Vector similarity search with Azure SQL & Azure OpenAI
This example shows how to use Azure OpenAI from Azure SQL database to get the vector embeddings of any choosen text, and then calculate the cosine similarity against the Wikipedia articles (for which vector embeddings have been already calculated,) to find the articles that covers topics that are close - or similar - to the provided text.
For an introduction on text and code embeddings, check out this OpenAI article: Introducing text and code embeddings.
Azure SQL database can be used to significatly speed up vectors operations using column store indexes, so that search can have sub-seconds performances even on large datasets.
Download and import the Wikipedia Article with Vector Embeddings
Download the wikipedia embeddings from here, unzip it and upload it (using Azure Storage Explorer for example) to an Azure Blob Storage container.
In the example the unzipped csv file vector_database_wikipedia_articles_embedded.csv is assumed to be uploaded to a blob container name playground and in a folder named wikipedia.
Once the file is uploaded, get the SAS token to allow Azure SQL database to access it. (From Azure storage Explorer, right click on the playground container and than select Get Shared Access Signature. Set the expiration date to some time in future and then click on "Create". Copy the generated query string somewhere, for example into the Notepad, as it will be needed later)
Use a client tool like Azure Data Studio to connect to an Azure SQL database and then use the ./vector-embeddings/01-import-wikipedia.sql to create the wikipedia_articles_embeddings where the uploaded CSV file will be imported.
Make sure to replace the <account> and <sas-token> placeholders with the value correct for your environment:
<account>is the name of the storage account where the CSV file has been uploaded<sas-token>is the Share Access Signature obtained before
Run each section (each section starts with a comment) separately. At the end of the process (will take up to a couple of minutes) you will have all the CSV data imported in the wikipedia_articles_embeddings table.
Create Vectors Table
In the imported data, vectors are stored as JSON arrays. To take advtange of vector processing, the arrays must be saved into a columnstore index. Thanks to OPENJSON, turning a vector into a set of values that can be saved into a column is very easy:
select
v.id as article_id,
cast(tv.[key] as int) as vector_value_id,
cast(tv.[value] as float) as vector_value
from
[dbo].[wikipedia_articles_embeddings] as v
cross apply
openjson(title_vector) tv
The script ./vector-embeddings/02-create-vectors-table.sql does exactly that. It creates two tables, one for the title embeddings and one for the content embeddings, and the creates a clustered columnstore on those tables to enable efficient vector processing.
Find similar articles by calculating cosine distance
Make sure to have an Azure OpenAI embeddings model deployed and make sure it is using the text-embedding-ada-002 model.
Once the Azure OpenAI model is deployed, it can be called from Azure SQL database using sp_invoke_external_rest_endpoint, to get the embedding vector for the "the foundation series by isaac asimov", text, for example, using the following code (make sure to replace the <your-api-name> and <api-key> with yout Azure OpenAI deployment):
declare @inputText nvarchar(max) = 'the foundation series by isaac asimov';
declare @retval int, @response nvarchar(max);
declare @payload nvarchar(max) = json_object('input': @inputText);
exec @retval = sp_invoke_external_rest_endpoint
@url = 'https://<your-api-name>.openai.azure.com/openai/deployments/<deployment-id>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@headers = '{"api-key":"<api-key>"}',
@payload = @payload,
@response = @response output;
select @response;
The response can be turned into a table using the OPENJSON function again:
select
cast([key] as int) as [vector_value_id],
cast([value] as float) as [vector_value]
into
#t
from
openjson(@response, '$.result.data[0].embedding')
Now is just a matter of taking the vector of the sample text and the vectors of all wikipedia articles and calculate the cosine similarity. The math can be easily expressed in T-SQL:
SUM(v1.[vector_value] * v2.[vector_value]) /
(
SQRT(SUM(v1.[vector_value] * v1.[vector_value]))
*
SQRT(SUM(v2.[vector_value] * v2.[vector_value]))
)
thanks to columnstore, even on small SKU, the performance can be pretty fast, well within the sub-second goal. If you need to use other distance metric, you can find here a description of how to implement the most common one in pure T-SQL: How to calculate common vectors distances in T-SQL
Encapsulating logic to retrieve embeddings
The described process can be wrapped into stored procedures to make it easy to re-use it. The scripts in the ./vector-embeddings/ show how to create a stored procedure to retrieve the embeddings from OpenAI:
03-store-openai-credentials.sql: stores the Azure OpenAI credentials in the Azure SQL database04-create-get-embeddings-procedure.sql: create a stored procedure to encapsulate the call to OpenAI using the script.
Finding similar articles
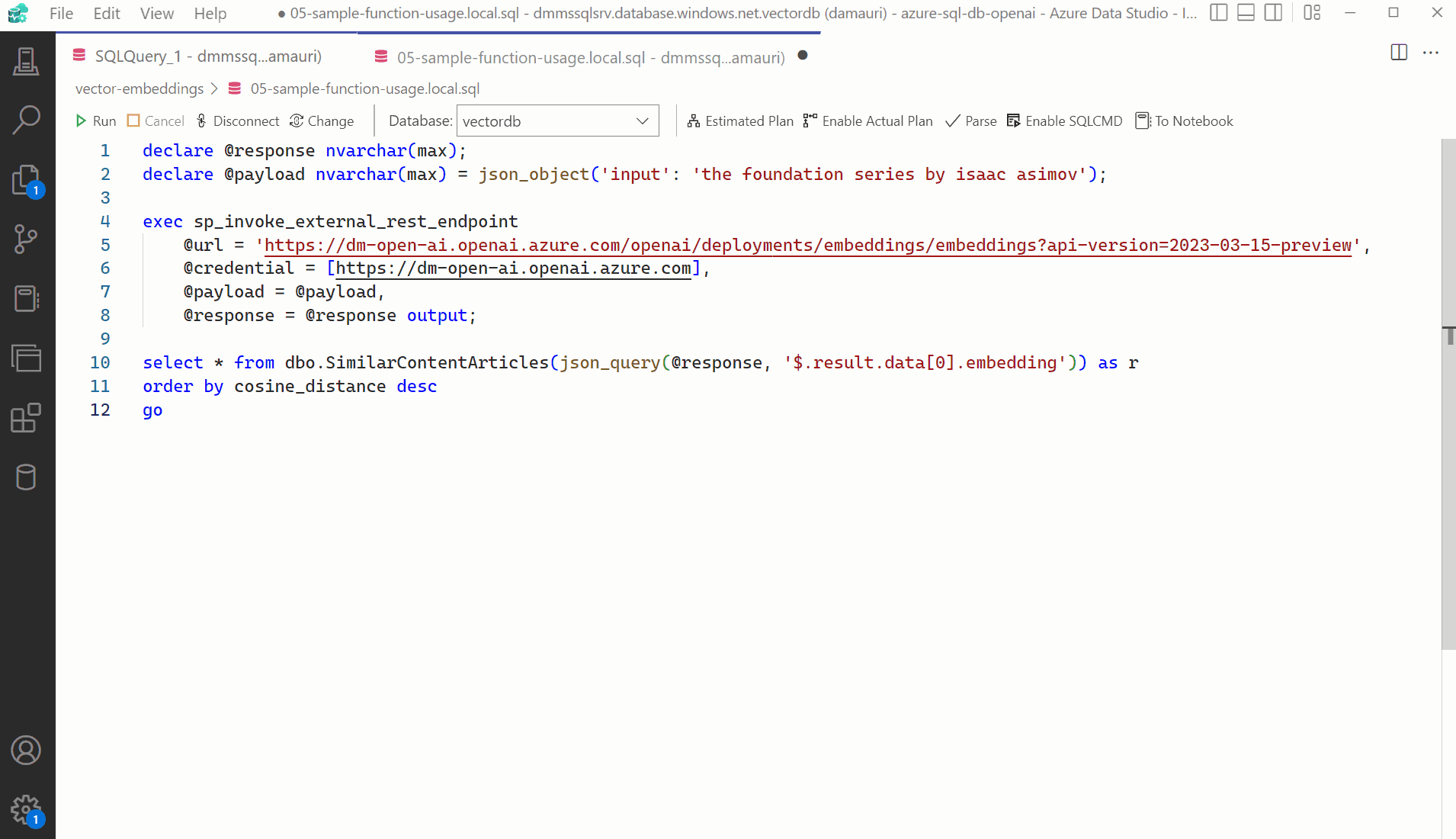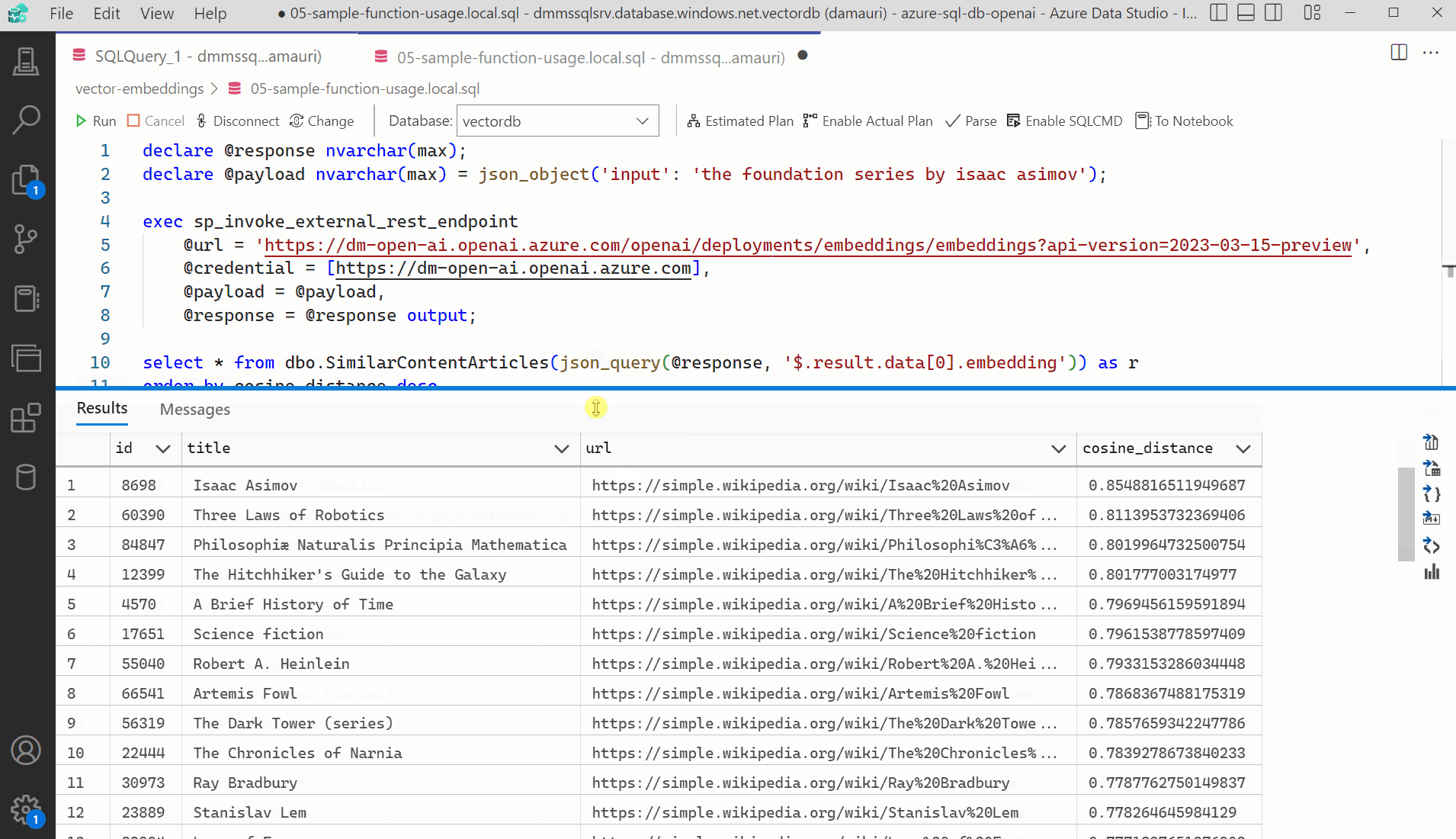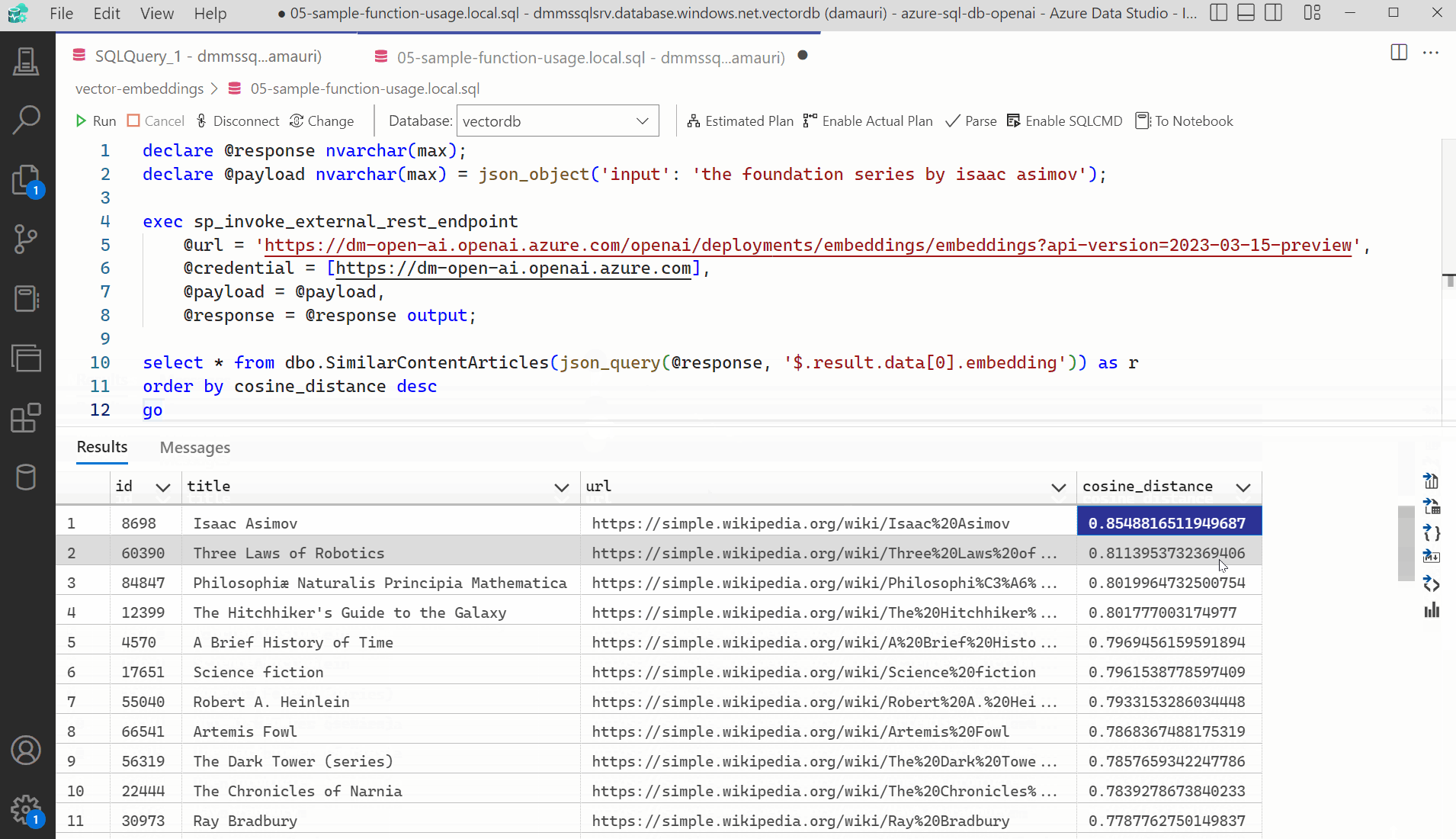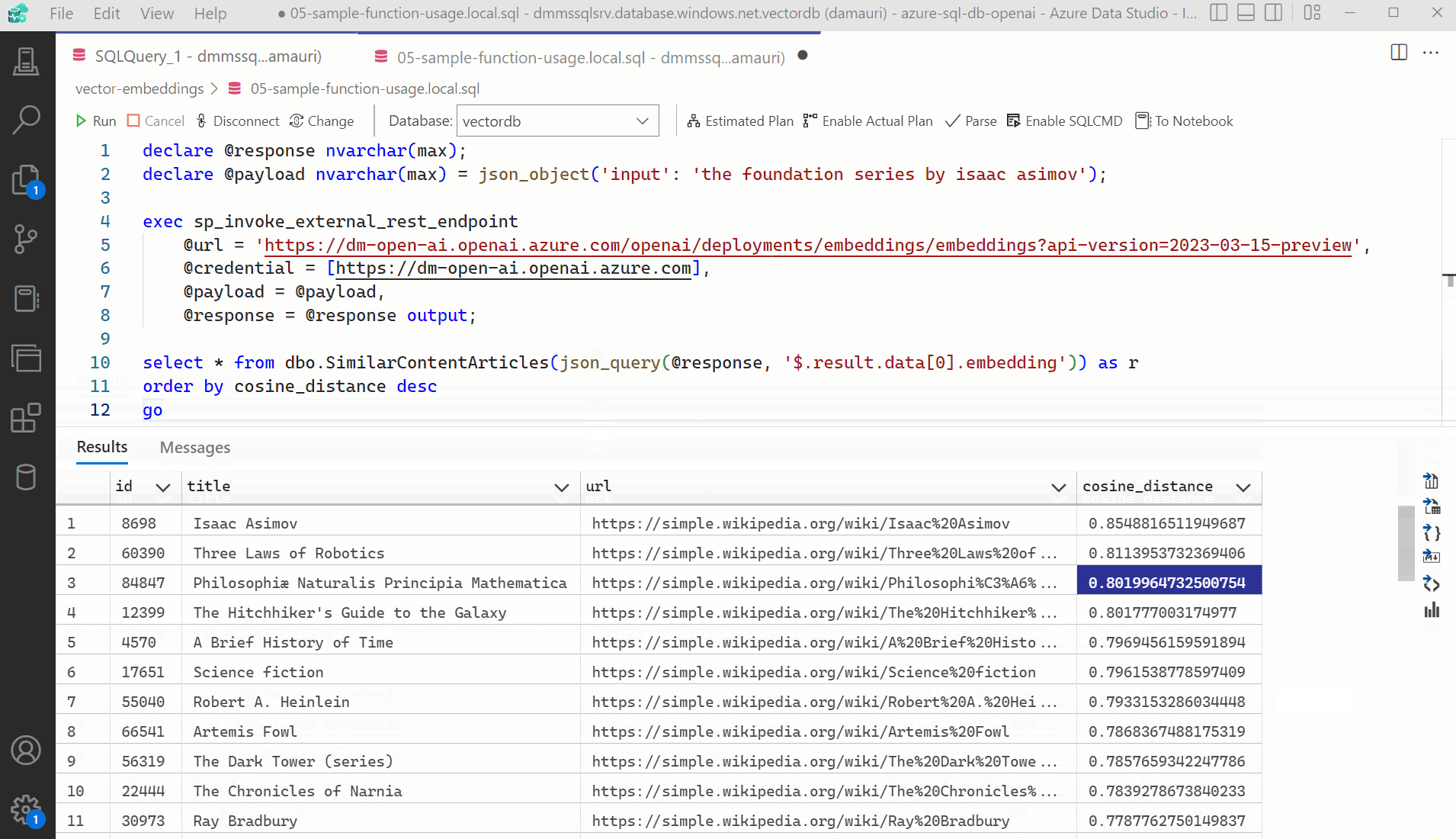
The script 05-find-similar-articles.sql uses the created stored procedure and the process explained above to find similar articles to the provided text.
Encapsulating logic to do similarity search
To make it even easier to use, the script 06-sample-function.sql shows a sample function that can be used to find similar articles by just providing the text, as demonstrated in script 07-sample-function-usage with the following example:
declare @e nvarchar(max);
declare @text nvarchar(max) = N'the foundation series by isaac asimov';
exec dbo.get_embedding 'embeddings', @text, @e output;
select * from dbo.SimilarContentArticles(@e) as r order by cosine_distance desc
Alternative sample with Python and a local embedding model
If you don't want or can't use OpenAI to generate embeddings, you can use a local model like https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1 to generate embeddings. The Python script ./python/hybrid_search.py shows how to
- use Python to generate the embeddings
- do similarity search in Azure SQL database
- use Fulltext search in Azure SQL database with BM25 ranking
- do re-ranking applying Reciprocal Rank Fusion (RRF) to combine the BM25 ranking with the cosine similarity ranking
Make sure to setup the database for this sample using the ./python/00-setup-database.sql script. Database can be either an Azure SQL DB or a SQL Server database.
Conclusions
Azure SQL database, and by extension SQL Server, already has a great support for vector operations thanks to columnstore and its usage of SIMD AVX-512 instructions.
A vector is nothing more than a list numbers (in this scope) and list of numbers can be perfectly stored in a column and even better in a columnstore index. You can start to take advantange of optimized vectors operations right now, directly in Azure SQL database, taking also advantage of all other features that it offers to developers.