Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
By Andrew Marshall, Jugal Parikh, Emre Kiciman and Ram Shankar Siva Kumar
Special Thanks to Raul Rojas and the AETHER Security Engineering Workstream
November 2019
This document is a deliverable of the AETHER Engineering Practices for AI Working Group and supplements existing SDL threat modeling practices by providing new guidance on threat enumeration and mitigation specific to the AI and Machine Learning space. It is intended to be used as a reference during security design reviews of the following:
Products/services interacting with or taking dependencies on AI/ML-based services
Products/services being built with AI/ML at their core
Traditional security threat mitigation is more important than ever. The requirements established by the Security Development Lifecycle are essential to establishing a product security foundation that this guidance builds upon. Failure to address traditional security threats helps enable the AI/ML-specific attacks covered in this document in both the software and physical domains, as well as making compromise trivial lower down the software stack. For an introduction to net-new security threats in this space see Securing the Future of AI and ML at Microsoft.
The skillsets of security engineers and data scientists typically do not overlap. This guidance provides a way for both disciplines to have structured conversations on these net-new threats/mitigations without requiring security engineers to become data scientists or vice versa.
This document is divided into two sections:
- “Key New Considerations in Threat Modeling” focuses on new ways of thinking and new questions to ask when threat modeling AI/ML systems. Both data scientists and security engineers should review this as it will be their playbook for threat modeling discussions and mitigation prioritization.
- “AI/ML-specific Threats and their Mitigations” provides details on specific attacks as well as specific mitigation steps in use today to protect Microsoft products and services against these threats. This section is primarily targeted at data scientists who may need to implement specific threat mitigations as an output of the threat modeling/security review process.
This guidance is organized around an Adversarial Machine Learning Threat Taxonomy created by Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen, and Jeffrey Snover entitled “Failure Modes in Machine Learning.” For incident management guidance on triaging security threats detailed in this document, refer to the SDL Bug Bar for AI/ML Threats. All of these are living documents which will evolve over time with the threat landscape.
Key New Considerations in Threat Modeling: Changing the way you view Trust Boundaries
Assume compromise/poisoning of the data you train from as well as the data provider. Learn to detect anomalous and malicious data entries as well as being able to distinguish between and recover from them
Summary
Training Data stores and the systems that host them are part of your Threat Modeling scope. The greatest security threat in machine learning today is data poisoning because of the lack of standard detections and mitigations in this space, combined with dependence on untrusted/uncurated public datasets as sources of training data. Tracking the provenance and lineage of your data is essential to ensuring its trustworthiness and avoiding a “garbage in, garbage out” training cycle.
Questions to Ask in a Security Review
If your data is poisoned or tampered with, how would you know?
-What telemetry do you have to detect a skew in the quality of your training data?
Are you training from user-supplied inputs?
-What kind of input validation/sanitization are you doing on that content?
-Is the structure of this data documented similar to Datasheets for Datasets?
If you train against online data stores, what steps do you take to ensure the security of the connection between your model and the data?
-Do they have a way of reporting compromises to consumers of their feeds?
-Are they even capable of that?
How sensitive is the data you train from?
-Do you catalog it or control the addition/updating/deletion of data entries?
Can your model output sensitive data?
-Was this data obtained with permission from the source?
Does the model only output results necessary to achieving its goal?
Does your model return raw confidence scores or any other direct output which could be recorded and duplicated?
What is the impact of your training data being recovered by attacking/inverting your model?
If confidence levels of your model output suddenly drop, can you find out how/why, as well as the data that caused it?
Have you defined a well-formed input for your model? What are you doing to ensure inputs meet this format and what do you do if they don’t?
If your outputs are wrong but not causing errors to be reported, how would you know?
Do you know if your training algorithms are resilient to adversarial inputs on a mathematical level?
How do you recover from adversarial contamination of your training data?
-Can you isolate/quarantine adversarial content and re-train impacted models?
-Can you roll back/recover to a model of a prior version for re-training?
Are you using Reinforcement Learning on uncurated public content?
Start thinking about the lineage of your data – were you to find a problem, could you track it to its introduction into the dataset? If not, is that a problem?
Know where your training data comes from and identify statistical norms in order to begin understanding what anomalies look like
-What elements of your training data are vulnerable to outside influence?
-Who can contribute to the data sets you’re training from?
-How would you attack your sources of training data to harm a competitor?
Related Threats and Mitigations in this Document
Adversarial Perturbation (all variants)
Data Poisoning (all variants)
Example Attacks
Forcing benign emails to be classified as spam or causing a malicious example to go undetected
Attacker-crafted inputs that reduce the confidence level of correct classification, especially in high-consequence scenarios
Attacker injects noise randomly into the source data being classified to reduce the likelihood of the correct classification being used in the future, effectively dumbing down the model
Contamination of training data to force the misclassification of select data points, resulting in specific actions being taken or omitted by a system
Identify actions your model(s) or product/service could take which can cause customer harm online or in the physical domain
Summary
Left unmitigated, attacks on AI/ML systems can find their way over to the physical world. Any scenario which can be twisted to psychologically or physically harm users is a catastrophic risk to your product/service. This extends to any sensitive data about your customers used for training and design choices that can leak those private data points.
Questions to Ask in a Security Review
Do you train with adversarial examples? What impact do they have on your model output in the physical domain?
What does trolling look like to your product/service? How can you detect and respond to it?
What would it take to get your model to return a result that tricks your service into denying access to legitimate users?
What is the impact of your model being copied/stolen?
Can your model be used to infer membership of an individual person in a particular group, or simply in the training data?
Can an attacker cause reputational damage or PR backlash to your product by forcing it to carry out specific actions?
How do you handle properly formatted but overtly biased data, such as from trolls?
For each way to interact with or query your model is exposed, can that method be interrogated to disclose training data or model functionality?
Related Threats and Mitigations in this Document
Membership Inference
Model Inversion
Model Stealing
Example Attacks
Reconstruction and extraction of training data by repeatedly querying the model for maximum confidence results
Duplication of the model itself by exhaustive query/response matching
Querying the model in a way that reveals a specific element of private data was included in the training set
Self-driving car being tricked to ignore stop signs/traffic lights
Conversational bots manipulated to troll benign users
Identify all sources of AI/ML dependencies as well as frontend presentation layers in your data/model supply chain
Summary
Many attacks in AI and Machine Learning begin with legitimate access to APIs which are surfaced to provide query access to a model. Because of the rich sources of data and rich user experiences involved here, authenticated but “inappropriate” (there’s a gray area here) 3rd-party access to your models is a risk because of the ability to act as a presentation layer above a Microsoft-provided service.
Questions to Ask in a Security Review
Which customers/partners are authenticated to access your model or service APIs?
-Can they act as a presentation layer on top of your service?
-Can you revoke their access promptly in case of compromise?
-What is your recovery strategy in the event of malicious use of your service or dependencies?
Can a 3rd party build a façade around your model to re-purpose it and harm Microsoft or its customers?
Do customers provide training data to you directly?
-How do you secure that data?
-What if it’s malicious and your service is the target?
What does a false-positive look like here? What is the impact of a false-negative?
Can you track and measure deviation of True Positive vs False Positive rates across multiple models?
What kind of telemetry do you need to prove the trustworthiness of your model output to your customers?
Identify all 3rd party dependencies in your ML/Training data supply chain – not just open source software, but data providers as well
-Why are you using them and how do you verify their trustworthiness?
Are you using pre-built models from 3rd parties or submitting training data to 3rd party MLaaS providers?
Inventory news stories about attacks on similar products/services. Understanding that many AI/ML threats transfer between model types, what impact would these attacks have on your own products?
Related Threats and Mitigations in this Document
Neural Net Reprogramming
Adversarial Examples in the physical domain
Malicious ML Providers Recovering Training Data
Attacking the ML Supply Chain
Backdoored Model
Compromised ML-specific dependencies
Example Attacks
Malicious MLaaS provider trojans your model with a specific bypass
Adversary customer finds vulnerability in common OSS dependency you use, uploads crafted training data payload to compromise your service
Unscrupulous partner uses facial recognition APIs and creates a presentation layer over your service to produce Deep Fakes.
AI/ML-specific Threats and their Mitigations
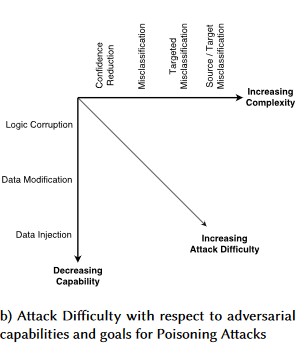
#1: Adversarial Perturbation
Description
In perturbation-style attacks, the attacker stealthily modifies the query to get a desired response from a production-deployed model[1]. This is a breach of model input integrity which leads to fuzzing-style attacks where the end result isn’t necessarily an access violation or EOP, but instead compromises the model’s classification performance. This can also be manifested by trolls using certain target words in a way that the AI will ban them, effectively denying service to legitimate users with a name matching a “banned” word.
 [24]
[24]
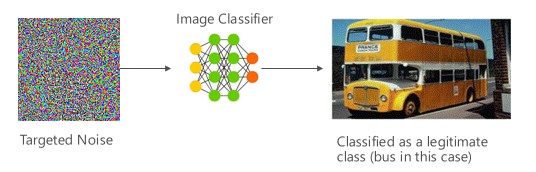
Variant #1a: Targeted misclassification
In this case attackers generate a sample that is not in the input class of the target classifier but gets classified by the model as that particular input class. The adversarial sample can appear like random noise to human eyes but attackers have some knowledge of the target machine learning system to generate a white noise that is not random but is exploiting some specific aspects of the target model. The adversary gives an input sample that is not a legitimate sample, but the target system classifies it as a legitimate class.
Examples
 [6]
[6]
Mitigations
Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training [19]: The authors propose Highly Confident Near Neighbor (HCNN), a framework that combines confidence information and nearest neighbor search, to reinforce adversarial robustness of a base model. This can help distinguish between right and wrong model predictions in a neighborhood of a point sampled from the underlying training distribution.
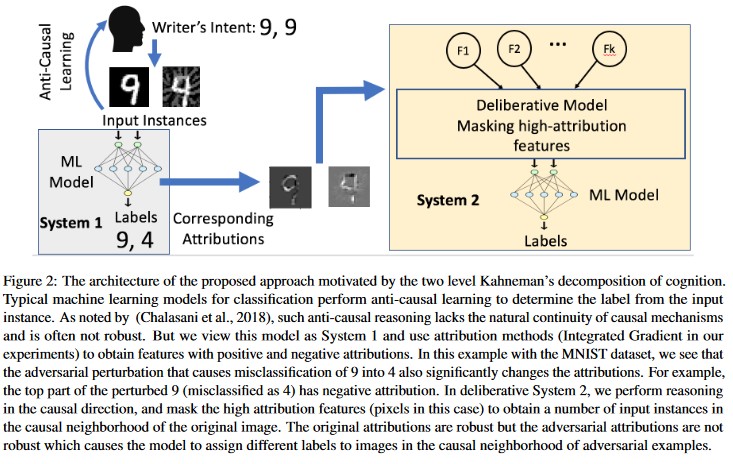
Attribution-driven Causal Analysis [20]: The authors study the connection between the resilience to adversarial perturbations and the attribution-based explanation of individual decisions generated by machine learning models. They report that adversarial inputs are not robust in attribution space, that is, masking a few features with high attribution leads to change indecision of the machine learning model on the adversarial examples. In contrast, the natural inputs are robust in attribution space.
 [20]
[20]
These approaches can make machine learning models more resilient to adversarial attacks because fooling this two-layer cognition system requires not only attacking the original model but also ensuring that the attribution generated for the adversarial example is similar to the original examples. Both the systems must be simultaneously compromised for a successful adversarial attack.
Traditional Parallels
Remote Elevation of Privilege since attacker is now in control of your model
Severity
Critical
Variant #1b: Source/Target misclassification
This is characterized as an attempt by an attacker to get a model to return their desired label for a given input. This usually forces a model to return a false positive or false negative. The end result is a subtle takeover of the model’s classification accuracy, whereby an attacker can induce specific bypasses at will.
While this attack has a significant detrimental impact to classification accuracy, it can also be more time-intensive to carry out given that an adversary must not only manipulate the source data so that it is no longer labeled correctly, but also labeled specifically with the desired fraudulent label. These attacks often involve multiple steps/attempts to force misclassification [3]. If the model is susceptible to transfer learning attacks which force targeted misclassification, there may be no discernable attacker traffic footprint as the probing attacks can be carried out offline.
Examples
Forcing benign emails to be classified as spam or causing a malicious example to go undetected. These are also known as model evasion or mimicry attacks.
Mitigations
Reactive/Defensive Detection Actions
- Implement a minimum time threshold between calls to the API providing classification results. This slows down multi-step attack testing by increasing the overall amount of time required to find a success perturbation.
Proactive/Protective Actions
Feature Denoising for Improving Adversarial Robustness [22]: The authors develop a new network architecture that increase adversarial robustness by performing feature denoising. Specifically, the networks contain blocks that denoise the features using non-local means or other filters; the entire networks are trained end-to-end. When combined with adversarial training, the feature denoising networks substantially improve the state-of-the-art in adversarial robustness in both white-box and black-box attack settings.
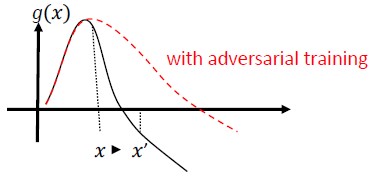
Adversarial Training and Regularization: Train with known adversarial samples to build resilience and robustness against malicious inputs. This can also be seen as a form of regularization, which penalizes the norm of input gradients and makes the prediction function of the classifier smoother (increasing the input margin). This includes correct classifications with lower confidence rates.
Invest in developing monotonic classification with selection of monotonic features. This ensures that the adversary will not be able to evade the classifier by simply padding features from the negative class [13].
Feature squeezing [18] can be used to harden DNN models by detecting adversarial examples. It reduces the search space available to an adversary by coalescing samples that correspond to many different feature vectors in the original space into a single sample. By comparing a DNN model’s prediction on the original input with that on the squeezed input, feature squeezing can help detect adversarial examples. If the original and squeezed examples produce substantially different outputs from the model, the input is likely to be adversarial. By measuring the disagreement among predictions and selecting a threshold value, system can output the correct prediction for legitimate examples and rejects adversarial inputs.

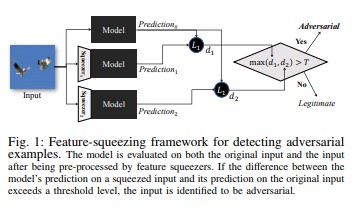 [18]
[18]Certified Defenses against Adversarial Examples [22]: The authors propose a method based on a semi-definite relaxation that outputs a certificate that for a given network and test input, no attack can force the error to exceed a certain value. Second, as this certificate is differentiable, authors jointly optimize it with the network parameters, providing an adaptive regularizer that encourages robustness against all attacks.
Response Actions
- Issue alerts on classification results with high variance between classifiers, especially if from a single user or small group of users.
Traditional Parallels
Remote Elevation of Privilege
Severity
Critical
Variant #1c: Random misclassification
This is a special variation where the attacker’s target classification can be anything other than the legitimate source classification. The attack generally involves injection of noise randomly into the source data being classified to reduce the likelihood of the correct classification being used in the future [3].
Examples
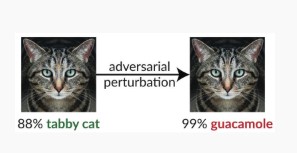
Mitigations
Same as Variant 1a.
Traditional Parallels
Non-persistent denial of service
Severity
Important
Variant #1d: Confidence Reduction
An attacker can craft inputs to reduce the confidence level of correct classification, especially in high-consequence scenarios. This can also take the form of a large number of false positives meant to overwhelm administrators or monitoring systems with fraudulent alerts indistinguishable from legitimate alerts [3].
Examples

Mitigations
- In addition to the actions covered in Variant #1a, event throttling can be employed to reduce the volume of alerts from a single source.
Traditional Parallels
Non-persistent denial of service
Severity
Important
#2a Targeted Data Poisoning
Description
The goal of the attacker is to contaminate the machine model generated in the training phase, so that predictions on new data will be modified in the testing phase[1]. In targeted poisoning attacks, the attacker wants to misclassify specific examples to cause specific actions to be taken or omitted.
Examples
Submitting AV software as malware to force its misclassification as malicious and eliminate the use of targeted AV software on client systems.
Mitigations
Define anomaly sensors to look at data distribution on day to day basis and alert on variations
-Measure training data variation on daily basis, telemetry for skew/drift
Input validation, both sanitization and integrity checking
Poisoning injects outlying training samples. Two main strategies for countering this threat:
-Data Sanitization/ validation: remove poisoning samples from training data -Bagging for fighting poisoning attacks [14]
-Reject-on-Negative-Impact (RONI) defense [15]
-Robust Learning: Pick learning algorithms that are robust in the presence of poisoning samples.
-One such approach is described in [21] where authors address the problem of data poisoning in two steps: 1) introducing a novel robust matrix factorization method to recover the true subspace, and 2) novel robust principle component regression to prune adversarial instances based on the basis recovered in step (1). They characterize necessary and sufficient conditions for successfully recovering the true subspace and present a bound on expected prediction loss compared to ground truth.
Traditional Parallels
Trojaned host whereby attacker persists on the network. Training or config data is compromised and being ingested/trusted for model creation.
Severity
Critical
#2b Indiscriminate Data Poisoning
Description
Goal is to ruin the quality/integrity of the data set being attacked. Many datasets are public/untrusted/uncurated, so this creates additional concerns around the ability to spot such data integrity violations in the first place. Training on unknowingly compromised data is a garbage-in/garbage-out situation. Once detected, triage needs to determine the extent of data that has been breached and quarantine/retrain.
Examples
A company scrapes a well-known and trusted website for oil futures data to train their models. The data provider’s website is subsequently compromised via SQL Injection attack. The attacker can poison the dataset at will and the model being trained has no notion that the data is tainted.
Mitigations
Same as variant 2a.
Traditional Parallels
Authenticated Denial of service against a high-value asset
Severity
Important
#3 Model Inversion Attacks
Description
The private features used in machine learning models can be recovered [1]. This includes reconstructing private training data that the attacker does not have access to. Also known as hill climbing attacks in the biometric community [16, 17] This is accomplished by finding the input which maximizes the confidence level returned, subject to the classification matching the target [4].
Examples
 [4]
[4]
Mitigations
Interfaces to models trained from sensitive data need strong access control.
Rate-limit queries allowed by model
Implement gates between users/callers and the actual model by performing input validation on all proposed queries, rejecting anything not meeting the model’s definition of input correctness and returning only the minimum amount of information needed to be useful.
Traditional Parallels
Targeted, covert Information Disclosure
Severity
This defaults to important per the standard SDL bug bar, but sensitive or personally identifiable data being extracted would raise this to critical.
#4 Membership Inference Attack
Description
The attacker can determine whether a given data record was part of the model’s training dataset or not[1]. Researchers were able to predict a patient’s main procedure (e.g: Surgery the patient went through) based on the attributes (e.g: age, gender, hospital) [1].
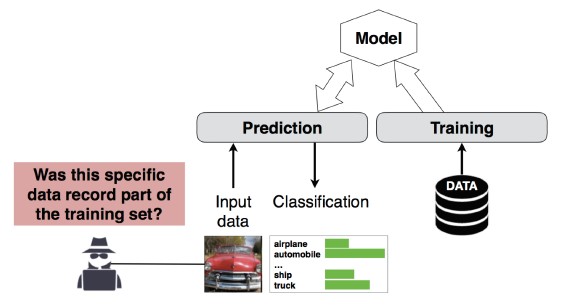 [12]
[12]
Mitigations
Research papers demonstrating the viability of this attack indicate Differential Privacy [4, 9] would be an effective mitigation. This is still a nascent field at Microsoft and AETHER Security Engineering recommends building expertise with research investments in this space. This research would need to enumerate Differential Privacy capabilities and evaluate their practical effectiveness as mitigations, then design ways for these defenses to be inherited transparently on our online services platforms, similar to how compiling code in Visual Studio gives you on-by-default security protections which are transparent to the developer and users.
The usage of neuron dropout and model stacking can be effective mitigations to an extent. Using neuron dropout not only increases resilience of a neural net to this attack, but also increases model performance [4].
Traditional Parallels
Data Privacy. Inferences are being made about a data point’s inclusion in the training set but the training data itself is not being disclosed
Severity
This is a privacy issue, not a security issue. It is addressed in threat modeling guidance because the domains overlap, but any response here would be driven by Privacy, not Security.
#5 Model Stealing
Description
The attackers recreate the underlying model by legitimately querying the model. The functionality of the new model is same as that of the underlying model[1]. Once the model is recreated, it can be inverted to recover feature information or make inferences on training data.
Equation solving – For a model that returns class probabilities via API output, an attacker can craft queries to determine unknown variables in a model.
Path Finding – an attack that exploits API particularities to extract the ‘decisions’ taken by a tree when classifying an input [7].
Transferability attack - An adversary can train a local model—possibly by issuing prediction queries to the targeted model - and use it to craft adversarial examples that transfer to the target model [8]. If your model is extracted and discovered vulnerable to a type of adversarial input, new attacks against your production-deployed model can be developed entirely offline by the attacker who extracted a copy of your model.
Examples
In settings where an ML model serves to detect adversarial behavior, such as identification of spam, malware classification, and network anomaly detection, model extraction can facilitate evasion attacks [7].
Mitigations
Proactive/Protective Actions
Minimize or obfuscate the details returned in prediction APIs while still maintaining their usefulness to “honest” applications [7].
Define a well-formed query for your model inputs and only return results in response to completed, well-formed inputs matching that format.
Return rounded confidence values. Most legitimate callers do not need multiple decimal places of precision.
Traditional Parallels
Unauthenticated, read-only tampering of system data, targeted high-value information disclosure?
Severity
Important in security-sensitive models, Moderate otherwise
#6 Neural Net Reprogramming
Description
By means of a specially crafted query from an adversary, Machine learning systems can be reprogrammed to a task that deviates from the creator’s original intent [1].
Examples
Weak access controls on a facial recognition API enabling 3rd parties to incorporate into apps designed to harm Microsoft customers, such as a deep fakes generator.
Mitigations
Strong client<->server mutual authentication and access control to model interfaces
Takedown of the offending accounts.
Identify and enforce a service-level agreement for your APIs. Determine the acceptable time-to-fix for an issue once reported and ensure the issue no longer repros once SLA expires.
Traditional Parallels
This is an abuse scenario. You're less likely to open a security incident on this than you are to simply disable the offender’s account.
Severity
Important to Critical
#7 Adversarial Example in the Physical domain (bits->atoms)
Description
An adversarial example is an input/query from a malicious entity sent with the sole aim of misleading the machine learning system [1]
Examples
These examples can manifest in the physical domain, like a self-driving car being tricked into running a stop sign because of a certain color of light (the adversarial input) being shone on the stop sign, forcing the image recognition system to no longer see the stop sign as a stop sign.
Traditional Parallels
Elevation of Privilege, remote code execution
Mitigations
These attacks manifest themselves because issues in the machine learning layer (the data & algorithm layer below AI-driven decisionmaking) were not mitigated. As with any other software *or* physical system, the layer below the target can always be attacked through traditional vectors. Because of this, traditional security practices are more important than ever, especially with the layer of unmitigated vulnerabilities (the data/algo layer) being used between AI and traditional software.
Severity
Critical
#8 Malicious ML providers who can recover training data
Description
A malicious provider presents a backdoored algorithm, wherein the private training data is recovered. They were able to reconstruct faces and texts, given the model alone.
Traditional Parallels
Targeted information disclosure
Mitigations
Research papers demonstrating the viability of this attack indicate Homomorphic Encryption would be an effective mitigation. This is an area with little current investment at Microsoft and AETHER Security Engineering recommends building expertise with research investments in this space. This research would need to enumerate Homomorphic Encryption tenets and evaluate their practical effectiveness as mitigations in the face of malicious ML-as-a-Service providers.
Severity
Important if data is PII, Moderate otherwise
#9 Attacking the ML Supply Chain
Description
Owing to large resources (data + computation) required to train algorithms, the current practice is to reuse models trained by large corporations and modify them slightly for task at hand (e.g: ResNet is a popular image recognition model from Microsoft). These models are curated in a Model Zoo (Caffe hosts popular image recognition models). In this attack, the adversary attacks the models hosted in Caffe, thereby poisoning the well for anyone else. [1]
Traditional Parallels
Compromise of third-party non-security dependency
App store unknowingly hosting malware
Mitigations
Minimize 3rd-party dependencies for models and data where possible.
Incorporate these dependencies into your threat modeling process.
Leverage strong authentication, access control and encryption between 1st/3rd-party systems.
Severity
Critical
#10 Backdoor Machine Learning
Description
The training process is outsourced to a malicious 3rd party who tampers with training data and delivered a trojaned model which forces targeted mis-classifications, such as classifying a certain virus as non-malicious[1]. This is a risk in ML-as-a-Service model-generation scenarios.
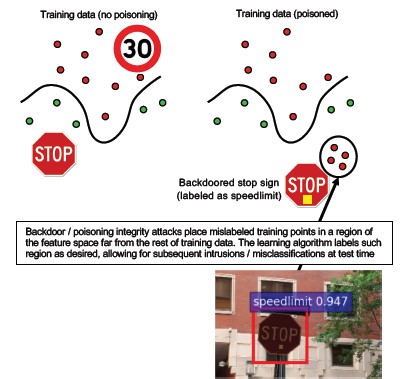 [12]
[12]
Traditional Parallels
Compromise of third-party security dependency
Compromised Software Update mechanism
Certificate Authority compromise
Mitigations
Reactive/Defensive Detection Actions
- The damage is already done once this threat has been discovered, so the model and any training data provided by the malicious provider cannot be trusted.
Proactive/Protective Actions
Train all sensitive models in-house
Catalog training data or ensure it comes from a trusted third party with strong security practices
Threat model the interaction between the MLaaS provider and your own systems
Response Actions
- Same as for compromise of external dependency
Severity
Critical
#11 Exploit software dependencies of the ML system
Description
In this attack, the attacker does NOT manipulate the algorithms. Instead, exploits software vulnerabilities such as buffer overflows or cross-site scripting[1]. It is still easier to compromise software layers beneath AI/ML than attack the learning layer directly, so traditional security threat mitigation practices detailed in the Security Development Lifecycle are essential.
Traditional Parallels
Compromised Open Source Software Dependency
Web server vulnerability (XSS, CSRF, API input validation failure)
Mitigations
Work with your security team to follow applicable Security Development Lifecycle/Operational Security Assurance best practices.
Severity
Variable; Up to Critical depending on the type of traditional software vulnerability.
Bibliography
[1] Failure Modes in Machine Learning, Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen, and Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Adversarial Examples in Deep Learning: Characterization and Divergence, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha, and T. Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures,” in Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Adversarial Examples in Machine Learning AIWTB 2017
[7] Stealing Machine Learning Models via Prediction APIs, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] The Space of Transferable Adversarial Examples, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh , and Patrick McDaniel
[9] Understanding Membership Inferences on Well-Generalized Learning Models Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 , and Kai Chen3,4
[10] Simon-Gabriel et al., Adversarial vulnerability of neural networks increases with input dimension, ArXiv 2018;
[11] Lyu et al., A unified gradient regularization family for adversarial examples, ICDM 2015
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto, and Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks
[15] An Improved Reject on Negative Impact Defense Hongjiang Li and Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. 5th Int’l Conf. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. 2018 Network and Distributed System Security Symposium. 18-21 February.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robust Linear Regression Against Training Data Poisoning – Chang Liu et al.
[22] Feature Denoising for Improving Adversarial Robustness, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certified Defenses against Adversarial Examples - Aditi Raghunathan, Jacob Steinhardt, Percy Liang