Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server
SQL Server
In SQL Server 2012 and 2014, the only way to initialize a secondary replica in a SQL Server Always On availability group is to use backup, copy, and restore. SQL Server 2016 introduces a new feature to initialize a secondary replica - automatic seeding. Automatic seeding uses the log stream transport to stream the backup using VDI to the secondary replica for each database of the availability group using the configured endpoints. This new feature can be used either during the initial creation of an availability group or when a database is added to one. Automatic seeding is in all editions of SQL Server that support Always On availability groups, and can be used with both traditional availability groups and distributed availability groups.
Security
Security permissions vary depending on the type of replica being initialized:
- For a traditional availability group, permissions must be granted to the availability group on the secondary replica as it is joined to the availability group. In Transact-SQL, use the command
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE. - For a distributed availability group where the replica's databases that are being created are on the primary replica of the second availability group, no extra permissions are required as it is already a primary. However, if there's only one replica on the second availability group, then grant the
CREATE ANY DATABASEpermission to the secondary availability group name, or automatic seeding may fail. - For a secondary replica on the second availability group of a distributed availability group, you must use the command
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASE. This secondary replica is seeded from the primary of the second availability group.
Performance and transaction log impact on the primary replica
Automatic seeding may or may not be practical to initialize a secondary replica, depending on the size of the database, network speed, and distance between the primary and secondary replicas. For example, given:
- The database size is 5 TB
- The network speed is 1Gb/sec
- The distance between the two sites is 1000 miles
If the full bandwidth is available, 1Gb/sec network can provide sustained throughput of 125 MB/sec. In this example, automatic seeding would take just over 11 hours. In practice, the automatic seeding process is slower, as network signals degrade over longer distances and the link is shared with other resources on the network. During seeding, the transaction log on the database at the primary replica continues to grow and cannot be truncated until automatic seeding of that database is complete. The transaction log can then be truncated using a transaction log backup.
Automatic seeding is a single-threaded process that can handle up to five databases. The single-threading affects performance, especially if the availability group has more than one database.
Compression can be used for automatic seeding, but it is disabled by default. Turning on compression reduces network bandwidth and possibly speeds up the process, but the tradeoff is additional processor overhead. To use compression during automatic seeding, enable trace flag 9567 - see Tune compression for availability group.
Disk layout
In SQL Server 2016 and before, the folder where the database is created by automatic seeding must already exist and be the same as the path on the primary replica.
In SQL Server 2017, Microsoft recommends using the same data and log file path on all replicas participating in an availability group but you can use different paths if necessary. For example, in a cross-platform availability group one instance of SQL Server is on Windows and another instance of SQL Server on is on Linux. The different platforms have different default paths. SQL Server 2017 supports availability group replicas on instances of SQL Server with different default paths.
The following table presents examples of supported data disk layouts that can support automatic seeding:
| Primary instance Default data path |
Secondary instance Default data path |
Primary instance Source file location |
Secondary instance Target file location |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Scenarios where primary and secondary replica database location are not the instance default paths are not impacted by this change. Requirements for secondary replica file paths to match the primary replica file paths remain the same.
| Primary instance Default data path |
Secondary instance Default data path |
Primary instance File location |
Secondary instance File location |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
If you mix default and non default paths on the primary and secondary replicas, SQL Server 2017 behaves differently than previous releases. The following table shows the SQL Server 2017 behavior.
| Primary instance Default data path |
Secondary instance Default data path |
Primary instance File location |
SQL Server 2016 Secondary instance File location |
SQL Server 2017 Secondary instance File location |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
To revert to the behavior for SQL Server 2016 and before, enable trace flag 9571. For information about how to enable trace flags see DBCC TRACEON (Transact-SQL).
Create an availability group with automatic seeding
You create an availability group using automatic seeding with either Transact-SQL or SQL Server Management Studio (SSMS, version 17 or later). To use the Availability Group Wizard in SSMS, follow these instructions - when you get to Step 9, notice automatic seeding is the first, and default, option.
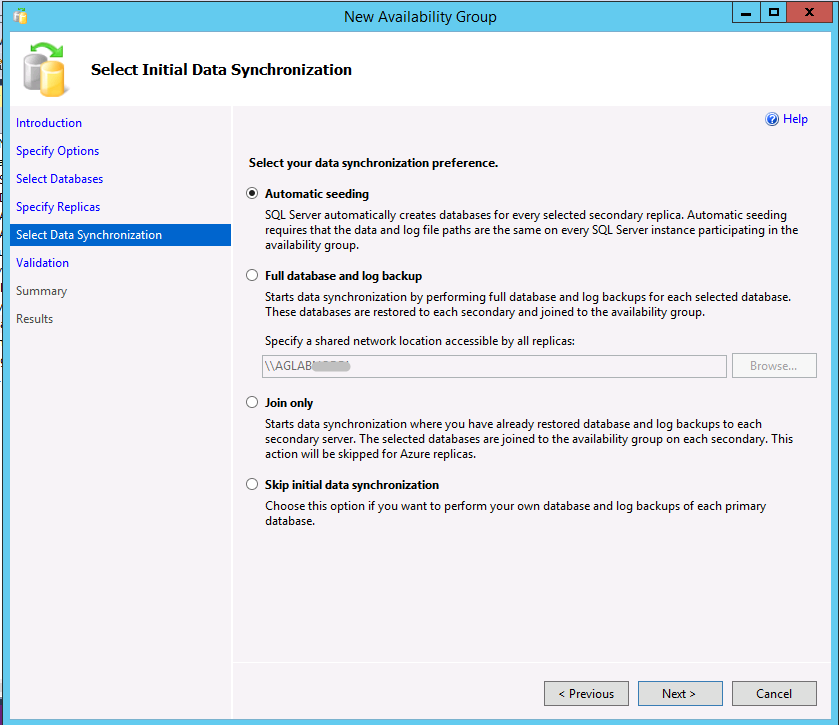
The following example creates an availability group with automatic seeding using Transact-SQL. See also the topic Create an Availability Group (Transact-SQL). Seeding is enabled on a secondary replica by setting the SEEDING_MODE option to AUTOMATIC. The default behavior is MANUAL, which is the pre-SQL Server 2016 behavior - requiring a backup of the database to be made on the primary replica, a copy of the backup file to the secondary replica, and a restore of the backup WITH NORECOVERY.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
Setting SEEDING_MODE on a primary replica during a CREATE AVAILABILITY GROUP statement has no effect since the primary replica already contains the main read/write copy of the database. SEEDING_MODE would only apply when another replica was made the primary and a database was added. The seeding mode can be changed later - see Change the seeding mode of a replica.
On an instance that becomes a secondary replica, once the instance is joined the following message is added to the SQL Server Log:
Local availability replica for availability group 'AGName' has not been granted permission to create databases, but has a
SEEDING_MODEofAUTOMATIC. UseALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEto allow the creation of databases seeded by the primary availability replica.
Grant create database permission on secondary replica to availability group
After joining, grant the availability group permission to create databases on the secondary replica instance of SQL Server. In order for automatic seeding to work, the availability group needs permission to create a database.
Tip
When the availability group creates a database on a secondary replica, it sets "sa" (more specifically account with sid 0x01) as the owner of the database.
To change database owner after a secondary replica automatically creates a database use ALTER AUTHORIZATION. See ALTER AUTHORIZATION (Transact-SQL).
The following example grants this permission to an availability group called AGName.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
If necessary set the owner of the database on the secondary replica.
Verify automatic seeding
If successful, the database(s) are automatically created on the secondary replica with a state of either:
- SYNCHRONIZED if the secondary replica is configured to be synchronous and the data is synchronized.
- SYNCHRONIZING if the secondary replica is configured with asynchronous data movement, or when configured with synchronous but not yet synchronized with the primary replica.
In addition to the Dynamic Management Views described below, the start and completion of automatic seeding can be seen in the SQL Server Log:

Combine backup and restore with automatic seeding
It is possible to combine the traditional backup, copy, and restore with automatic seeding. In this case, first restore the database on a secondary replica including all available transaction logs. Next, enable automatic seeding when creating the availability group to "catch up" the secondary replica's database, as if a tail-log backup were restored (see Tail-Log Backups (SQL Server)).
Add a database to an availability group with automatic seeding
You can add a database to an availability group using automatic seeding using Transact-SQL or SQL Server Management Studio (SSMS, version 17 or later).
If the secondary replica used automatic seeding when it was added to the availability group, nothing additional needs to be done. If the secondary replica used backup, copy, and restore, first change the seeding mode (see next section) and then when adding the database use the GRANT statement - see Availability Group - Add a Database.
Change the seeding mode of a replica
A replica's seeding mode can be altered after the availability group is created, so automatic seeding can be enabled or disabled. Enabling automatic seeding after creation allows a database to be added to the availability group using automatic seeding if it was created with backup, copy, and restore. For example:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
To disable automatic seeding, use a value of MANUAL.
Prevent automatic seeding after an availability group is created
If you do not want to disable automatic seeding completely for a secondary replica, but want to temporarily prevent the secondary replica from being able to automatically create databases, deny the availability group CREATE permission. This is the case when a new database is added to the availability group, but the availability group should not be allowed to create the database on a secondary replica.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Monitor automatic seeding
There are four ways to monitor and troubleshoot automatic seeding:
- SQL Server Log as already described
- Dynamic management views
- Backup history tables
- Extended events
Dynamic Management Views
There are two dynamic management views (DMVs) for monitoring seeding: sys.dm_hadr_automatic_seeding and sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingcontains the general status of automatic seeding, and retains the history for each time it is executed (whether successful or not). The columncurrent_statehas either a value of COMPLETED or FAILED. If the value is FAILED, use the value infailure_state_descto help in diagnosing the problem. You may need to combine that with what it in the SQL Server Log to see what went wrong. This DMV is populated on the primary replica and all secondary replicas.sys.dm_hadr_physical_seeding_statsshows the status of the automatic seeding operation as it is executing. As withsys.dm_hadr_automatic_seeding, this returns values for both the primary and secondary replicas, but this history is not stored. The values are for the current execution only, and is not retained. Columns of interest includestart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_ms,total_network_wait_time_ms, and if the seeding operation fails, failure_message.
Backup history tables
Automatic seeding also puts entries into the msdb tables which store the history for backups and restores. On the secondary replica which is receiving automatic seeding, the backupmediafamily table's physical_device_name column has a GUID for its value, and the corresponding entry in backupset has the name of the primary replica for server_name and machine_name.
Extended events
Automatic seeding adds new extended events for tracking state change, failures, and performance statistics during initialization. For example, the following script creates an extended events session that captures events related to automatic seeding.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
The following table lists extended events related to automatic seeding.
| Name | Description |
|---|---|
| hadr_db_manager_seeding_request_msg | Seeding request message. |
| hadr_physical_seeding_backup_state_change | Physical seeding backup side state change. |
| hadr_physical_seeding_restore_state_change | Physical seeding restore side state change. |
| hadr_physical_seeding_forwarder_state_change | Physical seeding forwarder side state change. |
| hadr_physical_seeding_forwarder_target_state_change | Physical seeding forwarder target side state change. |
| hadr_physical_seeding_submit_callback | Physical seeding submit callback event. |
| hadr_physical_seeding_failure | Physical seeding failure event. |
| hadr_physical_seeding_progress | Physical seeding progress event. |
| hadr_physical_seeding_schedule_long_task_failure | Physical seeding schedule long task failure event. |
| hadr_automatic_seeding_start | Occurs when an automatic seeding operation is submitted. |
| hadr_automatic_seeding_state_transition | Occurs when an automatic seeding operation changes state. |
| hadr_automatic_seeding_success | Occurs when an automatic seeding operation succeeds. |
| hadr_automatic_seeding_failure | Occurs when an automatic seeding operation fails. |
| hadr_automatic_seeding_timeout | Occurs when an automatic seeding operation times out. |
See also
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
Always On Availability Groups Troubleshooting and Monitoring Guide