Communications
Data Protection and Disaster Recovery for Exchange Server 2007
Lee Benjamin
At a Glance:
- Basic backup and restore
- Data continuity
- Replication technologies
- Alternative solutions
Microsoft Exchange Server was designed with backup in mind. Organizations need to back up their messaging data, and they have to be able to restore that information as well. To meet these needs, Microsoft built a full spectrum of data protection options, from traditional
backup and restore at the low end, to operational continuity, to true business continuity solutions that provide the highest levels of availability and disaster recovery. In this article, I look at those options and help you decide how to implement the best Exchange recovery solution for your organization.
LEVEL 1: BASIC BACKUP AND RESTORE
You can back up Exchange files by taking its databases offline, but you can also back it up while it is running. In fact, the latter is most often the recommended way to back up Exchange. But Exchange is more than a set of files. It is an information store with large database files and transaction logs. Messages sent to Exchange are recorded immediately in the transaction logs and when the system has some spare cycles (usually just a few milliseconds later), the messages are copied into the database itself. By getting the information to disk as quickly as possible, Exchange provides a very high level of recoverability. Fundamental to restoring Exchange is the availability of both sets of information. Should your system fail, it is the combination of a previous backup, along with all of the transactions since that point, that allow you to restore Exchange to the most recent information. Note that Exchange automatically replays transactions into a restored database as necessary.
The way backup programs access information in the Exchange database is through the Extensible Storage Engine (ESE) backup API or newer VSS solutions I will talk about later. Whenever an ESE backup is initiated, Exchange temporarily suspends all writes to its databases. At the same time that ESE temporarily sets the database into a read-only mode that makes it available to be copied in a full backup, it also makes use of a temporary database to hold new transactions that occur during the backup. When the backup is complete, ESE returns the database to its normal read/write mode and applies the transactions that have been accumulating in its temporary database. Backup also purges old transaction logs at the end of a successful backup process.
While this backup process is straightforward and transparent even to users who log on in the middle of the night while the backup is progressing, ESE can take a very long time to complete, especially because Exchange databases can range anywhere from a few gigabytes to a manageable 30 to 50, or even to 100GB—which becomes nearly impossible to back up overnight when using standard technologies. To get an idea of the options available using NTBackup.exe, take a look at Figure 1.
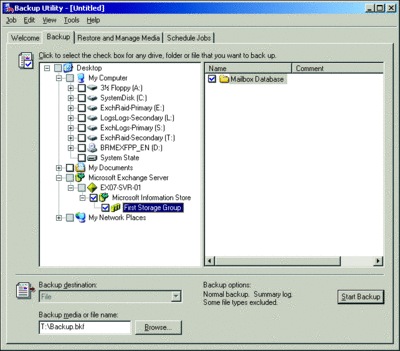
Figure 1** Using the NTBackup utility **
Best Practices for Exchange
If you want to be able to quickly recover from common hardware and system failures, you should run full Exchange backups nightly. To improve performance and recoverability whenever an Exchange server uses local disks, it is important that you use separate RAID arrays to store the Exchange databases and the Exchange transaction logs. That way, if a RAID array controller fails, or if more than one disk in the array fails so that the remaining disks can no longer reconstruct the striped data, you will still be able to recover. If you lose your transaction logs, you will still have up-to-date Exchange databases on the other drives that will let you continue normal operations with new transaction logs. If you lose the database drives, your recovery strategy is to go back to your previous night’s full backup for the Exchange databases and then apply the current day’s transaction logs to bring it up-to-date.
It is important that you limit the size of your Exchange databases so that each can be backed up—and more importantly, restored—in a reasonable amount of time. For most organizations, that means holding the size of the databases to between 30 and 50GB. When a database grows beyond that size, it is advisable to split it into multiple databases so that restoration will be manageable.
The Backup and Restore Continuum
Placement of the databases and transaction logs is very important—not only for backup performance but also for recovery speed. Today, all servers support various levels of disk drive redundancy, referred to as RAID. Basically, RAID allows a disk drive to fail without crashing the system, though system performance will be slower until the disk is replaced and rebuilt. Until that time, the array controller must reconstruct the data from the remaining disks on the fly in response to each disk access request. For more information on mailbox server storage design, see the Microsoft IT Showcase paper "Going 64-Bit with Exchange Server 2007".
A core feature of Exchange is its single-instance database design. This means that within an Exchange database, only a single copy of a specific message is stored, along with a single attachment (if one exists). If the message was sent to multiple recipients on the same information store, additional pointers to the objects (message, attachment) are created, but the objects are not duplicated. This is not only a great delivery efficiency benefit, but can also be a space saver for Exchange, both on disk and on tape.
While Exchange is good at bringing back the entire database, restoring individual mailboxes, folders, or messages requires bringing back the entire tape first. Not surprisingly, users wanted more granular restore capabilities. The single instance on the tape makes that very hard. Backup vendors responded to this need with the "Brick-Level Backup" (which I do not recommend). After completing a full backup of the Exchange database using the approved ESE Backup API, backup products then add each mailbox to the backup tape. Because the backup API does not provide a way to pull the data from individual mailboxes, MAPI is used. As a result, the backup tape is considerably longer because you are duplicating all those messages and attachments.
Microsoft has made some enhancements that partially address the problem. For example, the administrative wastebasket (or Dumpster) keeps items around for a period of time after they are deleted by users just in case they are needed. In addition, it is no longer necessary to keep a spare server around as an Exchange Recovery Forest; Recovery Storage Groups allow an administrator to partially mount restored databases that have been brought back from tape, and to copy or merge data down to the mailbox level.
Practice Makes Perfect
Many organizations learn the hard way that regardless of the level of backup and recovery they decide on, backup media and recovery procedures must be tested on a regular basis. Too many administrators learn whether their backup technology and restore procedures actually work only after a disaster. The best time to test is the day after you build and configure your shiny new server, when it is operational as part of your Exchange organization but has only a few users on it. At that time you should perform an Exchange Full Backup, regular backups of your drives, and also capture the System state, which includes the critical files on your system disk as well as the IIS metabase (where Exchange routing configuration is held). Then calmly reformat the new server and start over, updating the notes you took when you initially built the server. You should be able to restore settings from the System State, but also have adequate documentation to re-implement system configuration settings manually.
The time you spend on this fire drill will significantly reduce your recovery time in the future. Repeat the process on a periodic basis. While you are at it, time how long it takes to get tapes brought back from offsite. Those who have suffered through that seemingly interminable interval often begin to think more seriously about how disk-to-disk backups can be an important part of their backup and restore strategy—even if offsite tape storage continues to provide their ultimate backstop for disaster recovery.
Challenges of Tape Backup
Restoring from tape takes too much time. Exchange is now so critical to organizations that users and management expect it to always be available. When a serious problem occurs, most organizations are caught off guard. No one is prepared to hear that it will take eight hours to restore that 75GB database from tape—and that doesn’t even include the time spent getting the tapes from the offsite storage facility or reinstalling the operating system.
Moreover, there is also the challenge of retrieving the correct database from tape. In the 10 years since Exchange was first released, the cost of disk storage and wide area networks has fallen considerably. As a result, many organizations can afford faster methods of backup and restore. It’s feasible for these organizations to take advantage of technologies that enable them to gain operational continuity and disaster recovery for their Exchange infrastructure.
LEVEL 2: OPERATIONAL CONTINUITY
Operational Continuity is a set of processes and technologies meant to make recovery as quick as possible, minimizing unexpected downtime. Operational Continuity offers improved Recovery Time Objective (RTO) and Recovery Point Objective (RPO) over tape for local recovery. It strives to eliminate, wherever possible, the time it takes to get tapes back onsite. Take a look at Figure 2 to compare Operational Continuity to backup and restore and DR.
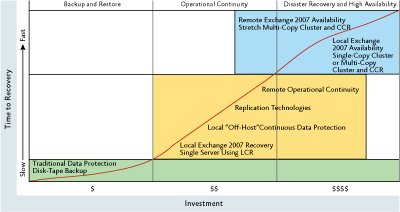
Figure 2** Recovery continuum **(Click the image for a larger view)
This diagram illustrates the recovery and availability continuum from slow and cheap at the lower left to fast and expensive at the upper right, with a deliberately fuzzy transition between operational continuity and disaster recovery solutions.
The graph gives you an idea of the tradeoffs between cost, time to recover, and availability across these approaches. In this article, I intentionally make a clear distinction between local continuity processes and disaster recovery. DR is always viewed as remote, with getting the data offsite a primary objective. Distance introduces additional challenges and typically is much more expensive, but DR is about the business continuing after catastrophic events. I will cover this in more depth later.
Some History
As Exchange became a more vital part of the infrastructure and as more information was stored in its databases, it was clear that backup and restore times would need to be reduced. Working with Microsoft, some large organizations came up with an approach that offered a much improved return to partial operations. If an organization could receive and send new e-mail to the outside world, it would appear as if nothing had happened. After all, appearances matter.
To implement this "dial-tone" restore for Exchange, a new empty database was put up in place of the damaged one. Exchange and Active Directory® then created new mailboxes with proper permissions, and users were able to send and receive. Once the backup tape was retrieved and the data recovered, it could be administratively mounted. The Exchange administrator would then merge the restored mailboxes into the dial-tone mailboxes. Mailboxes could be prioritized as needed. Though an improvement, this was a time-consuming and complex process that originally used EXMERGE, and was then adapted to Recovery Storage Groups. It should be noted though, that full data restoration after a dial-tone recovery scenario can be an arduous and complicated task (especially when up to 50 storage groups are possible in Exchange 2007). If you consider implementing a dial-tone recovery scenario, be careful to ensure that the benefits will outweigh the effort.
Volume Shadow Copy Services
To take advantage of cheaper disks and to remove processor overhead from the production Exchange servers, a new backup API was developed for Microsoft® Windows Server® 2003 and Exchange. The Volume Shadow Copy Service (VSS) was created to make consistent point-in-time copies of data. These snapshots are quick read-only copies of the Exchange data that successively include only the data that has changed. The copies usually point to another server with available disk space or to a Storage Area Network (SAN). Multiple snapshots can be kept, with backups made to tape. As a result, the production Exchange server no longer has to suffer the performance impact of the backup software and tape copy overhead.
There are several advantages to using VSS for Exchange data protection. First, the performance load of tape backup operations can be removed from your Exchange server. Though backup to tape still needs to happen, it can use the copy of the Exchange data and not impact user performance. Second, it becomes possible to take snapshots more frequently than once a night. And, as a bonus, you can keep multiple snapshots on the secondary server or other local storage.
There are a number of third-party products on the market that take advantage of the VSS snapshot capabilities. Some simply reduce the time required to back up and restore Exchange databases, while others add capabilities such as more granular recovery than native Exchange includes so you can restore down to the mailbox level. While no one likes such brick backups, people do want to be able to restore specific folders or even single messages.
Replication Technologies
Software-mediated Exchange failover is an option some replication vendors provide. It causes a standby Exchange server to go live and then tells Active Directory that all the users’ mailboxes have moved. There are two ways to accomplish this, both of which require some customizations to Exchange and Windows environments. One involves playing some tricks with your DNS so that the standby server takes over the name and IP address of the failed server. This approach has the advantage of being easy on the client workstations since Outlook® thinks it is still using the same server.
The second approach uses a standby server running Exchange that holds copies of the database but has nothing mounted. In a failure, the standby server informs Active Directory that all user mailboxes have been moved to it. Then a script is run, or a Group Policy is distributed, that tells the clients they are on a different mail server. Outlook 2007 is Active Directory-aware, which makes the process easier because it will automatically figure out these mappings on its own.
Local Clustering with MSCS
Higher in the availability continuum is Microsoft Cluster Services (MSCS); Exchange is a cluster-aware application. Clustering shares information between two or more computers so that if one fails, the others can take over. Today most Exchange clusters are two or four nodes, though up to eight nodes can be used. One node is always designated as passive—operational with Windows Server running and Exchange Server installed, but with no active mailboxes. A two-node active/active cluster was possible in Exchange 2003, but due to performance loads, is now discouraged and will not be supported on Exchange 2007.
As with the Exchange 2003 cluster arrangement, the Exchange 2007 clusters that include a passive node can still use a single shared storage array. Though cluster-quality storage arrays typically have a number of redundancy features to withstand many types of failures, they still provide only one copy of the data, which leaves a window of vulnerability open. That’s why these clusters are called single-copy clusters (SCC), to distinguish them from the next frontier in data protection that arrives with multiple-copy clusters (MCC) in Exchange 2007. We will discuss MCCs further when we look at disaster recovery.
Local Continuous Replication
Local Continuous Replication (LCR) is a new feature of Exchange 2007 that provides an improved way of maintaining a second copy of the Exchange databases and transaction logs within the same server. This adds a layer of redundancy to the best practice of having the Exchange database on one RAID array and the transaction logs on another: LCR makes it possible to store a secondary copy of the logs on the array that stores the primary copy of the database, and then store a secondary copy of the database on the array that stores the primary copy of the logs (see Figure 3). If either the RAID controller or the array fails, you still have your database and transaction logs on the other array. In this way, you can continue operating—albeit somewhat nervously and with some performance degradation—until you are able to rebuild your failed array.
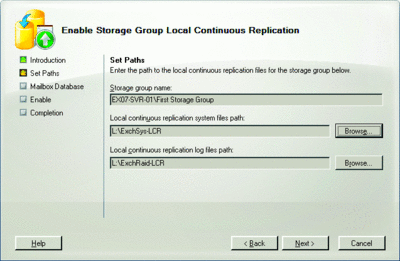
Figure 3** Configuring LCR **
LCR is a local operational continuity solution, not a backup solution, so you will still need a full backup strategy. With LCR, there is also a performance hit because your server will now be making two copies of the database and transaction logs. Furthermore, in the Exchange 2007 implementation, there are some limitations that will make LCR suitable only for smaller organizations because LCR supports only one database in a storage group and only one public folder database in an organization.
Failover using an LCR recovery is not instantaneous—a knowledgeable IT professional will have to run scripts to get Exchange back up. The process requires executing Exchange Management Shell commands that are run outside the Exchange management console.
Where Exchange Server 2003 Enterprise Edition enabled an organization to run up to 20 Exchange databases (four storage groups of up to five databases each), Exchange 2007 Enterprise Edition allows up to 50 storage groups, each with its own database. The transaction logs have also been reduced from 5MB files in Exchange 2003 to 1MB files in Exchange 2007. Both of these changes are designed to support LCR—plus cluster continuous replication (CCR), which will become relevant in a bit.
Small- and medium-size organizations will use LCR in order to provide improved data protection for their Exchange operations. LCR is easy to implement but still involves manual intervention. As a same-server/local-disk solution, LCR is only a first step toward improved operational continuity. While it does protect against failures of a RAID array and RAID controllers, multiple simultaneous disk crashes or RAID controller failures are relatively rare. A majority of the time, failure scenarios involve the collapse of the entire server, which takes us to the next step in Exchange protection.
Third-Party Local Off-Host Replication
To further the recovery capabilities of Exchange, third-party vendors have developed products that take advantage of "off-host" replication using the Exchange log files to keep a standby copy of the Exchange database on another machine. In this case, the data protection or archiving solution performs an ESE full backup of Exchange to a different computer and then pulls transaction logs as soon as Exchange closes them. It inserts those transactions into its Exchange database copy so that it is always up to date. As I’ve noted, these logs are relatively small (5MB in Exchange 2003 and 1MB in Exchange 2007) so that once the full backup is completed, there’s almost no overhead on the Exchange server in copying these log files to the off-host server.
LEVEL 3: DISASTER RECOVERY AND HIGH AVAILABILITY
Disaster recovery is the ability to get back up and running if the major data center becomes unavailable. Exchange merits effective disaster recovery because e-mail and calendar functions are the lifeblood of many organizations today.
Some companies imagine that their traditional tape backups stored offsite are a form of disaster recovery, but if your sole data center is destroyed by fire or flood, a van returning with spools of tape is of little value. Disaster recovery necessarily involves moving not only your data to an alternate location, but also the technology and processes to bring the application back up and running. To be effective, disaster recovery relies on separating primary and secondary systems by some distance. How far apart the sites should be depends on the magnitude of disaster you are concerned with surmounting. If you’re worried about fire, perhaps another building on your campus is sufficiently remote. However, infrastructure disasters involving trains or airplanes could affect a radius of a mile or more. Many disasters are regional: floods, ice storms, earthquakes, and even power outages. Communications can suffer its own calamities—anything from a backhoe that severs the link to your ISP, to denial of service attacks, to Internet DoS attacks aimed at commerce in general.
As a practical matter, if your organization already has more than one site with IT staff, one of those locations might meet your criteria for remote operational continuity, given the types of disasters you are defending against. Using your own facility and staff will be far less expensive than contracting with a disaster recovery provider or renting space in a new location.
Ultimately, disaster recovery is also about perception: giving customers the confidence that you are still in business. People are understanding when a disaster hits a city or area, but if your company is not back online within a couple of days to a week, chances are that customers and suppliers will believe the worst; many companies fail for that reason. To the customer, your operation must look like it is recovering to assure them your business is continuing. Customers will have different ideas regarding timely recovery: they are understandably less patient with outages at their financial services companies than with, say, outages at their suppliers of office furniture.
Disaster Recovery Demands
Being able to get Exchange back online after a disaster requires replicating its data to the secondary site and using replication technology that is prepared to present the data to a warm Exchange server that’s ready to run with it, then notifying the Outlook clients that their mailboxes have moved.
Exchange is a demanding application to replicate, particularly over long distances. As a true transactional database, the order of each write is supremely important. Complicating the challenge, the transport protocol Exchange uses to communicate all transactions and system information between servers is SMTP, a known bandwidth-intensive protocol. Furthermore, with Exchange clusters a heartbeat must be maintained between systems every 500 milliseconds. If a secondary node doesn’t receive that heartbeat, it may trigger the start of a failover.
The complexities of managing such challenges may be why Microsoft is only now entering this space with Exchange 2007. In the absence of a Microsoft entry, several third-party solutions have been developed to replicate Exchange data using host-based or array-based replication.
Vendors realized they could extend a cluster by dispersing nodes to different locations; this is called a stretch cluster. Today, the most common way to implement stretch clusters is through general-purpose third-party data replication products or those specifically geared to stretch an Exchange node. You can do this with MSCS, but the subnet requirement is challenging over a WAN. Clustering and the complexities of provisioning reliable high-bandwidth connectivity to remote data centers understandably increase the cost and staffing requirements to build, maintain and periodically test disaster recovery systems.
Cluster Continuous Replication
Microsoft extends its cluster support with cluster continuous replication in Exchange 2007. CCR extends LCR’s ability to maintain two copies of an Exchange database and transaction logs to implement the same idea on two cluster nodes. Disaster recovery implies geographic separation of primary and secondary systems, and the Microsoft multi-copy-clusters (MCC) won’t be able to span significant distances until Windows Server 2008, formerly code-named "Longhorn," makes stretch clusters possible.
The technology that enables MCC nodes to have separate copies of the data is called majority node set (MNS), which refers to the election process that the two or more nodes conduct to determine which holds the live copy of the data. When there is a failure, the remaining nodes hold a new election to determine which will take over as the new primary processing/data server. Supporting this technical democracy is CCR, which makes sure that each node has an up-to-date database. Exchange 2007 clusters using CCR are limited to two nodes only.
In larger shops, Exchange servers typically configure the local system disk on the server itself and then connect to the Exchange database over a SAN using either SCSI, fiber, or iSCSI disk arrays. With an MCC/MNS cluster, an interesting question is whether high-end Exchange storage will evolve back to using local RAID arrays for each node. If the purpose of an MNS cluster is to enable each node to have its own separate storage, will it still make sense to point each node to a SAN whose main purpose is to provide common storage?
A likely middle-of-the-road MCC/MNS cluster scenario would have the primary node with storage on the SAN, and a secondary cluster node with either local disks or a lower-cost iSCSI SAN. This secondary node could be remote from the primary datacenter, in a location that does not have a SAN infrastructure.
Regardless of how that shakes out, MCC using MNS and CCR are another step up in the hierarchy of redundancy and enhanced availability because multiple computers are able to fail over and the data is replicated on separate storage elements. This is still entirely confined within a single data center until Windows Server 2008 arrives, however. Windows Server 2008 will natively support stretch clusters, enabling nodes in an MNS cluster to be geographically separated as far as desired—provided that the network latency between nodes is reliably less than 500ms. Until then (and beyond), third-party cluster technology can sit on top of Microsoft MNS and CCR to provide the geographic separation needed to stretch clusters to be an effective disaster recovery solution.
Clustering is at the high end of the continuum of disaster recovery, and CCR is properly positioned as a high-availability capability of Exchange. And even though the combination will have cost and staff overhead, it promises to be an exciting top-of-the-line solution for customers who want to operate a homogeneous Microsoft environment.
Third-Party Remote Operational Continuity
There is no doubt that the Microsoft solution and third-party extensions will occupy the very high end of the recovery continuum when it becomes available. Automatic failover within seconds—that’s about as good as it gets. Yet not every company needs that level of availability and business continuity, nor can they afford to invest the hundreds of thousands of dollars necessary to deliver it. For many companies, a reliable solution that fully restores Exchange in minutes will deliver all of the operational continuity that they require.
As an example, Mimosa Systems, Inc. extends the operational continuity within a single datacenter to remote continuity. At a remote location, Mimosa DR maintains a copy of Exchange, keeps it current with the transaction logs shipped from the primary Exchange server, and is always ready to make this live copy available to your standby Exchange server. The remote Exchange server uses standard server hardware and, just like the single-data center implementation, you keep it warmed up and always ready to be activated in the event of a disaster. Should disaster strike, an operator at the remote site initiates the failover and performs the failover including mounting the standby database files, remapping mailboxes and Outlook profiles. It should be noted though that such third-party solutions are subject to the support boundaries defined in the Knowledge Base article "Microsoft support policy for third-party products that modify or extract Exchange database contents".
Wrap-Up
Exchange data protection is available as a continuum of technologies and procedures that can be grouped into three levels based on cost and capabilities. As you begin to think about their requirements for Exchange data protection, you should consider how much downtime your stakeholders are able to tolerate. Greater performance and faster recovery cost more, with high-end options well into six figures. More affordable solutions exist that approach, but don’t quite reach, the highest levels of availability. The choices you make should reflect the true needs of your organization.
Service Pack 1 for Exchange 2007
Currently in beta testing, Service Pack 1 (SP1) for Exchange 2007 is slated to include a number of features that administrators have been missing, including enhancements to OWA, additional GUI capabilities in the Console, and more.
Of particular interest to administrators planning recovery solutions, Exchange 2007 SP1 also includes a third availability solution to complement LCR and CCR: Standby Continuous Replication (SCR). This is a middle-ground approach and Microsoft looks to that sweet spot of greater recoverability, without the complexity of full "high availability."
SCR will allow replication of the Exchange database and transaction logs to a different Exchange server than the one where your mailboxes typically reside. The SCR target can be local or remote, and can be a standby Exchange server or a cluster. However, SCR does not require a cluster in either location and it differs from CCR in that the target is a standby environment and the failover is a manual process. Note that you still need to get that first large copy over the wire—essentially a full backup. You may need to do this large replication from time to time and must be aware of the implications on your network, just as with CCR and third-party solutions. I expect to see significant adoption of both SCR and CCR, and of add-on products that provide similar and sometimes greater capabilities.
Lee Benjamin runs ExchangeGuy Consulting Services where he works directly with customers and advises Microsoft Partners. Lee is chairman of the largest Exchange user group in the world, ExchangeServerBoston, and a director for BostonUserGroups. Lee is also an MVP for Exchange, a Microsoft Certified Trainer, and a regular speaker at industry conferences.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.