SQL Server 2008
Advanced Troubleshooting with Extended Events
Paul S. Randal
At a Glance:
- Why troubleshooting is necessary
- Troubleshooting tools in SQL Server
- Overview and architecture of Extended Events
- Using Extended Events
Contents
Troubleshooting in SQL Server 2005
Extended Events
Performance Considerations
Life of an Event
Using Extended Events
The system_health Extended Events Session
Wrapping Up
SQL Server DBAs the world over have a problem that never seems to go away: troubleshooting, with the vast majority of troubleshooting being done to find a performance problem of some kind. Even the most carefully architected and tested application system will experience changes over time that can lead to significant performance issues.
For example, the workload can change (such as the number of concurrent users, the queries being performed, and new month-end reports being run), the volume of data being processed may increase, the hardware on which the system is running may change (such as the number of processor cores, amount of server memory available, and I/O subsystem capacity), and new concurrent workloads might be introduced (such as transactional replication, database mirroring, and change data capture).
Video (no longer available)
Paul Randal demonstrates how you can use the new Extended Events functionality in SQL Server 2008 for monitoring and troubleshooting.
But those aren't the only problems that occur. When designing and testing application systems, unanticipated problems are often found with the design, which then also require troubleshooting. Obviously, regardless of when in the app lifecycle the problem is discovered, troubleshooting must be performed to identify the cause and a solution.
A complex application system will have many hardware and software components that may need to be analyzed, but the one I am concerned with is SQL Server. Without considering the various performance troubleshooting methodologies (which would be a conversation well beyond the scope of this article), what are the tools you need for troubleshooting in SQL Server?
Troubleshooting in SQL Server 2005
Over the last few releases of SQL Server, the selection of tools available for performance troubleshooting has expanded considerably. SQL Server has always had numerous DBCCs (Database Console Command) commands available to provide insight into what's going on in the various parts of the database engine. In addition, there is SQL Server Profiler and programmatically using the underlying SQL Trace mechanism.
Although SQL Server has continually offered advancements for troubleshooting, these options have some problems. Post-processing of DBCC output is awkward, as you need to dump the results into a temporary table before you can do anything with them. And running SQL Trace/Profiler can cause a performance degradation when poorly configured (such as tracing all Lock: Acquired and Lock: Released events on a busy system and forgetting to filter on the event's DatabaseId and ObjectId columns). The screenshot in Figure 1 shows a dialog being used to configure a filter for a new trace.
Figure 1 Configuring a filter in SQL Server 2008 Profiler
SQL Server 2005 added dynamic management views and functions (collectively known as DMVs) as a way of getting information out of the database engine. DMVs superseded some DBCC commands, system tables, and stored procedures, and exposed many new areas of the workings of the engine. These DMVs are powerful commands that are composable—they can be used in complex T-SQL statements that filter and post-process the DMV results.
For example, the code shown in Figure 2 returns just the fragmentation and page density (both rounded) of the leaf levels of all indexes in a database, with a filter on the fragmentation level. This could not be done easily using my old DBCC SHOWCONTIG command. (For more information on DMVs, see "Dynamic Management Views and Functions (Transact-SQL)." In addition, SQL Server 2005 added a number of other features that could be used for troubleshooting, including DDL (data definition language) triggers and event notifications.
Figure 2 Using DMVs for powerful results
SELECT OBJECT_NAME (ips.[object_id]) AS 'Object Name', si.name AS 'Index Name', ROUND (ips.avg_fragmentation_in_percent, 2) AS 'Fragmentation', ips.page_count AS 'Pages', ROUND (ips.avg_page_space_used_in_percent, 2) AS 'Page Density' FROM sys.dm_db_index_physical_stats ( DB_ID ('SQLskillsDB'), NULL, NULL, NULL, 'DETAILED') ips CROSS APPLY sys.indexes si WHERE si.object_id = ips.object_id AND si.index_id = ips.index_id AND ips.index_level = 0 -- only the leaf level AND ips.avg_fragmentation_in_percent > 10; -- filter on fragmentation GO
Various teams within Microsoft have also provided useful performance troubleshooting tools, such as the SQLdiag utility, the RML Utilities for SQL Server, the SQL Server 2005 Performance Dashboard Reports, and DMVStats. There is also an Event Tracing for Windows (ETW) provider for SQL Server 2005, which allows SQL Trace events to be integrated with events from other portions of Windows.
While SQL Server 2005 made great strides to increase the ability of DBAs to troubleshoot the database engine, there were still many scenarios that were almost impossible for DBAs to troubleshoot effectively. In one commonly cited example, some queries use excessive amounts of CPU resources, but the DMVs don't provide enough information to pinpoint which ad hoc queries are the culprits. But unlike SQL Server 2005, SQL Server 2008 is able to address such limitations with a new feature called SQL Server Extended Events.
Extended Events
The capabilities of the Extended Events system are far beyond those of any previous event-tracking and troubleshooting mechanism that SQL Server has provided. In my opinion, the highlights of the Extended Events system are the following:
- Events fire synchronously but can be processed synchronously or asynchronously.
- Any target can consume any event and any action can be paired with any event, allowing for an in-depth monitoring system.
- "Smart" predicates enable you to build complex rules using Boolean logic.
- You can have complete control over Extended Events sessions using Transact-SQL.
- You can monitor performance-critical code without impacting performance.
Before I go on, I'll take a moment to define some of the new terminology.
Event An event is a defined point in code. Some examples are the point at which a T-SQL statement finished executing or the point at which acquiring a lock is completed. Each event has a defined payload (the set of columns that are returned by the event) and is defined using the ETW model (where every event returns a channel and keyword as part of the payload) to allow integration with ETW. SQL Server 2008 initially shipped with 254 defined events and more are expected to be added over time.
You can see the list of defined events using the following code:
SELECT xp.[name], xo.* FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp WHERE xp.[guid] = xo.[package_guid] AND xo.[object_type] = 'event' ORDER BY xp.[name];
And you can find the payload for a specific event using this code:
SELECT * FROM sys.dm_xe_object_columns WHERE [object_name] = 'sql_statement_completed'; GO
Note that the Extended Events system has a comprehensive set of informational DMVs that describe all of the events, targets, and so on. For more details, see "SQL Server Extended Events Dynamic Management Views."
Predicates Predicates are the method used to filter events using a set of logical rules before the events are consumed. Predicates can be simple, such as checking that one of the columns returned in the event payload is a certain value (for example, filtering lock-acquired events by object ID).
They also provide some advanced capabilities, such as counting the number of times a specific event has occurred during the session and only allowing the event to be consumed after an occurrence or dynamically updating the predicate itself to suppress the consumption of events containing similar data.
Predicates can be written using Boolean logic so that they short-circuit as soon as possible. This allows for the minimum amount of synchronous processing to be performed before determining whether the event is going to be consumed or not.
Action An action is a set of commands that are performed synchronously before an event is consumed. Any action can be linked to any event. They typically gather more data to append to the event payload (such as a T-SQL stack or a query execution plan) or perform some calculation that is appended to the event payload.
As actions can be expensive, the actions for an event are only performed after any predicate has been evaluated—there would be no point to synchronously performing an action if it were then determined that the event would not be consumed. A list of predefined actions can be found using the following code:
SELECT xp.[name], xo.* FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp WHERE xp.[guid] = xo.[package_guid] AND xo.[object_type] = 'action' ORDER BY xp.[name];
Target A target simply provides a way to consume events, and any target can consume any event (or at least dispose of it if there is nothing for the target to do—such as an audit target getting a non-audit event). Targets can consume events synchronously (for instance, the code that fired the event waits for the event to be consumed) or asynchronously.
Targets range from simple consumers, such as event files and ring buffers, to more complicated consumers that have the ability to perform event pairing. You can find the list of available targets using the following code:
SELECT xp.[name], xo.* FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp WHERE xp.[guid] = xo.[package_guid] AND xo.[object_type] = 'target' ORDER BY xp.[name];
For more details on targets, see "SQL Server Extended Events Targets."
Package A package is a container that defines Extended Events objects (such as events, actions, and targets). A package is contained within the module (such as an executable or a DLL) it describes, as shown in Figure 3.
.gif)
Figure 3 The relationship between modules, packages, and Extended Events objects
When a package is registered with the Extended Events engine, all the objects defined by it are then available for use. For more information on packages and a complete list of Extended Events terminology, see "SQL Server Extended Events Packages."
Session A session is a way of linking together Extended Events objects for processing—an event with an action to be consumed by a target. A session can link objects from any registered packages, and any number of sessions can use the same event, action, and so on. You can see which Extended Events sessions are defined using the following code:
SELECT * FROM sys.dm_xe_sessions; Go
Sessions are created, dropped, altered, stopped, and started using T-SQL commands. As you can imagine, this offers a lot of flexibility, even the ability to dynamically alter a session based on programmatic analysis of data being captured by the session itself. For more on sessions, see "SQL Server Extended Events Sessions."
Performance Considerations
When you put together an Extended Events session using CREATE EVENT SESSION, there are some settings you need to be careful to configure correctly, as they can inadvertently affect performance. Your first decision is whether to have the events consumed synchronously or asynchronously. And as you might expect, synchronous targets have greater effect on the performance of the code being monitored than do asynchronous targets.
As I explained above, when an event is consumed synchronously, the code that fired the event has to wait until the event has been consumed. Obviously, if consumption of the event is a complicated process, this can slow down the code.
For instance, on a busy system servicing thousands of small transactions per second, synchronous consumption of a sql_statement_completed event with an action to capture a query plan will very likely have a negative impact on performance. Also, remember that predicates are always executed synchronously, so care should be taken not to create overly complex predicates for events fired by performance-critical code.
On the other hand, you may be forced to consume events synchronously. To count the occurrences of a particular event, the easiest way to do this will likely be to use the synchronous_event_counter target.
The second thing you must consider is how to configure event buffering if you decide to use asynchronous targets. The default amount of memory available for event buffering is 4MB. The default dispatch latency between an event being fired and subsequently consumed by a target is 30 seconds. If, say, you want to produce some event statistics every 10 seconds, then you'll need to tweak the latency.
Tied to the event buffering settings is how you want to partition the memory used to buffer events. The default is to create a set of buffers for the entire instance. On SMP (symmetric multiprocessor) and NUMA (Non-uniform Memory Access) machines, this can lead to performance problems with processors having to wait for access to memory.
The third consideration is how you want to handle event loss. When you define the Extended Events session, you can specify whether events can be "lost." This means that if there isn't enough memory to buffer an event, it is simply discarded. The default is to allow single events to be dropped, but you can also allow whole buffers of events to be lost (for sessions where event buffers fill up very quickly) or even specify that no events can be lost.
This last option should be used with great caution, as it forces the code that fired the event to wait until there is buffer memory to store the event. Setting this option almost always has a detrimental effect on performance. Note that if you accidentally set this option to on, the server should remain responsive enough to allow you to turn the setting off.
Typically, you will want to consider these settings together. And there isn't really a generalized best practice I can give except to make sure you do put thought into them or you may run into performance problems. You can find more information about these settings in "CREATE EVENT SESSION (T-SQL)".
Life of an Event
Once the Extended Events session has been defined and started, processing continues as normal until the code being monitored comes across an event. The steps followed by the Extended Events system are outlined in Figure 4. The steps are as follows:
- A check is done to see whether any Extended Events sessions are monitoring the event. If not, control is returned to the code that contains the event, and processing continues.
- The event payload is determined, and all required information is gathered into memory—in other words, the event payload is constructed.
- If any predicates are defined for the event, they are executed. At this point, the result of the predicate may be that the event should not be consumed. If this is the case, control is returned to the code that contains the event, and processing continues.
- Now the system knows that the event will be consumed, so it executes any actions linked to the event. The event now has a complete payload and is ready for consumption.
- The event is served to synchronous targets, if any.
- If any asynchronous targets exist, the event is buffered for later processing.
- Control is returned to the code that contains the event, and processing continues.
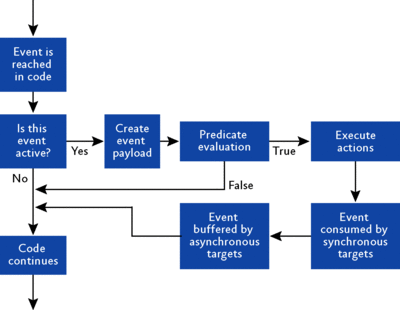
Figure 4 Life of an Extended Events event (Click the image for a larger view)
As I mentioned previously, care should be taken when creating an event session so that synchronous actions or buffering for asynchronous targets will not affect the performance of the code being monitored.
Using Extended Events
SQL Server 2008 Books Online includes two examples of using Extended Events: "How to: Determine Which Queries Are Holding Locks" and "How to: Find the Objects That Have the Most Locks Taken on Them."
I'd like to walk through an example of setting up an Extended Events session and analyzing the results. As I learned when I started using Extended Events in late 2007, putting together a simple session is very easy (using the straightforward T-SQL DDL statements), but analyzing the results is non-trivial.
The results are presented in XML, which initially surprised me before I realized that the huge number of possible combinations of events and actions that could be collected in a single session really meant there was no other feasible choice for storing such an extensible schema.
Now, I was a developer on the SQL Server Storage Engine team for many years and consider myself a highly proficient C, C++, and assembly programmer, but I had to spend a few hours figuring out the code necessary to extract event payload fields programmatically from the XML data. I'm not trying to dissuade you from using Extended Events; rather, I'm just warning you that if you're not used to working with XML data, be prepared for a bit of a learning curve before you see results.
Here's my scenario: I'm a DBA using the Resource Governor feature of SQL Server 2008 to sandbox various groups in my company on one of the production servers. I've created two Resource Governor resource pools—Development and Marketing—to represent each team using that server. Resource Governor allows me to limit each pool's CPU and query execution memory usage, but not the amount of I/O resources they use. So, I'd like to institute a chargeback mechanism that helps me amortize the cost of upgrading to a new SAN (storage area network) by billing each team for I/O usage on that server.
I assume that the easiest way to trigger capturing I/O information is when any T-SQL statement completes, and I know there's an event called sql_statement_completed in the package0 package. So what data is collected in the event payload?
Executing the following code will give me the list of all the data, including both reads and writes:
SELECT [name] FROM sys.dm_xe_object_columns WHERE [object_name] = 'sql_statement_completed'; GO
I don't think that these are physical reads and writes (when data is read from or written to disk, rather than just in memory in the buffer pool), but they'll give me an idea of the proportion of I/O resources being used by each team.
Now I need to figure out which team executed a particular T-SQL statement, and so I need an action that will tell me that. Executing this code gives me a list of all the actions I can take when the event fires, including one that collects the session_resource_pool_id in the sqlserver package:
SELECT xp.[name], xo.* FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp WHERE xp.[guid] = xo.[package_guid] AND xo.[object_type] = 'action' ORDER BY xp.[name];
I can get the list of resource pools I've defined for the Resource Governor and correlate that with the IDs collected by my Extended Events session. Now I'm ready to define my session. Note that when I execute this code, it will first check to see whether an event session with the same name exists. If it finds one with the same name, it will drop the session. Here's the code:
IF EXISTS ( SELECT * FROM sys.server_event_sessions WHERE name = 'MonitorIO') DROP EVENT SESSION MonitorIO ON SERVER; GO CREATE EVENT SESSION MonitorIO ON SERVER ADD EVENT sqlserver.sql_statement_completed (ACTION (sqlserver.session_resource_pool_id)) ADD TARGET package0.ring_buffer; GO
Then it creates a new session with a single event, sql_statement_completed, that also performs the session_resource_pool_id action, logging everything to a ring buffer while I'm still prototyping. (In production, I would most likely choose to use an asynchronous file target.)
To start my session, I will need to execute this code:
ALTER EVENT SESSION MonitorIO ON SERVER STATE = START; GO
Now it's up and running.
After faking some activity from the marketing and development teams, I'm ready to analyze the session results. This code will extract the data from the ring buffer:
SELECT CAST(xest.target_data AS XML) StatementData FROM sys.dm_xe_session_targets xest JOIN sys.dm_xe_sessions xes ON xes.address = xest.event_session_address WHERE xest.target_name = 'ring_buffer' AND xes.name = 'MonitorIO'; GO
However, it extracts the data as one large XML value. If I want to break it down further, I can use the code shown in Figure 5.
Figure 5 Breaking down the XML data
SELECT Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads, Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes, Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID FROM (SELECT CAST(xest.target_data AS XML) StatementData FROM sys.dm_xe_session_targets xest JOIN sys.dm_xe_sessions xes ON xes.address = xest.event_session_address WHERE xest.target_name = 'ring_buffer' AND xes.name = 'MonitorIO') Statements CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results); GO
This works but gives one line of output for each event that's captured. That's not a terrific format plus I'd like to get aggregated output, so I decided to use a derived table, as you can see in Figure 6.
Figure 6 Getting aggregated output
SELECT DT.ResourcePoolID, SUM (DT.Reads) as TotalReads, SUM (DT.Writes) AS TotalWrites FROM (SELECT Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads, Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes, Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID FROM (SELECT CAST(xest.target_data AS XML) StatementData FROM sys.dm_xe_session_targets xest JOIN sys.dm_xe_sessions xes ON xes.address = xest.event_session_address WHERE xest.target_name = 'ring_buffer' AND xes.name = 'MonitorIO') Statements CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results)) AS DT WHERE DT.ResourcePoolID > 255 –- only show user-defined resource pools GROUP BY DT.ResourcePoolID; GO
Phew! There is certainly some complicated code in there, but it works well. So now I've got the results I desired. Look at the output from this query on my test data, shown in Figure 7.
| Figure 7 Output from my query |
| ResourcePoolID | TotalReads | TotalWrites |
| 256 | 3831 | 244 |
| 257 | 5708155 | 1818 |
I know that resource pool 256 is for marketing, and 257 is for development—so these numbers make sense in terms of how much database activity I'd expect from the teams in my company. I could not have produced these results as easily had I not used Extended Events.
And finally, I need to stop the session using the following code:
ALTER EVENT SESSION MonitorIO ON SERVER STATE = STOP; GO
To see more of what I'm talking about in terms of the output at each stage of this example, check out the screen cast that accompanies this article. You can find it at technetmagazine.com/video.
The system_health Extended Events Session
SQL Server 2008 actually ships with a pre-defined session that is set to run by default and is called the system_health session. This session was the idea of the Product Support team and it keeps track of information they commonly use to debug customer systems, such as when a deadlock or a high-severity error occurs. The session is created and started as part of the install process for a SQL Server 2008 instance, and it tracks events in a ring buffer so that it does not consume too much memory.
You can use the following code to see what the ring buffer contains:
SELECT CAST (xest.target_data AS XML) FROM sys.dm_xe_session_targets xest JOIN sys.dm_xe_sessions xes ON xes.address = xest.event_session_address WHERE xes.name = 'system_health'; GO
The Microsoft PSS SQL Support blog has more detailed information on what's tracked by this session.
Wrapping Up
I've been told that the SQL Server team is planning to add many more events into sqlserver.exe in the future. In fact, the number jumped from 165 in the February 2007 CTP (Community Technology Preview) release to 254 in the RTM (release to manufacturing) release.
There are some really interesting-looking events to investigate as well, such as for change data capture (which I covered in my article "Tracking Changes in Your Enterprise Database" in the November 2008 issue of TechNet Magazine), data compression, and index page splits. Index page splits looks like a promising way to work out which indexes are building up performance-sapping fragmentation without the need to periodically run the sys.dm_db_index_physical_stats DMV over all indexes.
Overall, the new Extended Events system allows some pretty sophisticated monitoring that's never been possible before. Although it requires a bit of learning to figure out the XML parsing you'll need to do to get at the data, the benefits of the new system far outweigh the hassle of having to learn some new coding constructs.
I hope this article has given you enough of an overview of Extended Events to get you interested and show you the kinds of things you can do with it. Happy troubleshooting! As always, if you have any feedback or questions, feel free to drop me a line Paul@SQLskills.com.
Paul S. Randal is the Managing Director of SQLskills.com and a SQL Server MVP. He worked on the SQL Server Storage Engine team at Microsoft from 1999 to 2007. Paul wrote DBCC CHECKDB/repair for SQL Server 2005 and was responsible for the Core Storage Engine during SQL Server 2008 development. Paul is an expert on disaster recovery, high availability, and database maintenance, and is a regular presenter at conferences around the world. He blogs at SQLskills.com/blogs/paul.