Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Caution
Microsoft retired all classic eDiscovery experiences on August 31, 2025. This retirement includes classic Content Search, classic eDiscovery (Standard), and classic eDiscovery (Premium).
The guidance in this article only applies to organizations hosted in Microsoft 365 operated by 21Vianet (China). If your organization isn't hosted by 21Vianet, use the guidance for the new eDiscovery experience in the Microsoft Purview portal.
After you create a predictive coding model in Microsoft Purview eDiscovery (Premium), the next step is to performing the first training round to train the model on what is relevant and non-relevant content in your review set. After you complete the first round of training, you can perform subsequent training rounds to improve the model's ability to predict relevant and non-relevant content.
To review the predictive coding workflow, see Learn about predictive coding in eDiscovery (Premium)
Before you train a model
- During a training round, label items as Relevant or Not relevant based on the relevancy of the content in the document. Don't base your decision on the values in the metadata fields. For example, for email messages or Teams conversations, don't base your labeling decision on the message participants.
Train a model for the first time
In the Microsoft Purview portal, open an eDiscovery (Premium) case and then select the Review sets tab.
Open a review set and then select Analytics > Manage predictive coding (preview).
On the Predictive coding models (preview) page, select the model that you want to train.
On the Overview tab, under Round 1, select Start next training round.
The Training tab is displayed and contains 50 items for you to label.
Review each document and then select Relevant or Not relevant at the bottom of the reading pane to label it.
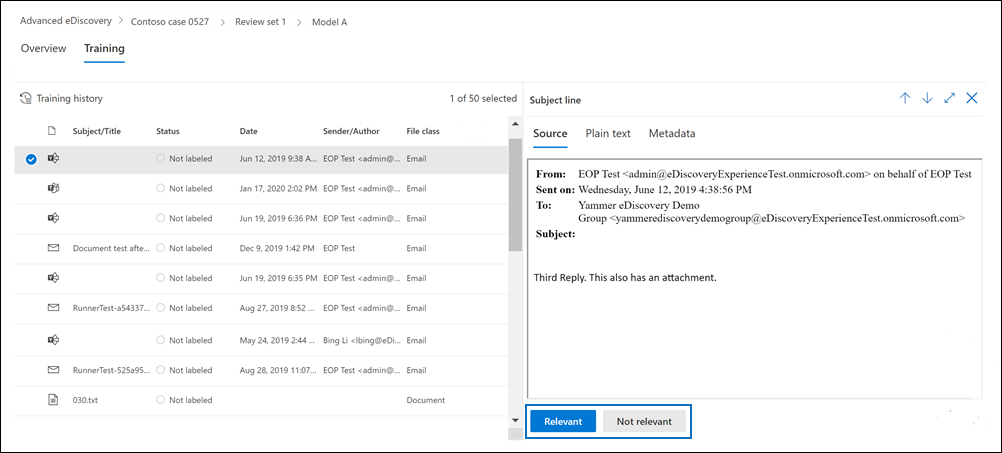
After you've labeled all 50 items, select Finish.
It will take a couple minutes for the system to "learn" from your labeling and update the model. When this process is complete, a status of Ready is displayed for the model on the Predictive coding models (preview) page.
Perform additional training rounds
After you perform the first round of training, you can perform subsequent training rounds by following the steps in the previous section. The only difference is the number of the training round will be updated on the model Overview tab. For example, after performing the first training round, you can select Start next training round to start the second round of training. And so on.
Each round of training (both those in progress and those that are complete) is displayed on the Training tab for the model. When you select a training round, a flyout page with information and metrics for the round is displayed.
What happens after you perform a training round
After you perform the first training round, a job is started that does the following things:
Based on how you labeled the 40 items in the training set, the model learns from your labeling and updates itself to become more accurate.
The model then processes each item in the entire review set and assigns a prediction score between 0 (not relevant) and 1 (relevant).
The model assigns a prediction score to the 10 items in the control set that you labeled during the training round. The model compares the prediction score of these 10 items with the actual label that you assigned to the item during the training round. Based on this comparison, the model identifies the following classification (called the Control set confusion matrix) to assess the model's prediction performance:
| Label | Model predicts item is relevant | Model predicts item is not relevant |
|---|---|---|
| Reviewer labels item as relevant | True positive | False positive |
| Reviewer labels item as not relevant | False negative | True negative |
Based on these comparisons, the model derives values for the F-score, precision, and recall metrics and the margin of error for each one. Scores for these model performance metrics are displayed on a flyout page for the training round. For a description of these metrics, see Predictive coding reference.
- Finally, the model determines the next 50 items that will be used for the next training round. This time, the model might select 20 items from the control set and 30 new items from the review set and designate them as the training set for the next round. The sampling for the next training round is not uniformly sampled. The model will optimize the sampling selection of items from the review set to select items where the prediction is ambiguous, which means the prediction score is in the 0.5 range. This process is known as biased selection.
What happens after you perform subsequent training rounds
After you perform subsequent training rounds (after the first training round), the model does the following things:
- The model is updated based on the labels that you applied to the training set in that round of training.
- The system evaluates the model's prediction score on the items in the control set and check whether the score aligns with how you labeled items in the control set. The evaluation is performed on all labeled items from control set for all training rounds. The results of this evaluation are incorporated in the dashboard on the Overview tab for the model.
- The updated model reprocesses every item in the review set and assign each item an updated prediction score.
Next steps
After you perform the first training round, you can perform more training rounds or apply the model's prediction score filter to the review set to view the items the model has predicted as relevant or not relevant. For more information, see Apply a prediction score filter to a review set.