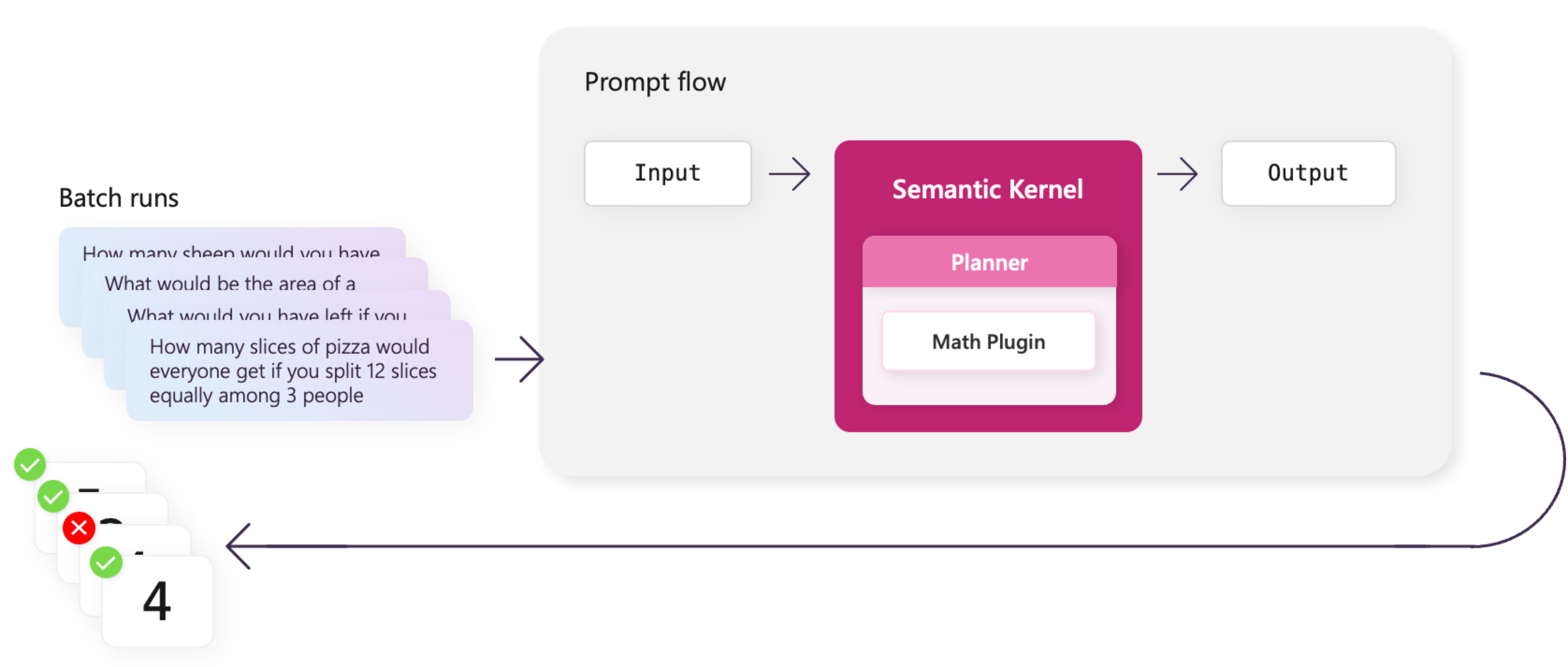
Evaluate your plugins and planners with Prompt flow
With the minimal amount of data we provided, we can easily view the results and see that there are some errors. If you have a large amount of data, however, it can be difficult to evaluate the results. This is where Prompt flow's evaluation feature comes in handy.
By the end of this article, you'll learn how to run an evaluation flow to quantify how well your plugins and planners are performing so that you can iterate on your descriptions and hints to improve your results.
This article uses the completed solution from the preview article. If you want to follow along, you can use the following samples in the public documentation repository. You will also need an initial batch run to evaluate. If you haven't already, you can follow the steps in the previous article to create a batch run.
Note
Today Prompt flow is only available in Python, so this article will only show how to use Prompt flow to evaluate plugins using Python.
| Language | Link to previous solution | Link to completed solution |
|---|---|---|
| C# | N/A | Not available |
| Java | N/A | Not available |
| Python | Open solution in GitHub | Open solution in GitHub |
Using an evaluation flow
In this guide, we'll use one of the existing sample evaluation flows in the Prompt flow GitHub repo. With the eval-accuracy-maths-to-code we can easily evaluate our results and see how well our flow is performing.
Download the eval-accuracy-maths-to-code flow from the Prompt flow GitHub repo.
Copy the path to the eval-accuracy-maths-to-code folder.
Navigate to the root of the flow folder.
cd ./perform_mathRun the following command in your terminal after replacing
<path-to-evaluation-flow>with the path to the eval-accuracy-maths-to-code folder.Note
This command assumes the previous batch run was named
perform_math. If you named your batch run something else, you will need to update the--runparameter.pf run create --flow <path-to-evaluation-flow> --data ./data.jsonl --column-mapping groundtruth='${data.groundtruth}' prediction='${run.outputs.result}' --run perform_math --stream --name perform_math_evalThis command will take the original benchmark data and the results from the batch run and create a new run that contains the evaluation results. The
--column-mappingparameter tells Prompt flow which columns to use for the ground truth and the prediction. By using the--nameparameter, we can reference it later when we want to view the results.Run the following command to view the metrics of the evaluation.
pf run show-metrics -n perform_math_evalYou should see results similar to the following:
With GPT-3.5-turbo, you should expect to see a low accuracy and a high error rate.
{ "accuracy": 0.6, "error_rate": 0.2 }
Improving your flow with prompt engineering
Once you have a baseline for how well your flow is performing, you can start to improve your descriptions. If you run the following command, you can see which inputs are causing the issues.
pf run show-details -n perform_math_eval
Below is a sample of the results you should see. With this view it's easier to which benchmarks are failing.
+----+----------------------+---------------------+----------------------+-----------------+
| | inputs.groundtruth | inputs.prediction | inputs.line_number | outputs.score |
+====+======================+=====================+======================+=================+
| 0 | 5 | 5.0 | 0 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 1 | 6 | 2.449489742783178 | 1 | 0 |
+----+----------------------+---------------------+----------------------+-----------------+
| 2 | -1 | | 2 | -1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 3 | 4 | (Failed) | 3 | -1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 4 | 8 | 5.000000000000007 | 4 | 0 |
+----+----------------------+---------------------+----------------------+-----------------+
| 5 | 3 | 3.0 | 5 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 6 | 24 | 24.0 | 6 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 7 | 4 | 4.0 | 7 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 8 | 49 | 49.0 | 8 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
| 9 | 9 | 9.0 | 9 | 1 |
+----+----------------------+---------------------+----------------------+-----------------+
Both GPT-3.5-Turbo and GPT-4 have challenges with the third benchmark What would you have left if you spent $3 when you only had $2 to begin with?. This particular benchmark is challenging because it's asking to subtract a larger number from a smaller number to get a negative value. This is something that the planner doesn't know how to easily do.
Improving the descriptions of your plugin
We can fix the issue by improving the description of the subtract function and its input parameters in the math plugin. Below we have updated the description of the subtract function to let the planner know how it can handle negative numbers. We've also updated the inputs to reference the mathematical names of the properties (i.e., minuend and subtrahend).
@sk_function(
description="Subtract two numbers. If you expect a negative result, the minuend should be the smaller number.",
name="Subtract",
)
@sk_function_context_parameter(
name="input",
description="The number to subtract from (i.e., minuend)",
)
@sk_function_context_parameter(
name="subtrahend",
description="The number to subtract away from the input",
)
def subtract(self, context: SKContext) -> str:
return str(float(context["input"]) - float(context["subtrahend"]))
In the final solution, we've also improved the descriptions of some of the other functions to make them more clear to the planner. Check out the math plugin in the final solution and try to see if you can find all the improvements.
Giving the planner more help
Additionally, we can provide the planner with more guidance on achieving the desired result by adding hints to the original ask. To do so, update the value of the ask in the math_planner.py file to include the following hints.
"chat_completion",
AzureChatCompletion(
deployment_name,
endpoint=AzureOpenAIConnection.api_base,
Re-evaluate your flow
Now that we've updated our descriptions and hints, we can re-evaluate our flow to see if it's improved.
Navigate to the root of the flow folder.
cd ./perform_mathRun the following command to re-run the batch.
pf run create --flow . --data ./data.jsonl --stream --name perform_math_v2Run the following command to evaluate the new results. Remember to replace
<path-to-evaluation-flow>with the path to the eval-accuracy-maths-to-code folder.pf run create --flow <path-to-evaluation-flow> --data ./data.jsonl --column-mapping groundtruth='${data.groundtruth}' prediction='${run.outputs.result}' --run perform_math_v2 --stream --name perform_math_eval_v2Run the following command to see the metrics of the evaluation.
pf run show-metrics -n perform_math_eval_v2You should now see even better results than before.
While not perfect, GPT-3.5-turbo should now have a higher accuracy and much lower error rate.
{ "accuracy": 0.8, "error_rate": 0.0 }
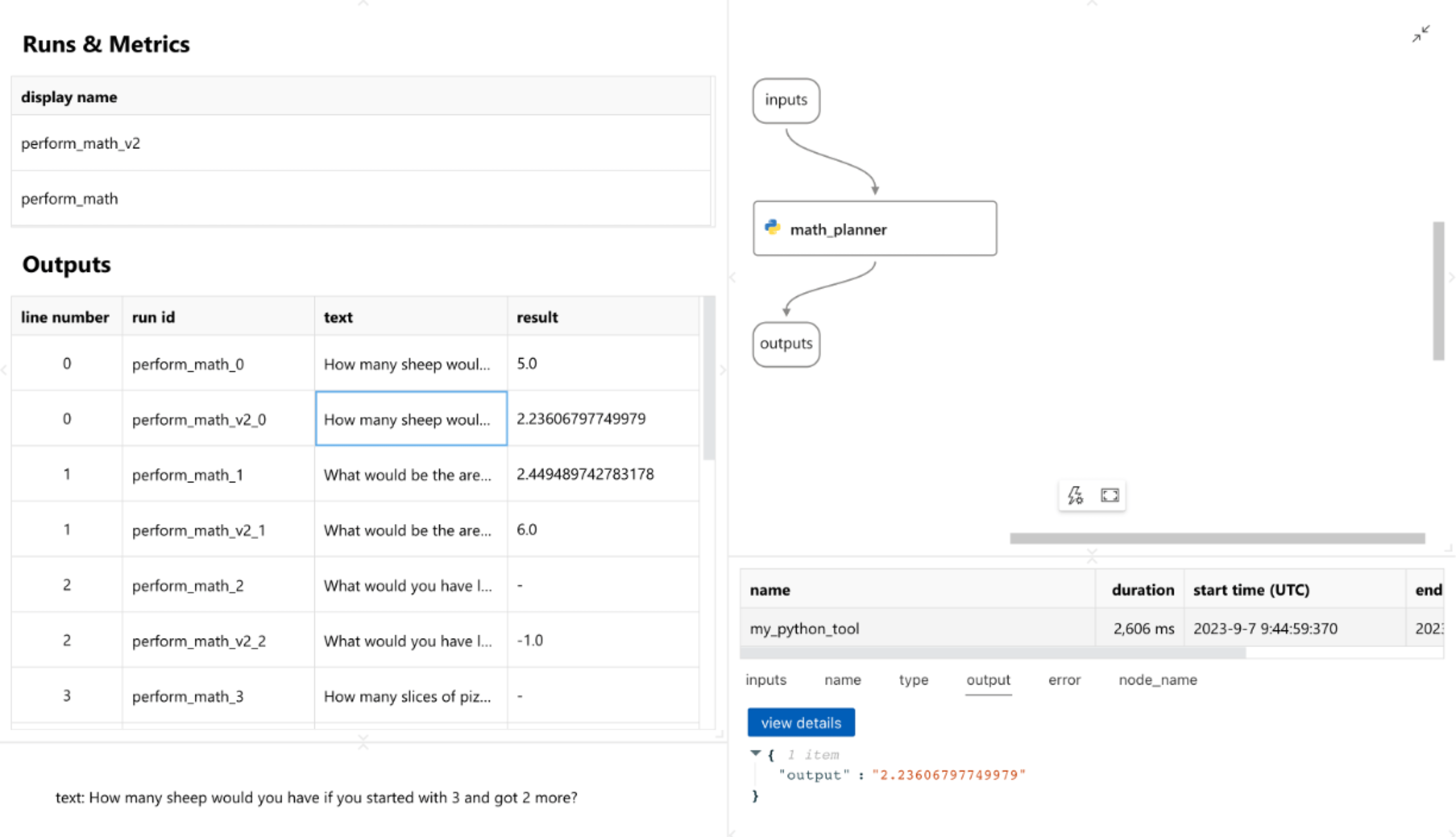
Comparing results in VS Code
You can also use the Prompt flow VS Code extension to compare and contrast multiple batch runs. To do this, complete the following:
Select the Prompt flow icon in the app bar in VS Code.
In the Batch run history section, select the refresh button.
Select the two runs you want to compare.
Select Visualize & analyze.

Afterwards, you should see a new tab in VS Code that shows the results of the two batch runs side by side.
Next steps
Now that you've learned how to evaluate your plugins and planners, you can start to iterate on your descriptions and hints to improve your results. You can also learn how to deploy your Prompt flow to an endpoint.