Windows Administration
Introducing Windows Server 2008 Failover Clustering
Chuck Timon
At a Glance:
- Failover Cluster Management snap-in
- New features and enhancements
- Backup and Restore Functionality
- Migrating from Windows Server 2003
Contents
New Management Interface
Improved Configuration Processes
Embedded Validation Procedure
New Quorum Model
Enhanced Security Features
Expanded Networking Functionality
Increased Reliability When Interacting with Storage
Built-In Recovery Processes
New Backup and Restore Functionality
Migrating from Windows Server 2003 Server Clusters
Ever since clustering was first introduced in Windows NT 4.0 Enterprise Edition, users have complained that it is too hard to set up and even harder to maintain. Administering a cluster has
required the administrator to have more than just an understanding of the clustering piece itself—the administrator has also needed intimate knowledge of storage technologies and how the cluster service would interact with a variety of storage solutions. The comprehensive skill set required to get a high availability solution up and running, and then maintain it, was hard to come by in many organizations.
Clustering has improved over the years, but it still left much to be desired when Microsoft began working on Windows Server® 2008. With this in mind, the team set out to redesign clustering with the primary goal of simplicity. In Windows Server 2008, Microsoft® Cluster Services (MSCS) has received a complete facelift and is now called Failover Clustering.
That's not to say simplicity is the only thing the new Failover Clustering implementation brings to the table. Over the years, Microsoft has learned many lessons, as organizations have provided valuable feedback about what they would like to see in a listened clustering solution. The new Failover Clustering functionality addresses many of the top issues users have reported and also tosses in some exciting new features that make it a very attractive proposition. So in this article, I'd like to introduce you to some of the cool new features you'll find in Windows Server 2008 Failover Clustering.
New Management Interface
After you install Failover Clustering, the Failover Cluster Management interface can be accessed in Administrative Tools or by running Cluadmin.msc. The Failover Cluster Management snap-in, like other management interfaces in Windows Server 2008, is a Microsoft Management Console (MMC) 3.0. For cluster veterans, opening the Failover Cluster Management snap-in for the first time will feel a bit like being dropped in a foreign country with no map.
The new interface is divided into three distinct panes, as shown in Figure 1. The left-hand pane lists all the Windows Server 2008 Failover Clusters in your organization. The center pane provides details about whichever part of a cluster configuration you've selected in the left-hand pane, while the right-hand pane shows you the actions that can be executed.
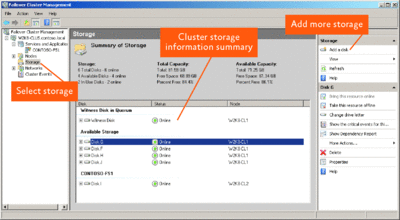
Figure 1 Failover Cluster Management snap-in (Click the image for a larger view)
Say, for example, you select Storage in the left-hand pane. The center pane then details what storage has been provisioned in the cluster, and what storage, if any, is currently available. As you can see in Figure 1, the cluster contains a piece of storage that supports a witness disk, storage that has been provisioned for a File Server, and some available storage. The right-hand pane lists relevant actions, such as adding more storage. Note that the Failover Cluster Management snap-in cannot be used to administer previous versions of Microsoft Clustering Services.
Improved Configuration Processes
Configuring a Failover Cluster is quite easy. Many of the actions for configuring, reconfiguring, and maintaining a cluster have wizards. Thanks to these wizards, the administrator no longer has to be concerned about whether resources are configured correctly or whether they will come online in the correct order.
Figure 2 shows the High Availability Wizard. In this particular example, a File Server has been configured. On the left, you can see the list of steps the wizard has guided the administrator through. Once the process is complete, a summary page is displayed and a report can be viewed.
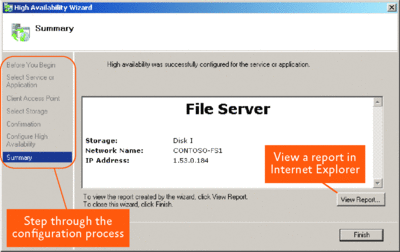
Figure 2 High Availability Wizard (Click the image for a larger view)
Embedded Validation Procedure
In previous versions of Windows Server, to be considered a supported cluster solution, hardware configurations had to be listed as a Cluster Solution in the Windows Server Catalog. This included multi-site clusters, which were listed separately under the Geographically Dispersed category. To be listed in the catalog, the hardware vendors had to run a set of Windows Hardware Quality Lab (WHQL) tests and submit the results to Microsoft. This was a costly proposition for the vendor, and the Windows Server Catalog database was difficult to maintain.
In Windows Server 2008, a built-in validation process is included in Failover Clustering. This process consists of a series of tests that are grouped into four main categories, as shown in Figure 3.
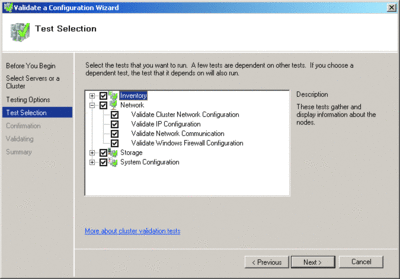
Figure 3 Failover Cluster validation test categories (Click the image for a larger view)
You can see that the Network category is expanded to show the tests that are run; each category contains a series of tests. The Storage category, which is perhaps the most critical of the four categories, includes tests that ensure storage solutions comply with the new requirements put in place for Windows Server 2008 Failover Clusters.
Specifically, hardware vendors now must use drivers based on the Microsoft Storport driver, and they must support SCSI-3 Persistent Reservations. Additionally, multi-path software Device Specific Modules, when used, must be based on the Microsoft Multi-Path Input\Output standard.
With the incorporation of the validation process, the support model has changed. All hardware must have a Windows Server 2008 logo, and all validation tests must pass. The only exceptions are multi-site clusters that have two separate and distinct storage enclosures—one at each site—and the Exchange Server 2007 cluster continuous replication implementation, which doesn't use any shared storage.
New Quorum Model
The Quorum Model has also changed in Windows Server 2008 Failover Clustering. In older systems, when an administrator heard the word quorum, he thought of a shared disk where the cluster configuration and some replicated files resided. This was a single point of failure in the cluster. If the quorum disk failed, the cluster service terminated and high availability was lost.
Windows Server 2003 Server Clusters offered a second quorum type called the Majority Node Set quorum. This type of quorum was typically implemented in multi-site clusters and required no shared storage. The Majority Node Set quorum consisted of a file share that resided on the system drive on each cluster node. Connections to this quorum type were by way of Server Message Block (SMB) connections. Once again, in order for the cluster to function, a majority of nodes had to be participating.
Then, with the introduction of Exchange Server 2007 cluster continuous replication (CCR), File Share Witness (FSW) capability was added to Windows Server 2003 Server Clusters. This allowed for a single Exchange 2007 CCR cluster node (or any multi-site cluster) to continue to provide services as long as a connection to the FSW resulted in a majority being achieved.
In Windows Server 2008 Failover Clustering, the concept of quorum now truly means consensus. Quorum, or consensus, is now achieved by having enough votes to bring the cluster into service. Enough votes can be obtained in several ways, depending on the quorum configuration. There are four quorum modes available in a Windows Server 2008 Failover Cluster, and they are shown in Figure 4. Of the four modes listed, only the first two (Node Majority, and Node and Disk Majority) can be automatically selected during the create cluster process. The following logic should be used:
- If an odd number of nodes are being configured in the cluster, select Node Majority mode.
- If an even number of nodes are being configured in the cluster and shared storage is connected and accessible, then select Node and Disk Majority.
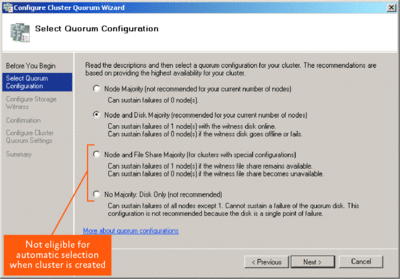
Figure 4 Quorum Modes in the Configure Cluster Quorum Wizard (Click the image for a larger view)
To select a witness disk from available storage, select the first disk that is at least 500 megabytes in size and has an NTFS partition configured. The remaining quorum modes can only be selected manually by running the Configure Cluster Quorum Wizard. The Node and File Share Majority option is typically used in a multi-site cluster configuration or in an Exchange 2007 CCR cluster. The last option, No Majority: Disk Only mode, is equivalent to the shared quorum model in legacy clusters. It is a single point of failure and generally should not be used.
There are only two types of witness resources, a physical disk and a file share, that can be configured in the cluster to help achieve consensus.
A witness disk is a piece of storage that the cluster service can bring on line. This disk is located in the Cluster Core Resource Group along with the cluster Network Name and associated IP address resources. When the witness disk is configured, a Cluster folder is placed on the disk and a full copy of the cluster configuration (a cluster hive or replica) is placed on the disk.
An FSW is a network share that is located, in an ideal situation, on a server on the network that is not part of the cluster. An SMB connection is made to the FSW, and the FSW maintains a copy of the witness log file, which contains versioning information for the cluster configuration.
There can only be one witness resource configured in a cluster. This resource provides an extra vote should the cluster need it to achieve quorum. In other words, if the cluster is one vote (and therefore one node) short of achieving a consensus, the witness resource is brought online so quorum can be achieved. If the cluster should be more than one vote short of achieving quorum, the witness resource is left alone and the cluster remains in a dormant state, waiting for another cluster node to join.
Enhanced Security Features
Failover Clusters feature several new security enhancements. Perhaps the most significant involves the removal of the requirement for a Cluster Service Account (CSA). In previous versions of the Microsoft Cluster Service, a domain user account was required during the configuration process. This account, which was used to start the cluster service, was added to the local administrators group on each node of the cluster and given the required local user rights to allow the cluster service to function properly. As a domain user account, the CSA was subject to a number of domain-level policies that could be applied to cluster nodes. These policies could adversely impact high availability by causing the cluster service to fail.
The cluster service now runs under a local system account with a specific set of rights on the local cluster node that allows it to function properly. The security context for the cluster has transitioned to the Cluster Name Object (CNO), which is the computer object that is created, by default, in the Computers container in Active Directory® when the cluster is first created. Once a cluster is successfully created and the CNO exists in Active Directory, the user account that was used to install and configure the cluster is no longer needed.
Additional computer objects created in Active Directory in the Computers container are associated with a Failover Cluster. These objects, called Virtual Computer Objects (VCOs), equate to cluster Network Name resources that are created as part of Client Access Points (CAPs) in the cluster. The CNO, which is responsible for creating all VCOs in a cluster, is added to the System Access Control List (SACL) for the object in Active Directory (see Figure 5).
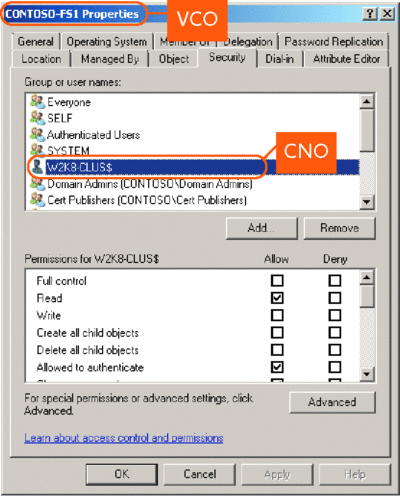
Figure 5 Security on a VCO in Active Directory (Click the image for a larger view)
The CNO also takes on the responsibility for synchronizing the domain passwords for all the VCOs it has created. This process is accomplished in accordance with the configured domain policy for password rotation. Additionally, since the CNO is responsible for creating all the computer objects associated with the VCOs in a cluster, the CNO (Computer Account) must have the domain-level right to create computer objects on the container where the VCOs are created (by default, that is the Computers container).
Another change, Kerberos is now used as the default authentication method. The existence of computer accounts in Active Directory allow for this enhanced security feature. But the cluster has the ability to use NT LAN Manager (NTLM) authentication should an application that is not able to use Kerberos for authentication ever need to access cluster resources.
Communication between cluster nodes that deal directly with the cluster process are also more secure. All intra-cluster communications are signed by default. Using the cluster.exe common language interface (CLI), this cluster property can be changed so all communications between nodes are encrypted to provide an additional level of security.
Expanded Networking Functionality
New networking capabilities in Failover Clusters enable more flexibility when designing high availability and disaster recovery solutions. At the same time, these networking enhancements provide more reliable connectivity among the nodes in the cluster.
Probably the most requested customer feature has been the ability to locate cluster nodes on separate networks. This is now possible. The cluster network driver has been completely rewritten so that it provides highly reliable and fault-tolerant communication among nodes in a cluster, provided each node is connected to at least two separate and distinctly routed networks.
The cluster network driver constructs its own internal routing table based on the connectivity information provided during the cluster startup process. This includes local connectivity information as well as information that is provided in the cluster configuration database (cluster registry hive).
Part of the cluster validation process includes a network connectivity discovery process. Being able to locate cluster nodes on different, routed networks has eased the networking requirements for multi-site clusters. This will make it easier and less expensive for organizations to deploy them. It also makes the use of iSCSI storage a more attractive storage solution for use in Failover Clusters.
Cluster nodes can also obtain IP Address information via DHCP (Dynamic Host Configuration Protocol). This can ease the burden on network administrators, if they can accept using dynamic addressing for the servers in their environment.
The configuration of a cluster node's network interfaces determines which networks will use static or dynamic IP addresses. Even if an IP address resource in a cluster is obtained from a DHCP server, it can be changed to a static IP address in the Failover Cluster Management snap-in.
In the past, all cluster communication used User Datagram Protocol (UDP) broadcast, and sometimes, multicast. Multicast functionality has been discontinued and cluster communications now use UDP unicast. (Port 3343 is still the common port used by Microsoft clusters.) Many network administrators will be very happy to find that broadcast is no longer used. The real payoff in a cluster, however, has to do with the new messaging processes that are internal to the cluster service itself. (This, however, is beyond the scope of this article.) Intra-cluster communications now have characteristics of more reliable TCP communications even though UDP is used as the transport mechanism.
Increased Reliability When Interacting with Storage
The way in which Failover Clusters interact with storage is drastically different. The cluster disk driver (clusdisk.sys) was completely rewritten and is now a true Plug and Play (PnP) driver. And how it interacts with storage has changed.
In Windows Server 2003, the cluster disk driver was in a direct path to the storage. But in Windows Server 2008, the cluster disk driver communicates with the partition manager (partmgr.sys) driver in order to interact with storage. These two approaches are illustrated in Figure 6.
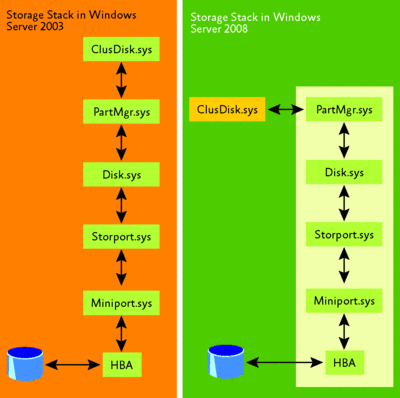
Figure 6 How the storage stack has changed in Windows Server 2008 (Click the image for a larger view)
Partition manager has the primary responsibility of protecting cluster disk resources. All disks on a shared storage bus are automatically placed in an offline state when first mapped to a cluster node. This allows storage to be simultaneously mapped to all nodes in a cluster even before the cluster is created. No longer do nodes have to be booted one at a time, disks prepared on one and then the node shut down, another node booted, the disk configuration verified, and so on.
There are still, however, the storage tests, which are run as part of the cluster validation process and require the disks to be initialized. This can be accomplished on one of the nodes of the cluster before the validation process is executed. Once storage is added to a cluster, the disks show a status of Reserved in the Disk Management interface and are never left in an unprotected state.
Another change has to do with the SCSI commands. In Windows Server 2003, SCSI-2 Reserve\Release commands were used with the cluster disk driver writing to sectors on the disk itself. In Windows Server 2008, SCSI-3 PR (Persistent Reservation) commands are required. Cluster nodes must register before they are allowed to place a reservation on the storage, and cluster nodes periodically defend their reservations using the Registration Defense Protocol.
One of the storage tests in the validation process verifies this functionality. If a storage solution does not support SCSI-3 (PR) commands, it is therefore not supported in a Failover Cluster.
Many organizations use multi-path software for redundancy when connecting to storage. This is supported and even promoted as a best practice. However, third-party multi-path software solutions, or device specific modules, must be rewritten using the Microsoft Multi-Path Input\Output standard to be supported in a Failover Cluster. This ensures that all SCSI-3 PR commands are simultaneously sent down all paths to the storage whether the path is active or not. This functionality is also verified as part of the validation process.
Additional storage improvements include an improved check disk (chkdsk.exe) process, built-in disk repair functionality that was previously part of the Cluster Server Recovery Utility, and self-healing disks. In Failover Clusters, the disk signature and the LUN ID are both used when identifying a cluster disk resource. If either of these has changed, the cluster configuration is updated. This translates into reduced errors simply due to an attribute change on a physical disk resource resulting in greater high availability.
Built-In Recovery Processes
The previously mentioned disk repair is obviously one of the built-in recovery capabilities. Another is an Active Directory Repair capability. If the computer object that represents the CNO is deleted, you will no longer be able to create the computer objects associated with cluster CAPs. However, the first issue you'll experience will likely be when highly available apps or users can't gain access to resources outside of the cluster because a security token cannot be obtained.
Recovering from a deleted CNO is a two-step process. First, you must engage a Domain Administrator to recover the deleted computer object from the DeletedObjects container in Active Directory. Then, after the object has been restored and re-enabled, you execute the Repair Active Directory Object process in the Failover Cluster Management snap-in.
In Windows Server 2003 Server Clusters, there was a possibility that the cluster configuration file located in the %systemroot%\cluster subdirectory would become corrupted and then have to be replaced. In Failover Clusters, the self-healing capability can help. If the cluster service starts on a node and the configuration database is corrupted, a minimal configuration template will be loaded using information contained in the HKLM\System\CCS\Services\ClusSvc\Parameters registry key. The node will attempt to join an already formed cluster and, if this attempt is successful, a fresh copy of the cluster registry hive will be pushed to the node. If a node cannot join a cluster, the cluster service will be terminated.
New Backup and Restore Functionality
Failover Clustering comes with its own Volume Shadow Copy Service writer. This plays a key role in backing up and restoring a cluster database and the data that resides on the physical disk resources. Backing up the cluster configuration is pretty straightforward. As long as the system state is part of a backup, the cluster configuration can be restored. But note that a cluster should only be backed up if the cluster has quorum. This guarantees the most up-to-date cluster configuration is backed up.
There are two distinct types of cluster restores: authoritative and non-authoritative. A non-authoritative restore uses Windows Server Backup or a third-party backup application to execute a restore from a selected backup. An authoritative restore of a cluster node, on the other hand, can only be accomplished using the Windows Server Backup CLI (wbadmin.exe).
An authoritative restore essentially takes the cluster configuration "back in time" to when the backup was performed. To accomplish an authoritative restore, the cluster service is stopped on all nodes except the node on which the restore is being executed. Once the restore is complete and the cluster service has been started on the restored node, the restored configuration of the cluster becomes the definitive new cluster configuration. Then, when the cluster service is restarted on the remaining nodes in the cluster, the restored configuration is pushed out during the join process.
This can save significant time and money in some certain scenarios. Suppose you have a print cluster that hosts multiple print spooler resources, each supporting 1,500 printers, and you accidentally delete one of the print spooler resources. Now a large number of users cannot print. Rather than manually adding all those printers back into the cluster configuration, it would be much faster to conduct an authoritative restore of the cluster configuration. This, of course, depends on you having a sound backup and restore strategy in place.
Migrating from Windows Server 2003 Server Clusters
Due to all these architectural changes in Windows Server 2008 Failover Clustering, in-place or rolling upgrades from Windows Server 2003 are not supported. When upgrading from Windows Server 2000 clusters to Windows Server 2003, many organizations would systematically evict each node in the cluster, do a clean installation of the operating system, and then add the node back into the cluster. This approach cannot be used for migrating to Windows Server 2008, as Windows Server 2003 and Windows Server 2008 cluster nodes cannot be part of the same cluster.
Fortunately, to help with the migration, a wizard-based migration process has been included. But migrating to a Windows Server 2008 Failover Cluster will, nonetheless, require some planning. There are three basic migration scenarios:
- Using the same servers and storage.
- Using the same servers, but using them with new storage.
- Using new servers and new storage.
Any of these scenarios will involve making sure the hardware has been certified under the Windows Server 2008 logo program and that the Failover Cluster validation process has been run and all tests passed. Once those steps are complete, the migration process can move forward.
Not all resources in a Windows Server 2003 Server Cluster can be migrated. You can migrate network names, IP addresses, physical disks, file shares, distributed file share (DFS) roots, DHCP, and WINS. You can also migrate, to a limited extent, generic services, generic apps, and generic script resources.
Meanwhile, such applications as Microsoft Exchange and SQL Server® have their own procedures for migrating to a Failover Cluster. Printers can be migrated to Windows Server 2008 using the Print Management snap-in (which is installed with the Print Server Role) to first export and then import printers to a newly configured, highly available print server. No third-party resource types are eligible for migration.
The migration process does not migrate any data. It involves migrating cluster configuration settings from Windows Server 2003 to Windows Server 2008.
All migrated resources are initially placed in an offline state when the migration process completes. This is done because there may be additional necessary steps. Therefore, it is important to review the post-migration report to see what additional steps (exclusive of the data migration if migrating to new storage) are required prior to bringing the cluster into service. As an example, if a DHCP server is being migrated, the DHCP Server Role must be installed on all nodes in the cluster. If migrating a WINS Server, the WINS Server feature must be installed on all nodes in the cluster.
Chuck Timon is a Support Escalation Engineer at Microsoft supporting Cluster and Setup technologies He wrote the Windows Server 2008 Failover Cluster training and is now working on the Hyper-V training.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.