Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server on Linux
SQL Server on Linux
This document describes how to do the following tasks for SQL Server on a shared disk failover cluster with Red Hat Enterprise Linux.
- Manually fail over the cluster
- Monitor a failover cluster SQL Server service
- Add a cluster node
- Remove a cluster node
- Change the SQL Server resource monitoring frequency
Architecture description
The clustering layer is based on Red Hat Enterprise Linux (RHEL) HA add-on built on top of Pacemaker. Corosync and Pacemaker coordinate cluster communications and resource management. The SQL Server instance is active on either one node or the other.
The following diagram illustrates the components in a Linux cluster with SQL Server.
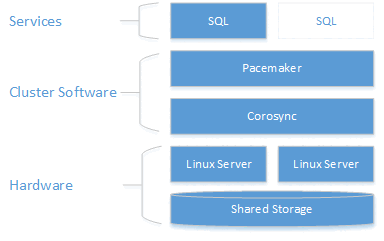
For more information on cluster configuration, resource agents options, and management, visit RHEL reference documentation.
Fail over cluster manually
The resource move command creates a constraint forcing the resource to start on the target node. After executing the move command, executing resource clear will remove the constraint so it's possible to move the resource again, or have the resource automatically fail over.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
The following example moves the mssqlha resource to a node named sqlfcivm2, and then removes the constraint so that the resource can move to a different node later.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Monitor a failover cluster SQL Server service
View the current cluster status:
sudo pcs status
View live status of cluster and resources:
sudo crm_mon
View the resource agent logs at /var/log/cluster/corosync.log
Add a node to a cluster
Check the IP address for each node. The following script shows the IP address of your current node.
ip addr showThe new node needs a unique name that is 15 characters or less. By default in Red Hat Linux the computer name is
localhost.localdomain. This default name might not be unique and is too long. Set the computer name the new node. Set the computer name by adding it to/etc/hosts. The following script lets you edit/etc/hostswithvi.sudo vi /etc/hostsThe following example shows
/etc/hostswith additions for three nodes namedsqlfcivm1,sqlfcivm2, andsqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3The file should be the same on every node.
Stop the SQL Server service on the new node.
Follow the instructions to mount the database file directory to the shared location:
From the NFS server, install
nfs-utils:sudo yum -y install nfs-utilsOpen up the firewall on clients and NFS server:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadEdit the
/etc/fstabfile to include the mount command:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrRun
mount -afor the changes to take effect.On the new node, create a file to store the SQL Server username and password for the Pacemaker login. The following command creates and populates this file:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdCaution
Your password should follow the SQL Server default password policy. By default, the password must be at least eight characters long and contain characters from three of the following four sets: uppercase letters, lowercase letters, base-10 digits, and symbols. Passwords can be up to 128 characters long. Use passwords that are as long and complex as possible.
On the new node, open the Pacemaker firewall ports. To open these ports with
firewalld, run the following command:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadIf you're using another firewall that doesn't have a built-in high-availability configuration, the following ports need to be opened for Pacemaker to be able to communicate with other nodes in the cluster:
- TCP: Ports 2224, 3121, 21064
- UDP: Port 5405
Install Pacemaker packages on the new node.
sudo yum install pacemaker pcs fence-agents-all resource-agentsSet the password for the default user that is created when installing Pacemaker and Corosync packages. Use the same password as the existing nodes.
sudo passwd haclusterEnable and start
pcsdservice and Pacemaker. This will allow the new node to rejoin the cluster after the reboot. Run the following command on the new node.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstall the FCI resource agent for SQL Server. Run the following commands on the new node.
sudo yum install mssql-server-haOn an existing node from the cluster, authenticate the new node and add it to the cluster:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>The following example adds a node named vm3 to the cluster.
sudo pcs cluster auth sudo pcs cluster start
Remove nodes from a cluster
To remove a node from a cluster, run the following command:
sudo pcs cluster node remove <nodeName>
Change the frequency of sqlservr resource monitoring interval
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
The following example sets the monitoring interval to 2 seconds for the mssql resource:
sudo pcs resource op monitor interval=2s mssqlha
Troubleshoot Red Hat Enterprise Linux shared disk cluster for SQL Server
When you troubleshoot the cluster, it helps to understand how the three daemons work together to manage cluster resources.
| Daemon | Description |
|---|---|
| Corosync | Provides quorum membership and messaging between cluster nodes. |
| Pacemaker | Resides on top of Corosync and provides state machines for resources. |
| PCSD | Manages both Pacemaker and Corosync through the pcs tools. |
PCSD must be running in order to use pcs tools.
Current cluster status
sudo pcs status returns basic information about the cluster, quorum, nodes, resources, and daemon status for each node.
An example of a healthy pacemaker quorum output would be:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
In the example, partition with quorum means that a majority quorum of nodes is online. If the cluster loses a majority quorum of nodes, pcs status returns partition WITHOUT quorum and all resources are stopped.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] returns the name of all nodes currently participating in the cluster. If any nodes aren't participating, pcs status returns OFFLINE: [<nodename>].
PCSD Status shows the cluster status for each node.
Reasons why a node might be offline
Check the following items when a node is offline.
Firewall
The following ports need to be open on all nodes for Pacemaker to be able to communicate.
- **TCP: 2224, 3121, 21064
Pacemaker or Corosync services running
Node communication
Node name mappings