SharePoint
Find It All with SharePoint Enterprise Search
Matt Hester
At a Glance:
- Architecture of an enterprise search solution
- Indexing and querying business data
- LOB data and people knowledge
You probably spend a lot of time worrying about things like server uptime and availability, software updates, and security. But even if your infrastructure is running perfectly—every app and
every file available across the network-your users may still be losing productivity. Sure, all the data they need is available, but how long does it take them to find it?
A lot has been done to help people deal with information overload. Desktop search tools have made it easier to find that piece of information hidden among all the other data stored on your system. (See my August 2006 article "Find Anything with Windows Desktop Search". But what about all the data available on portals, stored in shares, and trapped in business applications, let alone the valuable information stored in various employees' heads. This information is vital to your users-they need this data to do their jobs, and they need it quickly for making timely and accurate business decisions. But think about how long it takes one of your users to find and gather data spread across the network. Now think about the potential impact this has on your enterprise's bottom line.
You need to reduce the amount of time it takes your users to track down information stored throughout the enterprise. How can you do this? The answer, quite simply, is by using a search engine that provides enterprise search capabilities.
Enterprise search can find information stored most anywhere in your organization. Whether looking for data stored on the desktop, tucked away on an intranet site, locked in a line of a business (LOB) application, or kept in a person's head, an enterprise search tool can help. (Don't worry, you won't have to implant any chips into your user's brains.)
An enterprise search solution combines desktop search with fast intranet searching capabilities. Ultimately, an enterprise search tool must be able to perform federated searches, ones that can access multiple data sources with a single query. The user has a single interface where he enters the query. However, underneath the covers, the query is sent to several different search engines and then the results are displayed in one aggregated view.
In this article I will discuss how Microsoft® Office SharePoint® Server 2007 (MOSS 2007), the next generation of Microsoft SharePoint solutions, provides a powerful search engine that will help you tear down the silos of information in your organization. MOSS 2007 offers numerous improvements from previous versions, completely redeveloped components, and some brand new features. Here I will discuss some of these key components-such as indexing, propagation, relevancy, and content sources-and how they will help you provide better enterprise search capabilities to your users.
Searching the Enterprise with SharePoint
Enterprise search will be available in four versions with key differences: Microsoft Office SharePoint Server 2007 for Search Standard Edition, Microsoft Office SharePoint Server 2007 for Search Enterprise Edition, Microsoft Office SharePoint Server 2007 Standard, and Microsoft Office SharePoint Server 2007 Enterprise.
The main difference between the two Search Editions and the full SharePoint Server editions is that the two Search Editions do not include the People Search functionality (which also includes the integration with Knowledge Network for MOSS 2007), Business Data Catalog, or the enhanced Search Center with customizable tabs. Figure 1 details the key differences.
Figure 1 Key Differences of the Four Search Offerings
| Microsoft Office SharePoint Server 2007 for Search Standard Edition | Microsoft Office SharePoint Server 2007 for Search Enterprise Edition | Microsoft Office SharePoint Server 2007 Standard Edition | Microsoft Office SharePoint Server 2007 Enterprise Edition | |
| Indexes | 40 file types out of the box (extensible) | 40 file types out of the box (extensible) | 40 file types out of the box (extensible) | 40 file types out of the box (extensible) |
| Supports (out of the box) search on file shares, Web sites, SharePoint sites, Exchange Public Folders, Notes database files | |
|
||
| Supports search on third-party document repositories | ||||
| Supports search for people and Expertise | ||||
| Supports searching on structured data sources | ||||
| Provides secure content access control | ||||
| Provides enhanced Search Center UI | ||||
| Document limit | 400,000 | Unlimited | Unlimited | Unlimited |
The UI offers a number of new features, including "Did you mean?" capabilities. A mainstay for Internet search engines, this advises you when you may have misspelled a common search term (see Figure 2). The interface also includes hit highlighting and full support for "best bets". But this only scratches the surface of the new search capabilities.
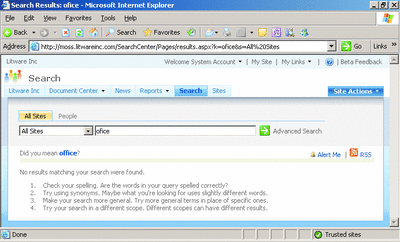
Figure 2** The New 'Did You mean...' Functionality in SharePoint Searches **(Click the image for a larger view)
Finding People Knowledge
One of the most interesting new offerings is the ability to search for people with certain knowledge and expertise. This lets users tap into and leverage the knowledge held by employees throughout the organization-an important step in breaking down the silos.
To enable this, indexing and searching can be performed on any Lightweight Directory Access Protocol (LDAP) directory, including Active Directory® distribution lists and SharePoint user groups. In reality, MOSS doesn't search the LDAP directories directly; to enable people search, the LDAP information needs to be imported into MOSS. (Searches can also be performed across the entire enterprise infrastructure.)
Search results can be grouped according to an individual's "social distance"-this refers to the distance from a user's position (a sales assistant probably won't want to give the CFO a call) and common interests. Figure 3 shows the results from a people search.
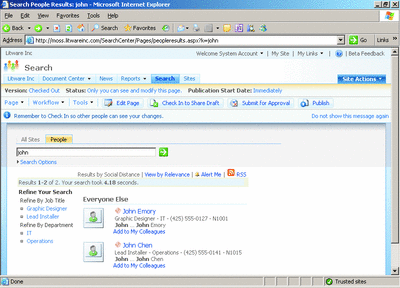
Figure 3** Finding Colleagues with Relevant Knowledge **(Click the image for a larger view)
Searching Business Data
SharePoint can also index various types of business data. This includes line of business applications (such as HR applications, CRM, expense reporting, and so on). Traditionally, this sort of data is hard to access outside of the LOB application's normal interface, making it difficult for the majority of employees to discover and use any of this data.
But now MOSS search can retrieve data from any LOB application, such as a relational database or a Lotus Notes database, that is accessible through ADO.NET or Web services. What's special about this is that it does not require custom code to be written. With the Business Data Catalog feature, getting this business data is as easy as accessing any document or Web site. The Business Data Catalog feature can be simply integrated with the property management and customized scopes offered by the Search Center.
Returning Relevancy
Of course, any number of new features would offer little value if they didn't produce accurate results. Fortunately, MOSS has made some dramatic improvements in relevancy. Before I discuss these improvements, however, it's important that you understand how relevancy in the enterprise differs from relevancy on the Internet.
You may wonder why intranet searches can't just rely on the same tools (and thus the same accuracy) as Internet searches. Simply put, these are two very different environments with very different needs and requirements. These differences can be grouped into three main categories: security, structure, and hierarchy.
Security refers to the simple nature of the Internet versus the enterprise. Data on the Internet is commonly accessible anonymously; indexing and searching does not require authentication or security trimming. An enterprise environment, on the other hand, must adhere to a strict security model, including filtering the results to match the searcher's permissions.
The impact of structure has to do with density. The Internet is very rich and deep, with sites linking to other sites to augment their content. But in the enterprise, links are typically used for navigation, and the structure is much less dense.
Loosely related to link structure is the site hierarchy factor. On the Internet, there is typically no hierarchy to the sites and very few top-level sites. An enterprise's intranets, however, are usually planned out and hierarchical in nature. Even when an enterprise has multiple main root levels, there is usually only one main portal for the organization.
These fundamental differences change the way in which an enterprise search solution indexes data and returns results. MOSS 2007 aims to better meet the different needs of the enterprise. It features a new ranking engine, which was developed using existing technology combined with work from Microsoft Research and the MSN® team. Relevancy was increased through the creation of a series of relevance algorithms, which gather both internal and external information about the documents and line of business data being crawled. When enterprise data is indexed, over 200 document types are scanned and algorithms are applied to detect language, extract metadata, and perform text analysis. These new algorithms, which are tuned specifically to meet the needs of enterprise data and LOB applications, dramatically improve the accuracy of results.
Several metadata tags are included in the relevancy calculations. Here are a few of the things considered:
- Click Distance Browsing distance from authoritative sites (shorter distances tend to be more relevant).
- Anchor Text Hyperlinks act as annotations on their target. In addition, they tend to be highly descriptive.
- URL Depth URLs higher in the hierarchy tend to be more relevant.
- URL Matching Direct matches on text that's in URLs.
- Metadata Extraction Automatically extracts titles and authors from document text if they are missing.
- Automatic Language Detection Helps create preference for results in your language.
- File Type Biasing Certain file types tend to be more relevant (for example, PPT files are often more relevant than XLS files).
- Text Analysis Traditional text ranking based on such factors as matching terms, term frequencies, and word variants.
How Does the Indexing Work?
MOSS 2007 has made important improvements in how the indexing service works and how content is managed. For starters, you can specify if the content sources are SharePoint servers, Web sites, file shares, Exchange Public Folders, Lotus Notes databases, or LOB apps. The overall indexing administrative experience has been streamlined, letting you freely choose what, how, and when to index across multiple content sources. This is handled through crawling rules, which let you specify paths to be included or excluded. You can even configure how the crawler follows the links of the URL. A built-in log gives a comprehensive view of the number of sites crawled and how they were indexed.
The index is similar to the index technology used in Windows® Desktop Search. Two main components make up the index: a content index and a properties store. This is an extremely efficient way to process the data. The content index includes the actual text contained in files as well as an associated inverted index of words that are in your enterprise index. The property store database is critical to processing the results. The property store database holds all the additional metadata properties (author, date created, document type, and so on) about all the documents in the store. Structurally, the property store consists of a table of properties and their values. Each row in the table corresponds to a separate document in the full-text index. The property store also maintains and enforces document-level security that is gathered when a document is indexed.
The indexing and storage process starts with the index engine, which is responsible for crawling the content source. The engine begins crawling after it has verified it has an appropriate protocol handler to read the content sources. Once the correct protocol handler for the content source has been loaded, the protocol handler and the necessary IFilters extract and filter the items from the content source. An IFilter is an add-in that enables the index engine to open, read, and index the contents of new file types it would not otherwise be able to fully index. IFilters extract the text and the metadata for each document and then pass the stream back to the index engine.
The document properties are then stored in the properties store, and the actual text of the document is placed in the content index. But just before that happens, the index engine removes "noise" words. The engine also processes the information using wordbreakers and stemmers to streamline the data, enabling better query execution. (Wordbreakers break the text into words and phrases. Stemmers generate inflected forms of a given word.)
The index engine uses continuous propagation, which allows the index to be built almost immediately. With continuous propagation, the index continues to be built even as the crawling process moves through the content sources. This enhancement allows for near immediate results-a dramatic improvement over SharePoint Portal Sever 2003, in which large content crawls could take days, and the index was only propagated when the crawl was completed.
How Does Querying Work?
When a user inputs a query or a custom application calls the index, the query engine begins processing the request. It first passes the query into a language-specific wordbreaker. If the language cannot be identified, a neutral wordbreaker is invoked. After the query is broken down, the engine passes the information to a stemmer (if stemming is enabled) for further processing. This two-step process improves the relevance and effectiveness of the results returned by the query.
If the query specifies property information, the content index is checked first for matches paired with documents in the property store, and then the properties in the query are checked again to ensure a match. The query engine does an additional level of filtering to remove results that the user does not have permission to access. The matching results are returned in a list, ordered according to relevance. Figure 4 outlines how all the components of indexing and querying fit together.
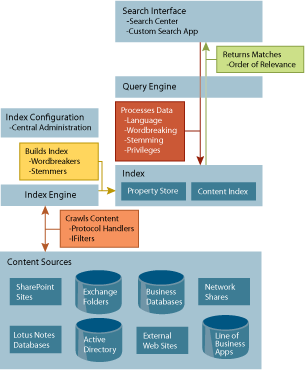
Figure 4** Architecture of the MOSS 2007 Enterprise Search Environment **(Click the image for a larger view)
Enhanced Management
Administrators will find it easier to manage the search environment. An improved set of common tools for end users and administrators help to reduce the complexity introduced by the different connection points into the platform. And the search engine benefits greatly from the new management model in MOSS 2007. (Figure 5 shows the main page used for modifying search settings.)
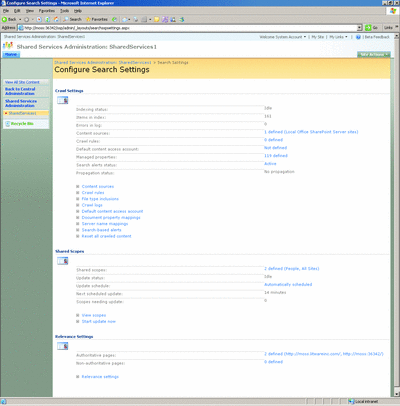
Figure 5** Configuring Search Settings **(Click the image for a larger view)
Scopes, which allow you to control the different search capabilities, have also been improved. Scopes let you easily search within a content source, essentially allowing you to manage the index in smaller chunks. In SharePoint Portal Server 2003, scopes are connected to the content sources, making them less flexible and somewhat challenging to manage. In MOSS 2007, scopes are separate from content sources, offering a greater degree of flexibility. You can define scopes based on arbitrary content properties such as URL, type, or author. You can even combine scopes to have multiple rules, for example, all technical documents by a specific author.
Of course, if an administrator wants to improve the performance of the search engine, one of the most important things they can do is understand the current usage of the index. One of best new additions to the administrative toolset is query reporting. Out of the box query reporting functionality lets you quickly find information about query volume trends, top queries, click-through rates, queries with zero results, and so on. The query reporting can provide details at site level and the core service provider levels. Figure 6 shows a sample report. You can export the information to Microsoft Excel® for further analysis and for pivoting on the data.
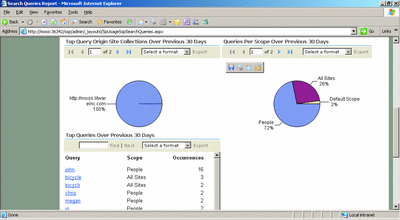
Figure 6** Query Report in MOSS 2007 **(Click the image for a larger view)
Security and Privileges
As I mentioned earlier, the query engine filters out results so the list that the user sees only includes documents that the user has permission to access. (In SharePoint Portal Server 2003, the user is presented with links that he might not have proper permissions to follow.) One caveat regarding security trimming is that MOSS 2007 does not security trim Web crawls. You cannot trim the Web sites due to the fact that the HTTP protocol has no way to read back the access control info. Additionally MOSS 2007 doesn't let you security trim the Business Data Catalog or People searches.
MOSS 2007 respects the existing access control lists (ACLs), ensuring the security of documents in the index. This is a major differentiator from several other search tools. Unlike some search engines, which require you to use a config file to set permissions on files manually, MOSS 2007 allows you to keep in sync with current permissions.
The index can quickly reflect changes in the ACL for a single document. Say, for example, there is an Excel spreadsheet currently stored in the index and the ACL for the document is changed to be restrictive. An administrator can reindex and crawl just that one document and the security trimming will happen immediately (and, if necessary, the document can be completely removed from the index).
In addition, individual documents can be assigned unique permissions or be set to inherit the permission settings from a document library or parent directory. This makes the process of selecting the groups or individuals that are allowed to view, edit, and save documents much more straightforward.
There have also been enhancements to authentication and sign-on management. The secure credential cache is now extensible, making it possible for MOSS to accept single sign-on credential caching systems from third-party sources and custom-coded add-ons. In addition, the core authentication can now accept third-party systems. These two enhancements build on the new ASP.NET provider model, which allows the use of other directory services.
Customization
In MOSS 2007, you have a number of options for modifying the user interface. The UI can be customized with many of the tools you already use to modify Web sites. There are also new tools, such as the Office SharePoint Designer, which helps you build Master Pages (offering an easy way to build a branded site). Figure 7 shows a search results page being edited.
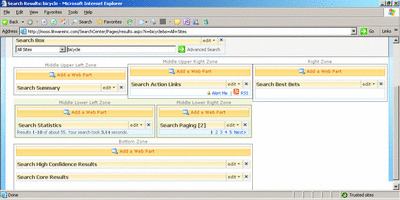
Figure 7** Customizing the Look of a Search Results Page **(Click the image for a larger view)
Out of the box, MOSS 2007 provides two tabs for the Search Center interface: All Sites and People. You can simply add additional tabs that reflect the different types of information your users search on most frequently. For example, you can provide a direct entry into any of your enterprise applications, databases, or even directory services. You can even correlate these tabs to scopes. This is handy for creating contextualized search tabs on specific content. Note that the search-only editions do not support this customization of the search tabs.
Wrap-Up
As you've seen, MOSS 2007 provides some pretty compelling new enhancements to enterprise search functionality, allowing your users to be more efficient and more productive. For more info, see Microsoft Office SharePoint Server TechCenter.
Matt Hester is a TechNet presenter on the Microsoft Across America team. To see him present live, please visit www.technetevents.com/mhester. Check out his blog at blogs.technet.com/matthewms.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.