SQL Server 2008
Data Warehouse Query Performance
Sunil Agarwal and Torsten Grabs and Dr. Joachim Hammer
At a Glance:
- Star join query optimization
- Partitioned table parallelism
- ROW and PAGE compression
- Partition-aligned indexed views
SQL Server 2008 will offer much more powerful relational data warehousing capabilities than its predecessor, but you may still be wondering how you can use all this new technology to build a well-performing data warehouse for decision support over billions of rows. Or you
may want to know which features are going to help you achieve the best query performance for your decision-support queries and reports, or what sort of performance improvements you can realistically expect with this new version of SQL Server®.
There are certainly a lot of questions that come up as we get closer to the actual release. We hope this deep-dive look into some of the most important performance-related data warehousing features in SQL Server 2008 can help you get ready.
Logical Database Design: Dimensional Modeling
Transactional line-of-business applications usually have a normalized database schema. Logical database schema design for relational data warehouses puts less emphasis on normalization. Many relational data warehouse designs today follow a dimensional modeling approach, which was made popular by Ralph Kimball and Margy Ross in their book, The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling.
If you spend a lot of time dealing with data warehousing, you're probably already familiar with common schema patterns for relational data warehouses (such as star and snowflake schemas). Dimensional modeling distinguishes dimension tables from fact tables. Your dimension tables are what holds your master data (such as products, customers, stores, or countries) while your fact table stores transactional data (such as sales, orders, purchases, or returns).
Dimension tables and fact tables are linked by primary key (PK)/foreign key (FK) relationships. You'll find that many data warehouses don't enforce the FK constraints as a way to keep storage requirements small. This saves the storage overhead of the underlying indexes and keeps the maintenance cost of the fact table low. Dimension tables in a data warehouse are usually fairly small—they typically hold thousands or up to several million rows. The fact table, on the other hand, can be very large, holding hundreds of millions to billions of rows. Thus, logical design really needs to pay close attention to storage requirements of the fact table.
This size factor also has implications in determining what key you should choose from a dimension table to maintain the fact table/dimension table relationships. Composite keys based on the business key of the dimension—meaning the real-world identifier of the entity represented by the dimension—commonly cover several columns. You should know that this is an issue for the corresponding foreign key in the fact table since the multi-column composite key will be repeated for each fact table row.
In response to this, a common practice is to use small surrogate keys to implement the relationships between a fact table and its dimensions. The surrogate key is an integer-typed identity column that serves as an artificial primary key of the dimension table. With the fact table referring to the smaller surrogate key, there is a significant reduction in storage requirements for large fact tables. Figure 1 illustrates a dimensionally modeled data warehouse schema using dimension and fact tables with surrogate keys.
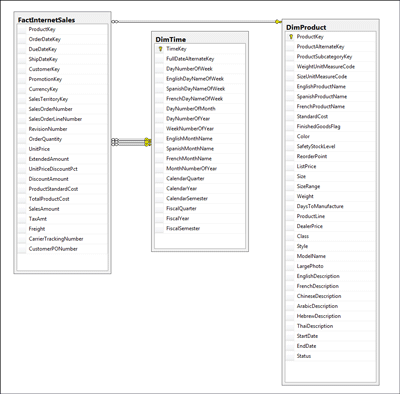
Figure 1** Star schema example with a fact table and two dimension tables **(Click the image for a larger view)
The snowflake schema design spreads one or several dimensions over multiple levels (for instance, customer, country, and region for a customer dimension), thereby normalizing larger dimensions that may suffer from excessive redundancies in data. The levels are represented by separate tables, giving the schema the form of a snowflake. The star schema design, on the other hand, does not spread any of its dimensions over tables. A star schema has the form of a star where the dimension tables are grouped around the fact table in the center.
With dimensionally modeled star schemas or snowflake schemas, decision support queries follow a typical pattern: the query selects several measures of interest from the fact table, joins the fact rows with one or several dimensions along the surrogate keys, places filter predicates on the business columns of the dimension tables, groups by one or several business columns, and aggregates the measures retrieved from the fact table over a period of time. The following demonstrates this pattern, which is also sometimes referred to as a star join query:
select ProductAlternateKey, CalendarYear,sum(SalesAmount) from FactInternetSales Fact join DimTime on Fact.OrderDateKey = TimeKey join DimProduct on DimProduct.ProductKey = Fact.ProductKey where CalendarYear between 2003 and 2004 and ProductAlternateKey like 'BK%' group by ProductAlternateKey,CalendarYear
Physical Design
Many SQL queries in your relational data warehouse will follow the structure of the star join query. Nevertheless, decision support queries usually vary over time because decision makers continuously attempt to better understand their fundamental business data in new ways. So that is why workloads for data warehouses tend to have a high ratio of ad hoc queries. This makes physical design for decision support queries and a dimensionally modeled data warehouse schema challenging.
With SQL Server, data warehouse designers usually start with a blueprint or physical design that they tune and refine over time as workloads evolve. You should feel free to adopt and vary this blueprint for your own data warehouse environment. If you do so, keep in mind, of course, the best practices for database physical design, such as the performance impact caused by index maintenance for updates and storage requirements for the indexes.
The Fact Table
The blueprint design aims to anticipate the typical star query shape and builds indexes over the fact table. The clustered index of the fact table uses several dimension surrogate key columns (the foreign key columns) as index keys. The most frequently used columns should occur in the list of index keys. You may want to take the time to verify that this indeed provides a good access path for the most frequently executed queries in your workload.
In addition, the blueprint creates a single-column non-clustered index for each dimension surrogate (foreign key) column in the fact table. This provides a highly efficient access path for queries that are very selective in one of their dimensions.
The goal of the clustered index is to provide good performance for the majority of the queries in your workload. The set of non-clustered indexes targets queries that retrieve fact table measures for a specific customer or product. These non-clustered indexes ensure that you do not, for example, have to scan the fact table in order to retrieve sales data for a single customer.
Dimension Tables
When you apply the blueprint design to dimension tables, you need to create indexes for each dimension table. These include a non-clustered primary key constraint index on the surrogate key column of the dimension and a clustered index over the columns of the business key of the dimension entity. For large dimension tables, you should also consider adding non-clustered indexes over columns that are frequently used in highly selective predicates.
The clustered index facilitates efficient Extract, Transform, and Load (ETL) during the maintenance window of the data warehouse, which is often a time-critical process. With slowly changing dimensions, for example, existing rows are updated in place while rows not yet present in the dimension are appended to the dimension table. To be successful, this access pattern requires well-performing lookup and updating for the dimension table at the time of ETL.
The blueprint design we outlined serves as a good starting point for physical designs in relational data warehouses built with SQL Server. Based on this typical relational data warehouse setup, we can explore key new features in SQL Server 2008.
Star Join Query Optimization
Processing the fact table is usually the biggest cost of executing a star join query in a dimensionally modeled relational data warehouse. This is easy to see because even highly selective queries retrieve an order of magnitude more rows from the fact table than from any dimension. Therefore, using the best access path into the fact table is essential for good query performance.
With SQL Server, the query optimizer automatically chooses the access path with the lowest estimated cost from a set of alternatives. In the context of data warehousing, the main objective is to make sure the query optimizer considers the compelling alternatives of access paths for the execution plan of the star join query. SQL Server includes various functionalities in its query optimizer to automatically provide well-performing star join query execution plans.
You can think of star join queries as being divided among three different classes, as depicted in Figure 2. These broad classes also help the SQL Server engine to identify proper plan choices for those queries. The main concept SQL Server relies on is the selectivity of those queries against the fact table. A query is considered more selective with the fewer rows it consumes from the fact table. The percentage of rows retrieved from the fact table is used to provide the intuition of those query classes. These percentages represent values from typical customer deployments, but they are not strict boundaries used to generate access path definitions.
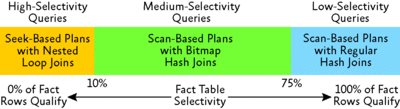
Figure 2** Selectivity ranges for star join queries **(Click the image for a larger view)
The first class covers highly selective queries, which process up to 10 percent of the rows in the fact table. The second class, with medium selectivity, consists of queries that process more than 10 percent and up to 75 percent of the fact table rows. Queries in the third class, with low selectivity, require processing of more than 75 percent of the rows stored in the fact table. The boxes in the figure also highlight the basic query execution plan choices within each selectivity class.
Plan Choice Based on Selectivity
Since high-selectivity star queries usually retrieve not more than 10 percent of the fact table rows, those queries can afford random access into the fact table. Hence, query plans for that class rely heavily on nested loop joins in combination with (non-clustered) index seeks and bookmark lookups into the fact table. As these perform random I/O into the fact table, they are outperformed by sequential I/O once we need to retrieve larger portions of the fact table. This motivates different query plans as the number of rows from the fact table increases beyond a certain number.
Since medium-selectivity star queries process a significant fraction of the rows in the fact table, hash joins with fact table scans or fact table range scans are usually the preferred choice of access path into the fact table. SQL Server uses bitmap filters to improve the performance of these hash joins.
Figure 3 illustrates how SQL Server uses these bitmap filters to improve performance of joining during star join query execution. The figure shows a plan for a query against two dimension tables, Product and Time, that join with the fact table along their surrogate keys. The query uses filter predicates, such as WHERE clauses, against both dimension tables such that only one row qualifies for each dimension. This is indicated by the little red tables next to the two join operators.
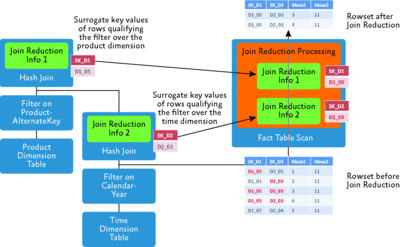
Figure 3** Star join query plan with join reduction processing **(Click the image for a larger view)
The join implementation for each join is a hash join, which allows SQL Server to consume the information about qualifying rows from the dimension tables into what we call join reduction information for both dimension tables. The green boxes in the figure represent join reduction information data structures. Once populated from the underlying dimension tables, SQL Server moves these data structures automatically during query execution to the operator that processes the fact table, such as a table scan. This operator utilizes the information about dimension table rows to eliminate fact table rows that will not qualify for the join conditions against the dimensions.
SQL Server prunes these fact table rows very early during query processing—after retrieving the row from the fact table. This enables CPU savings and potential disk I/O savings since the pruned rows don't need to be processed within further operators of the query plan. SQL Server uses a bitmap representation to efficiently implement the join reduction information data structures at query execution time.
Star Join Optimization Pipeline
The optimization process employs standard heuristics for join query optimization to generate an initial set of query execution plan alternatives. Special purpose extensions are then invoked to generate additional query plan alternatives.
In the case of data warehousing, the extension detects star schemas, snowflake schemas, and the star query patterns, and it estimates the selectivity of the query against the fact table. If the schema and the query shape match the patterns, SQL Server automatically adds further query plans to the plan space, which is then covered by cost-based optimization to choose the most promising query plan for execution.
At query execution time, SQL Server also monitors actual selectivity of the join reduction at run time. If selectivity changes, SQL Server rearranges the join reduction information data structures dynamically so the most selective one is applied first.
Star Join Heuristics
Many physical designs for data warehouses follow the star schema but do not completely specify the relationships between the fact and dimension tables, as mentioned earlier for foreign key constraints, for instance. Without the foreign key constraints explicitly specified, SQL Server must depend on heuristics to detect star schema query patterns. The following heuristics are applied to detect star join query patterns:
- The largest of the tables participating in the n-ary join is considered the fact table. There are additional restrictions on the minimum size of the fact table. For instance, if even the largest table is not beyond a specific size, the n-ary join is not considered a star join.
- All join conditions of the binary joins in a star join query have to be single column equality predicates. The joins have to be inner joins. While this might sound restrictive, it covers the vast majority of joins between the fact table and dimension tables on the surrogate key in typical star schemas. If a join has a more complex join condition that doesn't fit the pattern described above, the join is excluded from the star join. A five-way join, for example, can lead to a three-way star join (with two additional joins later on), if two of the joins have more complex join predicates.
Note that these are heuristic rules. There are few real circumstances that will lead the heuristics to pick a dimension table as the fact table. This influences the plan choice but has no impact on the correctness of the selected plan. The binary joins involved in a star join are then ordered by decreasing selectivity. Join selectivity in this context is defined as a ratio of input cardinality of the fact table and result cardinality of the join—the join selectivity indicates how much a specific dimension reduces the cardinality of a fact table. As a general rule, we want to consider joins with higher selectivity first.
The query processor in SQL Server applies the optimization automatically to queries following the star join pattern and the aforementioned conditions when the resulting query plans have attractive estimated query costs. Thus, you do not need to make any changes to your application for it to benefit from this significant performance improvement. Note, though, that some of the star join optimizations such as join reduction are available only in SQL Server Enterprise Edition.
Star Join Performance Results
As part of the development effort for the star join optimization in SQL Server 2008, we performed a number of performance studies based on benchmark and real customer workloads. It's worth looking at the results from three of these workloads.
Microsoft Sales Organization Data Warehouse This workload tracks performance for a data warehouse that is used internally for decision support in the sales organization at Microsoft. We took a sample snapshot of the database with a size of about 750GB (including indexes). Queries in this workload are challenging for query processing, as many of them have more than 10 joins.
Retail Customer This series of experiments is based on a data warehousing customer in the retail business (with both a conventional store and online presence). The customer is characterized by a dimensionally modeled snowflake schema and canonical star join queries. We used about 100GB of raw data to populate a snapshot of the warehouse for our experiments.
Decision Support Workload This series of experiments investigates performance of a decision support workload on a 100GB dimensionally modeled database. Figure 4 shows the results for these three workloads. The figure plots normalized geometric means of query response time over all queries in the workload. This metric is a good indicator of what query performance is expected to be when running an arbitrary query from the workload. The bars in the figure compare the baseline performance (1.0) when not using the star join optimization against star join-optimized performance. All these runs were performed with SQL Server 2008.
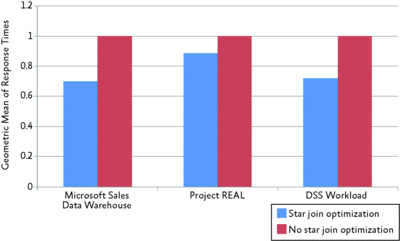
Figure 4** Performance improvements with star join optimization **(Click the image for a larger view)
As the figure shows, all workloads improve significantly, by 12 up to 30 percent. While your individual mileage will vary, we expect decision support workloads against the SQL Server Engine to improve by approximately 15–20 percent based on the extension of the star join-specific optimizations that are new in SQL Server 2008.
Partitioned Table Parallelism
To speed up query processing in large data warehouses, database administrators often partition large fact tables by date. This places the data onto different filegroups, reducing the amount of data that must be searched when processing rows within a specific data range and also making use of the concurrent performance of the underlying disk system when the filegroups are deployed over a large number of physical disks.
SQL Server 2005 introduced the ability to partition a large relation into smaller logical chunks to improve the administration and management of large tables. It has also been used successfully to improve query processing, especially when it comes to large decision-support applications.
Unfortunately, some customers using SQL Server 2005 have observed performance problems associated with queries on these partitioned tables—in particular, when running on parallel shared memory multiprocessor machines. When processing parallel queries on partitioned tables in SQL Server 2005, there may be instances when only a subset of the available threads is assigned to execute the query.
Think of a 64-core machine where queries could use up to 64 threads in parallel, and a query touches two partitions. With SQL Server 2005, it only receives 2 of the 64 threads and therefore might use only 2/64 (3.1 percent) of the CPU power of the machine. It has been reported that for some queries, performance in the partitioned case could be 10 or more times worse than when the same query is run on the same machine on a non-partitioned version of the same fact table.
We should note that SQL Server 2005 was specifically optimized for queries touching a single partition. In this case, the query processor will assign all available threads to perform the scan. This special optimization resulted in a significant performance boost for single-partition queries executing on multi-core machines, and it was only natural for customers to expect this behavior for queries touching multiple partitions.
The new partitioned table parallelism (PTP) feature in SQL Server 2008 improves query performance in the partitioned case by better utilizing the processing power of the existing hardware regardless of how many partitions a query touches or the relative size of individual partitions. In a typical data warehouse scenario with a partitioned fact table, users may see a significant improvement for queries executing on parallel plans, especially if the number of available processor cores is larger than the number of partitions affected by the query. And this new feature works out of the box without any tuning or configuration.
Say we have a fact table representing sales data organized by sales date across four partitions. The diagram in Figure 5 will help you visualize this example. Note that instead of a single clustered index for the entire date range, as in the non-partitioned case, there is typically a clustered index on the date column for each partition of the fact table. Now assume that query Q summarizes sales for the last seven days. As new sales data continuously enters the fact table through the last partition (labeled P4), the query will likely touch different partitions depending on when it is executed. This is illustrated in the first row of the diagram by how the Q1 query touches just a single partition while the Q2 query touches two partitions since the relevant data at the time of execution spans across the P3 and P4 partitions.
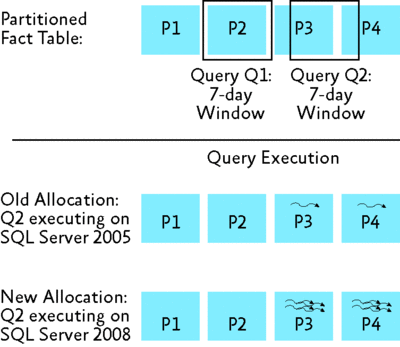
Figure 5** The new PTP feature at work **(Click the image for a larger view)
Now assume that there are eight threads available. Executing Q1 and Q2 on SQL Server 2005 may generate some unexpected behavior. SQL Server 2005 has an optimization by which if the optimizer knows at compile time that only one partition will be touched by the query, that partition will be treated like a single non-partitioned table and a plan will be generated that accesses the table with all available threads.
The result is that Q1 involving a single partition (P3) will result in a plan that is processed by eight threads (not shown). In the case of Q2, which touches two partitions, the executor assigns a single thread to each partition even if the underlying hardware has additional threads available. Thus, Q2 will only utilize a very small fraction of the available CPU power and most likely execute significantly slower than Q1.
Execution of Q1 and Q2 on SQL Server 2008 results in better utilization of the available hardware and better performance and more predictable behavior. In the case of Q1, the executor again assigns all eight available threads to process data in P2 (not shown). Q2, meanwhile, will result in a parallel plan in which the executor assigns all available threads to both P3 and P4 round-robin style, producing the effect illustrated in the bottom row of the diagram where each of the two partitions receive four threads. The CPU remains fully utilized and performance of Q1 and Q2 are comparable.
This round-robin allocation of threads enables queries to perform increasingly better with the more processor cores there are compared to the number of partitions that are accessed by the query. Unfortunately, though, there are cases in which the allocation of threads to partitions is not as straightforward as in this example.
The performance gains from SQL Server 2005 to SQL Server 2008 for the partitioned table scenario on a multicore processor machine are further illustrated in Figure 6. This anecdotal graph highlights scan performance for partitioned tables. For this particular test, which was conducted on a system with 64 cores and 256GB of RAM, we partitioned a single table of 121GB into 11 partitions of 11GB each. For the set of tests depicted in this figure, we used a heap file organization with both cold and warm buffer starts. All the queries perform simple scans against the data.
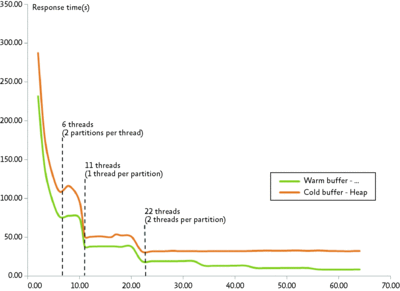
Figure 6** Scan performance for SQL Server with new PTP feature enabled **(Click the image for a larger view)
The y-axis shows response time (sec) and the x-axis indicates the degree of parallelism (DOP), which is analogous to the number of threads that are assigned to the query. As you can see, in both the cold and warm start cases, response times continue to decrease until DOP reaches 22. At this point, the I/O system becomes saturated for the cold start case. This is due to the fact that the query used in this example is I/O-bound. For more CPU-bound workloads, this limitation may not exist or may occur only at higher DOPs.
The curve representing the warm start case, however, continues to show decreases in response time as DOP levels increase. On SQL Server 2005, both curves would start to level off at around DOP 11 since the number of threads per partition would be limited to 1 when dealing with multiple partitions.
It is important to point out that, in practice, the gain in response times for increasing numbers of DOP is never linear. Rather, the expected behavior resembles more that of a step function—this reflects the reality that the query essentially waits on the slowest subpart. So, for example, simply adding one more thread to a scan is not going to improve the finish time of a query until all remaining scans have received additional threads allowing them to also finish faster.
We have performed additional experiments to test the new PTP behavior for various other hardware and file configurations. In doing so, we observed a similar behavior in terms of scaling of throughput as the DOP increases beyond one thread/partition.
Last, but not least, the new PTP feature in SQL Server 2008 also improves the readability of query plans and allows for better insight into the execution of certain workloads. For example, as part of the PTP feature, the way in which parallel and serial plans are represented in showplan XML has been improved and the partitioning information that is provided in both compile-time and runtime execution plans has been enhanced.
Data Compression
As businesses intelligence becomes increasingly common, businesses are pouring more and more data into their data warehouses for analysis. The result is an exponential growth in the size of the data being managed. In 1995, the first Winter Corporation survey of database size reported that the largest system in the world contained a terabyte of data. Ten years later, the biggest database was around 100 times larger. The more astounding fact is that the size of data warehouses is tripling every two years. This creates new challenges in terms of managing such large amounts of data and providing acceptable levels of performance for data warehouse queries. These queries are typically complex, involving many joins and aggregates, and they access large amounts of data. And it is not uncommon for many queries in the workload to be I/O-bound.
Native data compression aims to address this issue. SQL Server 2005 SP2 introduced a new variable length storage format, the vardecimal storage format, for decimal and numeric data. This new storage format can reduce the size of your databases significantly. The space-savings, in turn, can help improve the performance of I/O-bound queries in two ways. First, there are fewer pages to read, and second, since the data is kept as compressed in the buffer pool, it improves the page life expectancy (in other words, it improves the odds that the requested page will be found in the buffer). Of course, the space savings achieved from data compression do have a CPU cost due to the process of compressing and uncompressing data.
SQL Server 2008 builds on the vardecimal storage format, providing two kinds of compression: ROW compression and PAGE compression. ROW compression extends the vardecimal storage format by storing all fixed-length data types in a variable length storage format.
Some examples of fixed-length data types are integer, char, and float data types. Even though SQL Server stores these data types in variable length format, the semantics of the data types will remain unchanged (a data type is still the fixed-length data type from the perspective of the application). So this means that you can get the benefits of data compression without requiring any changes in your applications.
PAGE compression minimizes the data redundancy in columns in one or more rows on a given page. It uses a proprietary implementation of the LZ78 (Lempel-Ziv) algorithm, storing the redundant data only once on the page and then referencing it from the multiple columns. Note that when you use PAGE compression, ROW compression is actually also included.
The ROW and PAGE compression can be enabled on a table or an index or on one or more partitions for the partitioned tables and indexes. This gives you complete flexibility over choosing tables, indexes, and partitions for compression, allowing you to strike the right balance between space savings and CPU impact. Figure 7 illustrates this with a sales table that is partitioned in different ways with aligned indexes.
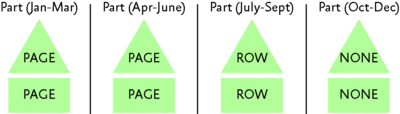
Figure 7** Partitioned table with different compression settings **(Click the image for a larger view)
Each partition represents a quarter, with Oct-Dec being the latest quarter. Suppose the first two partitions aren't accessed frequently, the third partition is moderately active, and the last partition is the most active. In this case, one possible configuration is to enable PAGE compression on the first two partitions to get the maximum space savings with minimal impact on the workload performance, ROW compression on the third partition, and no compression on the last one.
You can enable compression, either online or offline, using Alter Table or Alter Index Data Definition Language (DDL) statements. SQL Server also provides a stored procedure to estimate the space savings. The space savings that you achieve will depend on the data distribution and the schema of the object being compressed.
Based on results seen from testing with many customer databases, it looks like most customers will be able to reduce the size of their database by 50–65 percent and improve the performance of their I/O-bound queries significantly. However, estimating the impact on the performance of CPU-bound queries is a bit trickier and depends on the complexity of the query. In SQL Server, the cost of decompression is only incurred when accessing the index or tables. If the relative CPU cost of scan operators is low compared to the overall CPU cost of the query, as is typically the case in the data warehouse scenario, you should see less than 20-30 percent impact on the CPU utilization.
Partition-Aligned Indexed Views
In SQL Server 2008, partition-aligned indexed views allow you to create and manage summary aggregates in your relational data warehouse more efficiently and use them in scenarios where you couldn't effectively use them before. This improves query performance. In a typical scenario, you have a fact table that is partitioned by date. Indexed views (or summary aggregates) are defined on this table to help speed up queries. When you switch in a new table partition, the matching partitions of the partition-aligned indexed views defined on the partitioned table switch, too, and do so automatically.
This is a significant improvement over SQL Server 2005, where you must drop any indexed views defined on a partitioned table before using the ALTER TABLE SWITCH operation to switch a partition in or out. The partition-aligned indexed views feature in SQL Server 2008 gives you the benefits of indexed views on large partitioned tables while avoiding the cost of rebuilding aggregates on an entire partitioned table. These benefits include automatic maintenance of aggregates and indexed view matching.
Partition-Level Lock Escalation
SQL Server supports range partitioning, which allows you to partition data for manageability or to group the data according to its usage pattern. So, for example, the sales data can be partitioned on a monthly or quarterly boundary. You can map a partition to its own filegroup and in turn map the filegroup to a group of files. This offers two key benefits. First, you can back up and restore a partition as an independent unit. Second, you can map a filegroup to either slow or fast I/O subsystem depending on the usage pattern or the query load.
An interesting point here is the access pattern of the data. The queries and DML operations may only need to access or manipulate a subset of partitions. So if you are, for instance, analyzing the sales data for 2004, you only need to access the relevant partitions and, ideally, you should not be affected, except for system resources by the queries concurrently accessing data in other partitions. In SQL Server 2005, the concurrent access of data in other partitions can lead to a table lock that can impact access to other partitions.
To minimize this interference, SQL Server 2008 introduces a table-level option to control lock escalation at partition or table level. By default, the lock escalation is enabled at the table level, as is the case in SQL Server 2005. However, you can override the lock escalation policy for the table. So, for example, you can set lock escalation as follows:
Alter table <mytable> set (LOCK_ESCALATION = AUTO)
This command instructs SQL Server to choose the lock escalation granularity that is right for the table schema. If the table is not partitioned, the lock escalation is at TABLE level. If the table is partitioned, then the lock escalation granularity is at the partition level. This option is also used as a hint by SQL Server to disfavor locking granularity at the table level.
Wrapping Up
This is just a brief overview of the enhanced features that are to be found in SQL Server 2008 that will help you to achieve better performance for decision support queries over relational data warehouses. But keep in mind that while competitive response times for your decision support queries is essential, there are other key requirements that are beyond the scope of this article.
Some additional functionality that is related to relational data warehousing includes the following:
- Support for the MERGE syntax in T-SQL to update, delete, or insert (dimension) data with one statement and round-trip into the database.
- Optimized logging performance of the SQL Server engine to allow for more efficient ETL.
- Grouping sets to facilitate writing aggregate decision support queries in T-SQL.
- Backup compression to reduce the I/O requirements for both full and incremental backups.
- Resource governance to control system resource allocation to different workloads.
We encourage you to check out more detailed information about all those exciting features on the SQL Server Web page, available at microsoft.com/sql.
We'd like to thank Boris Baryshnikov, Prem Mehra, Peter Zabback, and Shin Zhang for providing their technical expertise.
Sunil Agarwal is a Senior Program Manager in the SQL Server Storage Engine Group at Microsoft. He is responsible for concurrency, indexes, tempdb, LOBS, supportability, and bulk import/export.
Torsten Grabs is the Senior Program Manager Lead for the Core Storage Engine in the Microsoft SQL Server team. He holds a PhD in database systems and has 10 years of experience working with SQL Server.
Dr. Joachim Hammer is a Program Manager in the Query Processing group at Microsoft. He specializes in query optimization for large-scale data warehouse applications as well as in distributed querying, ETL, and information integration.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.