SQL Server
Minimize Blocking in SQL Server
Cherié Warren
At a Glance:
- Why lock escalation occurs
- Avoiding unnecessary blocking
- Optimizing your queries
- Monitoring the impact of locking on performance
Locking is necessary to support concurrent read and write activities on a database, but blocking can adversely affect system performance, sometimes in subtle ways. In this article, I'll take a look at how to optimize your SQL Server 2005 or SQL Server 2008 database in order to minimize
blocking, as well as how to monitor the system so you can better understand how locking impacts performance.
Locking and Escalation
SQL Server® chooses the most appropriate grain of lock, based on how many records are affected and what concurrent activity exists on the system. By default, SQL Server selects the smallest grain of lock it can, only choosing coarser-grained locks if it can more efficiently make use of the system memory. SQL Server will escalate a lock if the escalation will benefit overall system performance. As Figure 1 shows, escalations will occur when the number of locks in a particular scan exceeds 5,000 or when memory used for locks by the system exceeds the available capacity:
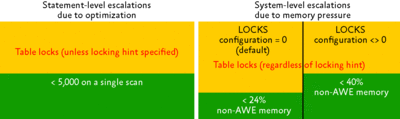
Figure 1 Conditions that cause lock escalation (Click the image for a larger view)
- 24 percent of the non-address-windowing extensions (non-AWE) memory used by the database engine if the locks setting is 0
- 40 percent of the non-AWE memory used by the database engine if the locks setting is not 0
If an escalation does happen to occur, it is always to a table lock.
Avoiding Unnecessary Blocking
Blocking can occur on any grain of lock, but blocking exposure is increased when escalations occur. Lock escalation may be a sign that your application is inefficiently designed, coded, or configured.
Adhering to database design fundamentals (such as using a normalized schema with narrow keys and avoiding bulk data operations on transactional systems) is important to avoiding blocking. If these principles aren't followed (such as separating out the reporting system from the transactional system or processing data feeds during non-business hours), it will be difficult to tune the system.
Indexing can be a key factor in how many locks are required to access the data. An index can reduce the number of records accessed by a query by reducing the number of internal lookups the database engine has to perform. For instance, when you select a single row from a table on a non-indexed column, each row in the table needs to be temporarily locked until the desired record is identified. In contrast, if that column were indexed, only a single lock would be needed.
SQL Server 2005 and SQL Server 2008 both contain dynamic management views (sys.dm_db_missing_index_group_stats, sys.dm_db_missing_index_groups, sys.dm_db_missing_index_details) that reveal tables and columns that would benefit from indexes, based on accumulated usage statistics.
Fragmentation may also be implicated in performance issues, in that the database engine may need to access more pages than it might otherwise. Moreover, incorrect statistics can lead the query optimizer to choose a less efficient plan.
Keep in mind that while indexes speed data access, they can slow data modification because not only does the underlying data need to change, but the indexes need to update as well. The dynamic management view sys.dm_db_index_usage_stats highlights how frequently indexes are being used. A common example of inefficient indexing occurs with composite indexes, where the same column is indexed both in isolation and in combination. Since SQL Server accesses indexes from left to right, the index will be used as long as the left-most columns are helpful.
Partitioning tables can both optimize the system (so there is less block exposure) and divide the data into separate physical objects that can be separately contended for. While enabling row partitions is a more obvious way of separating the data, partitioning the data horizontally is another option to consider. You may intentionally choose to de-normalize by splitting a table into separate tables with the same number of rows and keys, but different columns, to reduce the chances that separate processes will want to exclusively access the data at the same time.
The more diverse the ways an application can access a particular row of data and the more columns that might be included in that row, the more a column-partitioning approach may be attractive. Application queuing and state tables can sometimes benefit from this approach. SQL Server 2008 adds the ability to disable lock escalations per partition (or per table when partitions are not enabled for the table).
Query Optimization
Query optimization plays an important role in enhancing performance. Here are three approaches you can take:
Shorten the Transaction One of the most important ways to reduce blocking, as well as improve overall performance, is to ensure that transactions are as small as possible. Any processing that is not critical to the integrity of the transaction (such as looking up related data, indexing, and scrubbing data) should be taken out to reduce its size.
SQL treats each statement as an implicit transaction. If the statement affects a large number of rows, a single statement can still constitute a large transaction, especially if there are many columns involved or if the columns contain a large data type. A single statement may also cause page splits if the fill factor is high or if an UPDATE statement is filling out a column with a wider value than had been allocated. In such circumstances, it can be helpful to split the transaction into groups of rows, processing them one at a time until they are complete. Batching should only be considered when the individual statement or groups of statements can be broken into smaller batches that can still be considered complete as a unit of work if they succeed or fail.
Sequence the Transaction Within the transaction, intentionally sequencing the statements can decrease the likelihood of blocking. There are two principles to keep in mind. First, access objects in the same order within all SQL code in your system. Without a consistent order, deadlocks may occur where two competing processes access data in a different order, causing a system error for one of the processes. Second, place frequently accessed or expensive-to-access objects at the end of the transaction. SQL waits to lock the objects until they are needed in the transaction. Delaying access to the "hot spots" allows these objects to hold locks for a smaller percentage of time.
Use Locking Hints Locking hints can be used at either the session level or the statement level for a specific table or view. A typical scenario for using a session-level hint would be for a batch processing in a data warehouse, where the developer knows the process will be the only one running at a given time on that set of data. By using a command such as SET ISOLATION LEVEL READ UNCOMMITTED at the beginning of the stored procedure, SQL Server will not reserve any read locks, thus reducing the overall locking overhead and increasing performance.
A typical scenario for using statement-level hints would be when the developer knows a dirty read can safely occur (such as when reading a single row from a table where other concurrent processes will never need that same row) or when all other performance-tuning efforts have failed (schema design, index design and maintenance, and query tuning) and the developer wants to force the compiler to use a specific kind of hint.
Row-lock hints may make sense if monitoring demonstrates that larger-grained locks have occurred where very few records are affected by the query, as this could reduce blocking. Table-lock hints may make sense if monitoring shows that smaller-grained locks are being held (and not escalated) when nearly all the records in the table are affected by the query, as this could reduce system resources needed to hold the locks. Note that specifying a locking hint does not guarantee the lock will not be escalated when the number of locks reaches the threshold for system memory. However, doing so will prevent all other escalations.
Adjust Your Configuration
As Figure 2 shows, there are a number of factors to consider when configuring your SQL Server system.
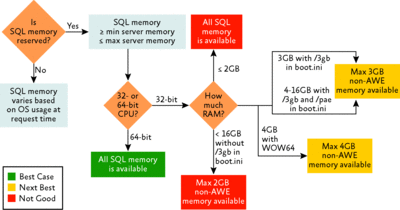
Figure 2 How SQL Server determines the amount of memory that can be used for locking (Click the image for a larger view)
Memory Locks are always held in non-AWE memory, so increasing the size of the non-AWE memory will increase the capacity of the system to hold locks.
A 64-bit architecture should be the first choice when attempting to increase locking capacity, as 32-bit architecture is limited to 4GB of non-AWE memory whereas 64-bit is not limited at all.
On 32-bit systems, you can grab an additional gigabyte of memory from the operating system for SQL Server by adding the /3GB switch to the Boot.ini file.
SQL Server Configuration Settings A variety of settings can be adjusted via sp_configure that affect locking. The locks setting configures how many locks can be held by the system before throwing an error. By default, the setting is 0, which means the server will dynamically adjust locks reserved with other processes competing for memory. SQL will initially reserve 2,500 locks, and each lock consumes 96 bytes of memory. Paged memory is not used.
The min and max memory settings reserve the amount of memory used by SQL Server, thus configuring the server to statically hold the memory. Since lock escalation is related to available memory, reserving the amount of memory from competing processes can make a difference regarding whether or not escalations will occur.
Connection Settings By default, locks that are blocking don't time out, but you can use the @@LOCK_TIMEOUT setting, which causes an error to occur if the specified wait threshold for a lock to release is exceeded.
Trace Flags Two trace flags in particular relate to lock escalations. One is trace flag 1211, which disables lock escalations. If the number of locks consumed exceeds the available memory, an error is thrown. The other is trace flag 1224, which disables lock escalations for individual statements.
Watching Your System
Further Reading
- Inside Microsoft SQL Server 2005: The Storage Engine by Kalen Delaney
- How to Monitor Blocking in SQL Server 2005 and in SQL Server 2000
- SQL Server 2005 Performance Statistics Script
- How to Resolve Blocking Problems that Are Caused by Lock Escalation in SQL Server
- Lock Escalation (Database Engine)
The impact that locking has on overall system performance can be monitored for blocks and locks by polling state data at given intervals (perhaps hourly) and capturing running statistics on the locks being held. Key information to capture is:
- Affected object, grain, and lock type
- Lock and block duration
- SQL command being issued (stored procedure name, SQL statement within)
- Information on the blocking chain, where relevant
- How the system is consuming its available locking capacity
You can run a script like the one in Figure 3 to capture this information, writing it to a table with the relevant timestamp. And to further break down the ResourceId of the data being blocked, you could run a script like the one in Figure 4.
Figure 4 Learning more about blocked data
DECLARE @SQL nvarchar(max)
, @CallingResourceType varchar(30)
, @Objectname sysname
, @DBName sysname
, @resource_associated_entity_id int
-- TODO: Set the variables for the object you wish to look up
SET @SQL = N'
USE ' + @DbName + N'
DECLARE @ObjectId int
SELECT @ObjectId = CASE
WHEN @CallingResourceType = ''OBJECT''
THEN @resource_associated_entity_id
WHEN @CallingResourceType IN (''HOBT'', ''RID'', ''KEY'',''PAGE'')
THEN (SELECT object_id
FROM sys.partitions
WHERE hobt_id = @resource_associated_entity_id)
WHEN @CallingResourceType = ''ALLOCATION_UNIT''
THEN (SELECT CASE
WHEN type IN (1, 3)
THEN (SELECT object_id
FROM sys.partitions
WHERE hobt_id = allocation_unit_id)
WHEN type = 2
THEN (SELECT object_id
FROM sys.partitions
WHERE partition_id = allocation_unit_id)
ELSE NULL
END
FROM sys.allocation_units
WHERE allocation_unit_id = @resource_associated_entity_id)
ELSE NULL
END
SELECT @ObjectName = OBJECT_NAME(@ObjectId)'
EXEC dbo.sp_executeSQL
@SQL
, N'@CallingResourceType varchar(30)
, @resource_associated_entity_id int
, @ObjectName sysname OUTPUT'
, @resource_associated_entity_id = @resource_associated_entity_id
, @CallingResourceType = @CallingResourceType
, @ObjectName = @ObjectName OUTPUT
Figure 3 Capturing locking stats
SELECT er.wait_time AS WaitMSQty
, er.session_id AS CallingSpId
, LEFT(nt_user_name, 30) AS CallingUserName
, LEFT(ces.program_name, 40) AS CallingProgramName
, er.blocking_session_id AS BlockingSpId
, DB_NAME(er.database_id) AS DbName
, CAST(csql.text AS varchar(255)) AS CallingSQL
, clck.CallingResourceId
, clck.CallingResourceType
, clck.CallingRequestMode
, CAST(bsql.text AS varchar(255)) AS BlockingSQL
, blck.BlockingResourceType
, blck.BlockingRequestMode
FROM master.sys.dm_exec_requests er WITH (NOLOCK)
JOIN master.sys.dm_exec_sessions ces WITH (NOLOCK)
ON er.session_id = ces.session_id
CROSS APPLY fn_get_sql (er.sql_handle) csql
JOIN (
-- Retrieve lock information for calling process, return only one record to
-- report information at the session level
SELECT cl.request_session_id AS CallingSpId
, MIN(cl.resource_associated_entity_id) AS CallingResourceId
, MIN(LEFT(cl.resource_type, 30)) AS CallingResourceType
, MIN(LEFT(cl.request_mode, 30)) AS CallingRequestMode
-- (i.e. schema, update, etc.)
FROM master.sys.dm_tran_locks cl WITH (nolock)
WHERE cl.request_status = 'WAIT' -- Status of the lock request = waiting
GROUP BY cl.request_session_id
) AS clck
ON er.session_id = clck.CallingSpid
JOIN (
-- Retrieve lock information for blocking process
-- Only one record will be returned (one possibility, for instance,
-- is for multiple row locks to occur)
SELECT bl.request_session_id AS BlockingSpId
, bl.resource_associated_entity_id AS BlockingResourceId
, MIN(LEFT(bl.resource_type, 30)) AS BlockingResourceType
, MIN(LEFT(bl.request_mode, 30)) AS BlockingRequestMode
FROM master.sys.dm_tran_locks bl WITH (nolock)
GROUP BY bl.request_session_id
, bl.resource_associated_entity_id
) AS blck
ON er.blocking_session_id = blck.BlockingSpId
AND clck.CallingResourceId = blck.BlockingResourceId
JOIN master.sys.dm_exec_connections ber WITH (NOLOCK)
ON er.blocking_session_id = ber.session_id
CROSS APPLY fn_get_sql (ber.most_recent_sql_handle) bsql
WHERE ces.is_user_process = 1
AND er.wait_time > 0
You can also monitor your system for escalations through SQL Profiler (Lock:Escalation event), the dm_db_index_operational_stats dynamic management view (index_lock_promotion_count), or regular polling of system locking information. The pertinent information to glean from escalation monitoring is whether the processing warrants an escalation; if not, the relevant stored procedures can pinpoint a root cause for performance problems. Tables with large amounts of data or high concurrent usage should be the primary focus of the evaluation.
After gathering data on locking, blocking, and escalations, the data can then be analyzed to determine the cumulative block and lock time (number of incidences multiplied by duration of incidences) per object. Typically, this can initiate an iterative cycle of performance tuning where changes are deployed, monitored, analyzed, and fixed. Sometimes all it takes is a simple change such as adding an index to make a significant performance improvement and will alter which area in the system constitutes the most painful performance bottleneck.
You can find more information about reducing blocking in SQL Server in the "Further Reading" sidebar. If careful attention is given to keeping transactions small throughout the design, coding, and stabilization phases, many blocking issues can be minimized. Appropriate hardware can significantly reduce the likelihood of unwanted escalations as well. Regardless, ongoing evaluation of blocking on the system can quickly identify performance problems at their root.
Cherié Warren is a Senior Development Lead for Microsoft IT. She is currently responsible for one of the largest transactional databases at Microsoft. Cherié also frequently consults on root cause and address performance problems related to blocking. She has been specializing in enterprise-level SQL Server databases for 10 years.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.