SQL Server
Understanding Logging and Recovery in SQL Server
Paul S. Randal
At a Glance:
- How logging and recovery function in SQL Server
- How the transaction log works and what you need to know about managing it
- Recovery models and their effect on logging
Contents
What Is Logging?
What Is Recovery?
The Transaction Log
Recovery Models
Wrapping Up
Some of the most misunderstood parts of SQL Server are its logging and recovery mechanisms. The fact that the transaction log exists and can cause problems if not managed correctly seems to confound many "involuntary DBAs." Why is it possible for the transaction log to grow unbounded? Why does it sometimes take so long for the database to come online after a system crash? Why can't logging be turned off completely? Why can't I recover my database properly? Just what is the transaction log and why is it there?
These are all questions I see repeatedly on SQL Server forums and newsgroups, so in this article I want to provide an overview of the logging and recovery system and explain why it is such an integral part of the SQL Server Storage Engine. I will explain the architecture of the transaction log and how the three recovery models available for a database can change the behavior of the transaction log and the logging process itself. Along the way, I'll also provide some links to resources covering transaction log management best practices.
What Is Logging?
Logging and recovery are not concepts that are unique to SQL Server—all commercial relational database management systems (RDBMSs) must have them to support the various ACID properties of transactions. ACID stands for Atomicity, Consistency, Isolation, and Durability, which are the fundamental properties of a transaction-processing system (such as an RDBMS). You can read more about this in the ACID Properties section of the MSDN Library.
Video (no longer available)
Paul Randal demonstrates the importance of managing your transaction log properly in the full recovery model, and he shows you techniques for doing so in SQL Server.
Operations in an RDBMS are logged (or recorded) at the physical and logical level in terms of what happens in the storage structures of the database. Each change to the storage structures has its own log record, which describes the structure being changed and what the change was. This is done in such a way that the change can be replayed or reversed, if necessary. The log records are stored in a special file called the transaction log—I will describe this in more detail later, but for now you can think of it as a sequential-access file.
A set of one or more such changes can be (and in fact, always are) grouped together in a transaction—which provides the basic unit of making changes (atomicity) to a database as far as users, application developers, and DBAs are concerned. A transaction either succeeds (committing) or fails/is canceled (rolling back). In the first case, the operations that form the transaction are guaranteed to be reflected in the database. In the second case, the operations are guaranteed not to be reflected in the database.
Transactions in SQL Server are either explicit or implicit. An explicit transaction is one where the user or application issues a BEGIN TRANSACTION T-SQL statement, signaling the start of a group of related changes by that session. An explicit transaction succeeds when a COMMIT TRANSACTION statement is issued, signaling the successful completion of the group of changes. If a ROLLBACK TRANSACTION statement is issued instead, all changes made by that session since the BEGIN TRANSACTION statement was issued are reverted (rolled back) and the transaction is aborted. A transaction rollback could also be forced by an external event, such as the database running out of disk space or a server crash, as I will explain later.
An implicit transaction is one where the user or application does not explicitly issue a BEGIN TRANSACTION statement before issuing a T-SQL statement. However, given that all changes to the database must be transactional, the Storage Engine will automatically start a transaction under the covers. When the T-SQL statement completes, the Storage Engine automatically commits the transaction that it started to wrap around the user's statement.
You might think that this is not necessary because a single T-SQL statement won't generate a large number of changes to the storage structures of the database, but consider something like an ALTER INDEX REBUILD statement. Although this statement can't be contained within an explicit transaction, it could generate an enormous number of changes to the database. So there must be some mechanism for ensuring that if something does go wrong (the statement is canceled, for instance), all of the changes are properly reversed.
As an example, consider what happens when a single table row is updated in an implicit transaction. Imagine a simple heap table with an integer column c1 and a char column c2. The table has 10,000 rows, and a user submits an update query as follows:
UPDATE SimpleTable SET c1 = 10 WHERE c2 LIKE '%Paul%';
The following operations take place:
- The data pages from SimpleTable are read from disk into memory (the buffer pool) so they can be searched for matching rows. It turns out that three data pages hold five rows that match the WHERE clause predicate.
- The Storage Engine automatically starts an implicit transaction.
- The three data pages and five data rows are locked to allow the updates to occur.
- The changes are made to the five data records on the three data pages in memory.
- The changes are also recorded in log records in the transaction log on disk.
- The Storage Engine automatically commits the implicit transaction.
Note that I didn't list a step where the three updated data pages are written back out to disk. This is because they don't yet need to be; as long as the log records describe the changes are on disk in the transaction log, then the changes are protected. If the pages need to be subsequently read or changed again, then the most up-to-date copy of the page is already in memory, just not on disk (yet). The data pages will be written out to disk when the next checkpoint operation occurs or if the memory that they use in the buffer pool is required for another page image.
Checkpoints exist for two reasons—to batch up write I/Os to improve performance and to reduce the time required for crash recovery. In terms of performance, if a data page were forced out to disk each time it was updated, the number of write I/Os occurring on a busy system could easily overwhelm the I/O subsystem. It's better to periodically write out dirty pages (pages that have been changed since being read from disk) than to write out pages immediately as they are changed. I'll discuss the recovery aspect of checkpoints in a moment.
One common misconception about checkpoints is that they only write out pages with changes from committed transactions. This is not true—a checkpoint always writes out all dirty pages, regardless of whether the transaction that changed a page has committed or not.
Write-ahead logging is the mechanism wherein the log records describing a change are written to disk before the changes themselves are written. It provides the durability part of the ACID properties. As long as the log records describing changes are on disk, in the event of a crash, the log records (and hence the changes themselves) can be recovered and the effects of the transaction are not lost.
What Is Recovery?
Looking for SQL Server Tips?
For tips on SQL Server, visit the TechNet Magazine SQL Server Tips page.
For more Tips on other products, visit the TechNet Magazine Tips index.
Logging exists to support a variety of operations in SQL Server. It ensures that if a crash occurs, a committed transaction will be correctly reflected in the database after the crash. It ensures that an uncommitted transaction will be correctly rolled back and not reflected in the database after a crash. It ensures that it is possible to cancel an in-flight transaction and have all its operations rolled back. It allows a backup copy of the transaction log to be taken so that a database can be restored and the transaction log backups replayed to bring the database to a specific point in time with transactional consistency. And it supports features that rely on reading the transaction log, such as replication, database mirroring, and change data capture.
The majority of these uses of logging involve a mechanism called recovery. Recovery is the process of having the changes described in log records replayed or reverted in the database. Replaying log records is called the REDO (or roll forward) phase of recovery. Reverting log records is called the UNDO (or roll back) phase of recovery. In other words, recovery will make sure that a transaction and all its constituent log records are either redone or undone.
The simple form of recovery is when a single transaction is canceled, in which case it is undone and there is no net effect on the database. The most complex form is crash recovery—when SQL Server crashes (for whatever reason) and the transaction log must be recovered to bring the database to a transactionally consistent point. This means that all transactions that were committed at the time of the crash must be rolled forward to ensure their effects are persisted in the database. And all in-flight transactions that had not committed at the time of the crash must be rolled back to ensure their effects are not persisted in the database.
This is because there is no facility for a transaction in SQL Server to continue after a crash. Thus, if the effects of a partially complete transaction were not rolled back, the database would be left in an inconsistent state (possibly even structurally corrupt, depending on what the transaction was in the middle of doing).
So how does recovery know what to do? All recovery processes depend on the fact that each log record is stamped with a log sequence number (LSN). A log sequence number is an ever-increasing, three-part number that uniquely defines the position of a log record within the transaction log. Each log record in a transaction is stored in sequential order within the transaction log and contains the transaction ID and the LSN of the previous log record for the transaction. In other words, each operation that is recorded as part of the transaction has a "link" back to the operation that immediately preceded it.
For the simple case of a single transaction being rolled back, the recovery mechanism can easily and quickly follow the chain of logged operations from the most recent operation back to the first operation and undo the effects of the operations in the opposite order from which they occurred. The database pages that were affected by the transaction are either still in the buffer pool or on disk. In either case, the image of the page that is available is guaranteed to be one where the effect of the transaction is reflected on the page and must be undone.
During crash recovery, the mechanism is more complicated. The fact that database pages are not written to disk when a transaction commits means that there is no guarantee that the set of database pages on disk accurately reflects the set of changes described in the transaction log—either for committed or uncommitted transactions. However, there is one final piece of the puzzle that I haven't mentioned yet—all database pages have a field in their page header (a 96-byte portion of the 8192-byte page that contains metadata about the page) that contains the LSN of the last log record that affected the page. This allows the recovery system to decide what to do about a particular log record that it must recover:
- For a log record from a committed transaction where the database page has an LSN equal to or greater than the LSN of the log record, nothing needs to be done. The effect of the log record has already been persisted on the page on disk.
- For a log record from a committed transaction where the database page has an LSN less than the LSN of the log record, the log record must be redone to ensure the transaction effects are persisted.
- For a log record from an uncommitted transaction where the database page has an LSN equal to or greater than the LSN of the log record, the log record must be undone to ensure the transaction effects are not persisted.
- For a log record from an uncommitted transaction where the database page has an LSN less than the LSN of the log record, nothing needs to be done. The effect of the log record was not persisted on the page on disk and as such does not need to be undone.
Crash recovery reads through the transaction log and ensures that all effects of all committed transactions are persisted in the database, and all effects of all uncommitted transactions are not persisted in the database—the REDO and UNDO phases, respectively. Once crash recovery completes, the database is transactionally consistent and available for use.
I mentioned earlier that one of the uses of a checkpoint operation is to reduce the amount of time that crash recovery takes. By periodically flushing out all dirty pages to disk, the number of pages that have changed because of committed transactions but whose images are not on disk is reduced. This, in turn, reduces the number of pages that need to have REDO recovery applied during crash recovery.
The Transaction Log
Crash recovery is only possible if the transaction log is intact. In fact, the transaction log is the most important part of the database—it's the only place where all changes to the database are guaranteed to be described in the event of a crash.
If the transaction log is missing or damaged after a crash, then crash recovery cannot complete, leading to a suspect database. In that case, the database must be restored from backups or recovered using less desirable options, such as emergency mode repair. (These procedures are beyond the scope of this article but will be covered in depth in articles later in the year.)
The transaction log is a special file that each database must have to function correctly. It holds the log records that are produced from logging and is used to read them again during recovery (or any of the other uses of logging I've already mentioned). As well as the space occupied by the log records themselves, a transaction will also reserve space in the transaction log for any potential log records required if the transaction were to be canceled and required to roll back. This accounts for the behavior you may observe where, say, a transaction that updates 50MB of data in the database may actually require 100MB of transaction log space.
When a new database is created, the transaction log is essentially empty. As transactions occur, log records are written sequentially to the transaction log, which means there is no performance gain from creating multiple transaction log files—a very common misconception. The transaction log will use each log file in turn.
Log records for concurrent transactions can be interspersed in the transaction log. Remember that log records for a single transaction are linked by their LSNs, so there is no need for all log records for a transaction to be grouped together in the log. LSNs can almost be thought of as a timestamp.
The physical architecture of the transaction log is shown in Figure 1. It is split internally into smaller chunks called virtual log files (or VLFs). These are simply an aid to easier internal management of the transaction log. When a VLF becomes full, logging automatically proceeds to use the next VLF in the transaction log. You might think that eventually the transaction log will run out of space, but this is where the transaction log is so different from data files.
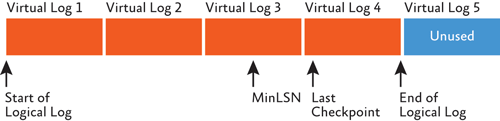
Figure 1 Physical architecture of the transaction log
The transaction log is really a circular file—as long as the log records at the start of the transaction log have been truncated (or cleared). Then when logging reaches the end of the transaction log, it wraps around to the start again and begins overwriting what was there before.
So how do log records get truncated so the space they occupied can be reused? A log record is no longer needed in the transaction log if all of the following are true:
- The transaction of which it is part has committed.
- The database pages it changed have all been written to disk by a checkpoint.
- The log record is not needed for a backup (full, differential, or log).
- The log record is not needed for any feature that reads the log (such as database mirroring or replication).
A log record that is still needed is called active, and a VLF that has at least one active log record is also called active. Every so often, the transaction log is checked to see whether all the log records in a full VLF are active or not; if they are all inactive, the VLF is marked as truncated (meaning the VLF can be overwritten once the transaction log wraps). When a VLF is truncated, it is not overwritten or zeroed in any way—it is just marked as truncated and can then be reused.
This process is called log truncation—not to be confused with actually shrinking the size of the transaction log. Log truncation never changes the physical size of the transaction log—only which portions of the transaction log are active or not. Figure 2 shows the transaction log from Figure 1 after truncation has occurred.
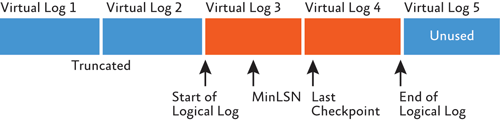
Figure 2 The transaction log after log truncation
Active VLFs make up the logical log—the portion of the transaction log that contains all the active log records. The database itself knows where crash recovery should start reading log records within the active portion of the log—the start of the oldest active transaction in the log, the MinLSN (this is stored in the database boot page).
Crash recovery does not know where to stop reading log records, so it continues until it reaches a zeroed section of the transaction log (if the transaction log has not yet wrapped) or a log record whose parity bits do not fit the sequence from the previous log record.
As VLFs become truncated and new ones become active, the logical log moves within the physical transaction log file and eventually should wrap around to the start again, as shown in Figure 3.
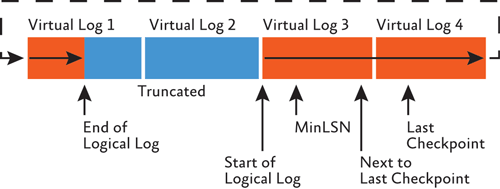
Figure 3 The circular nature of the transaction log
The check whether log truncation can take place under either of the following circumstances:
- When a checkpoint occurs in the SIMPLE recovery model or in other recovery models when a full backup has never been taken. (This implies that a database will remain in a pseudo-SIMPLE recovery model after being switched out of SIMPLE until a full database backup occurs.)
- When a log backup completes.
Remember that log truncation may not be possible because of the many reasons a log record must remain active. When log truncation cannot occur, the VLFs cannot be truncated and eventually the transaction log has to grow (or another transaction log file be added). Excessive transaction log growth can cause performance problems through a phenomenon known as VLF fragmentation. Removing VLF fragmentation can sometimes lead to a dramatic improvement in the performance of log-related activities.
For more information on this, see Kimberly Tripp's blog post "8 Steps to Better Transaction Log Throughput." Kimberly discusses best practices pertaining to transaction log capacity planning, management, and performance improvements—it's well worth reading!
There are two common issues that can prevent log truncation:
- A long-running active transaction. The entire transaction log since the first log record from the oldest active transaction can never be truncated until that transaction commits or aborts.
- Switching to the FULL recovery model, taking a full backup, and then never taking any log backups. The entire transaction log will remain active, waiting to be backed up by a log backup.
For a complete list of factors and instructions on how to determine what is preventing log truncation, see the SQL Server Books Online topic "Factors that Can Delay Log Truncation." I've also created a video demonstration that shows the effect of uncontrolled transaction log growth and how to remove VLF fragmentation—check out this video screencast (and previous screencasts on SQL topics) at technetmagazine.com/videos.
If the transaction log does grow to capacity and cannot grow any further, then error 9002 will be reported and you will need to take steps to provide more space, such as growing the log file, adding another log file, or removing any impediment to the log being truncated.
Under no circumstances should you delete the transaction log, try to rebuild it using undocumented commands, or simply truncate it using the NO_LOG or TRUNCATE_ONLY options of BACKUP LOG (which have been removed in SQL Server 2008). These options will either cause transactional inconsistency (and more than likely corruption) or remove the possibility of being able to properly recover the database.
For more information on how to troubleshoot a full transaction log, check out the Books Online topic "Troubleshooting a Full Transaction Log (Error 9002)."
Recovery Models
As you can see, the behavior of the transaction log depends in part on the recovery model the database is using. There are three recovery models available, and they all have an effect on transaction log behavior or how operations are logged or both.
The FULL recovery model means that every part of every operation is logged, which is called being fully logged. Once a full database backup has been taken in the FULL recovery model, the transaction log will not automatically truncate until a log backup is taken. If you do not want to make use of log backups and the ability to recover a database to a specific point in time, do not use the FULL recovery model. However, if you wish to use database mirroring, then you have no choice, as it only supports the FULL recovery model.
The BULK_LOGGED recovery model has the same transaction log truncation semantics as the FULL recovery model but allows some operations to be partially logged, which is called being minimally logged. Examples are an index rebuild and some bulk-load operations—in the FULL recovery model the entire operation is logged.
But in the BULK_LOGGED recovery model only the allocation changes are logged, which drastically reduces the number of log records produced and, in turn, reduces the potential for transaction log growth. For more information on minimally logged operations, see the Books Online section "Operations that Can Be Minimally Logged."
Finally, the SIMPLE recovery model actually has the same logging behavior as the BULK_LOGGED recovery, but the transaction log truncation semantics are quite different. Log backups are not possible in the SIMPLE recovery model, which means the log can be truncated (as long as nothing else is holding log records active) when a checkpoint occurs. There are pros and cons to each of these recovery models in terms of which backups are possible (or needed) and the ability to recover to various points in time (I will cover this in another article later this year).
Wrapping Up
This article has really been a more academic explanation of how a critical part of SQL Server works. I hope I've managed to clear up any misconceptions you might have had. If this is your first introduction to logging and recovery, these are the key points I'd like you to take away from this article:
- Do not create multiple log files, as it will not lead to a performance gain.
- Be aware of the recovery model your database is using and the effect it has on the transaction log—especially around whether it can automatically truncate or not when a checkpoint occurs.
- Be aware of the potential for transaction log growth, the factors that can lead to it, and how to get it back under control.
- Know where to look for help when troubleshooting a full transaction log.
On my blog, I have a lot more information about the transaction log and factors that affect it—see my blog post category"Transaction Log" for more details. The various Books Online topics concerning the transaction log are also very good—starting with Transaction Log Management.
As always, if you have any feedback or questions, please drop me a line at Paul@SQLskills.com.
Thanks to Kimberly L. Tripp for providing a technical review of this article.
Paul S. Randal is the Managing Director of SQLskills.com and a SQL Server MVP. He worked on the SQL Server Storage Engine team at Microsoft from 1999 to 2007. Paul wrote DBCC CHECKDB/repair for SQL Server 2005 and was responsible for the Core Storage Engine during SQL Server 2008 development. Paul is an expert on disaster recovery, high-availability, and database maintenance and is a regular presenter at conferences around the world. He blogs at SQLskills.com/blogs/paul.