't seen any changes with a relatively recent timestamp from a particular DC, it will begin to generate error messages indicating that there may be an issue with the DC in question.
So how are these two attributes used in conflict resolution? Let's examine each type of conflict in turn.
Resolving Conflicting Property Changes
Consider the example of the jsmith user object in the contoso.com domain. An administrator on DC1 changes jsmith's description to "Marketing." Nearly simultaneously, an administrator on DC3 changes the same user's description to "Sales and Marketing." At this point, DC1's and DC3's information about jsmith's description attribute compare as shown in Figure 9.
Figure 9 Near-simultaneous changes
| Server | Property | Value | VersionID | Timestamp | Local DC's GUID | Local USN | Originating DC's GUID | Originating USN |
| DC1 | jsmith Description Property | "Marketing" | 2 | 2007-06-07 14:03:25 | <DC1's GUID> | 3003 | <DC1's GUID> | 3003 |
| DC3 | jsmith Description Property | "Sales and Marketing" | 2 | 2007-06-07 14:04:57 | <DC3's GUID> | 7003 | <DC3's GUID> | 7003 |
If DC2 receives both of these changes simultaneously, it will clearly need to determine which one is the "winning" change. The order of tiebreakers for conflict resolution is as follows:
- The modification that has the higher versionID will be accepted as the "winning" change; the "losing" change will be overwritten. In this case, the versionID is 2 for both records, so we need to move onto the second tiebreaker.
- If both records have the same versionID, the change that has the later timestamp will be accepted as the winning change; the losing change will be overwritten. In this case, the timestamp from DC3's originating write is later, so jsmith's description will be set to "Sales and Marketing." In the rare instance when both the versionID and timestamp are identical, we need a third and definitive tiebreaker:
- If both records have the same versionID and timestamp, whichever write was originated by the DC with the lower-numbered GUID will win; the write from the higher-numbered GUID will be overwritten. So if DC1's GUID is 1234567890 and DC3's GUID is 2345678901, the originating write from DC1 would win if both the versionID and timestamp were identical.
You are probably thinking, "Wouldn't it make more sense to have the timestamp be the first tie-breaker?" This isn't as cut-and-dried as you might think. If timestamp were the primary tie-breaker in Active Directory conflict resolution, the only thing that a malicious administrator would need to do to propagate his or her changes would be to set back the clock on one particular DC so that it would always win by way of timestamps.
Resolving Conflicting Object Creation
In cases where two objects are created with the same name, Active Directory will use the same three tie-breakers described in the previous section to determine which one is the "winning" object. Unlike the previous section, however, the "losing" object doesn't get overwritten. Instead, the losing object is renamed using the characters CNF (for conflict object), followed by a colon and the GUID of the "losing" object. This allows administrators to more methodically determine which object should be retained and which should be deleted.
Resolving an Object Move into a Deleted Container
As mentioned, resolving an object move into a deleted container is a relatively rare conflict, which only occurs in one of two scenarios. In one, an administrator on one DC creates an object within a particular container, for example the Training OU, at the same time that an administrator on another DC deletes the Training OU. The second scenario can occur when an administrator on one DC moves an object into a container at the same time that an administrator on another DC deletes that container.
Resolution in this case is fairly straightforward: Active Directory moves the "orphaned" object into a special container within Active Directory that was designed for this purpose, the LostAndFound container that exists off of the root of each Active Directory domain. For the contoso.com domain, the LostAndFound container would be found along the following LDAP path: LDAP://cn=LostAndFound,dc=contoso,dc=com. If you do not see the LostAndFound container when you open the Active Directory Users and Computers snap-in, simply click on View | Advanced Features.
Protecting Yourself from USN Rollback
One of the most grievous situations you can encounter in an Active Directory environment is also one of the simplest to avoid, once you understand its cause and how to work around it. USN rollback is an error condition that can completely shut down replication on your network, and is caused by allowing a domain controller to remain offline for too long and then returning it to service, or by restoring a domain controller using an unsupported method.
One underlying cause of USN rollback has to do with the way that object deletions are processed in the Active Directory multi-master environment. When an object is deleted on a DC, rather than simply removing the object outright, the object is tombstoned so that the tombstoned object can be replicated to other DCs, thus notifying them of the deletion. Most notably, a tombstoned object possesses an isDeleted attribute that's set to TRUE. In order to reduce the size of the tombstoned object, most of the values contained in the object, such as the description, personal information and group membership of a user object, are removed (for more information on this process, see Gil Kirkpatrick's article "Reanimating Active Directory Tombstone Objects," available online at technetmagazine.com/issues/2007/09).
USN rollback can occur because these tombstoned objects don't hang around indefinitely. They are purged completely from the Active Directory database after 60 or 180 days by default (depending on the version of Windows Server® that you were running when you first created your Active Directory environment.) This 60- or 180-day period is called the tombstone lifetime. All domain controllers need to be able to replicate at least once during this period or they become worse than useless; they create an opportunity for USN rollback. Basically, USN rollback occurs when a domain controller is so completely out-of-date that it has "missed" one or more tombstoned objects, and thus is unable to bring its local copy of the Active Directory database completely up-to-date with other DCs. To guard against this, any domain controller that has been offline for longer than the tombstone lifetime should not be returned to service; rather it should be rebuilt from scratch after removing the old DC's metadata from Active Directory using the steps found in Microsoft Knowledge Base article 216498 (support.microsoft.com/kb/216498).
The second cause of USN rollback occurs when a domain controller has been restored using an unsupported method, most frequently using a disk cloning or imaging tool. When this occurs, the restored Active Directory database does not realize that it has gone "back in time," because the restore method was not Active Directory-aware. USN rollback was difficult to detect in Windows 2000 and the initial release of Windows Server 2003, but Windows Server 2003 SP1 (and the upcoming Windows Server 2008) have built-in controls to detect when a DC has been restored improperly. In these newer OS versions, a DC will log Event ID 1115, 2095, 2103, and 2110 in the Directory Services event log; the text of these events, as well as the necessary steps to recover from USN rollback, can be found in Knowledge Base article 875495 (support.microsoft.com/kb/875495) for Windows Server 2003. (You can find information about dealing with USN rollback in Windows 2000 in Knowledge Base article 885875, available at support.microsoft.com/kb/885875.)
Updating the Multi-Master Model in 2008
With the upcoming release of Windows Server 2008, Microsoft has included a slight change to the multi-master model by introducing the Read-Only Domain Controller (RODC). The RODC is designed primarily for branch office deployments, or for any scenario where you don't have dedicated IT staff on-site at a particular location and need to take extra steps to ensure the integrity of a particular DC. While we could take up an entire article discussing all of the technical details of the RODC, let's review the key points you should be familiar with.
As the name indicates, the copy of the Active Directory database that resides on an RODC is read-only. You can connect to an RODC to read almost any information that you need, but you will not be able to perform any write operations on an RODC.
Second, an RODC doesn't perform any outbound replication. This is a fundamental change from the multi-master replication model that we've been discussing thus far. An RODC will receive inbound replication from other writeable Windows Server 2008 DCs, but it will not replicate any information whatsoever out to other DCs. This creates an additional layer of security such that, even if a malicious user were somehow able to modify Active Directory from the RODC, those modifications would not propagate out to the rest of your environment.
Perhaps most interesting of all, the RODC does not replicate user passwords by default. When the Active Directory database is replicated inbound to an RODC from a writeable DC, all user objects are replicated without the user's password information. This provides yet another layer of security in a branch environment, such that if a DC "grows legs and walks away," there is no password information resident on the DC's hard drive. Taken as a whole, these changes to the original idea of multi-master Active Directory replication create a much-improved model for securing domain controllers in branch offices or other remote locations.
Laura E. Hunter is a four-time recipient of the Microsoft MVP award in the area of Windows Server Networking. She is a 10-year veteran of the IT industry and has authored or coauthored numerous industry books, articles, and white papers, including Active Directory Cookbook, Second Edition (O'Reilly, 2006).
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.