Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server 2017 (14.x) and later versions
SQL Server 2017 (14.x) and later versions
This article describes the Python extension for running external Python scripts with SQL Server Machine Learning Services. The extension adds:
- A Python execution environment
- Anaconda distribution with the Python 3.5 runtime and interpreter
- Standard libraries and tools
- Microsoft Python packages:
- revoscalepy for analytics at scale.
- microsoftml for machine learning algorithms.
Installation of the Python 3.5 runtime and interpreter ensures near-complete compatibility with standard Python solutions. Python runs in a separate process from SQL Server, to guarantee that database operations are not compromised.
Python components
SQL Server includes both open-source and proprietary packages. The Python runtime installed by Setup is Anaconda 4.2 with Python 3.5. The Python runtime is installed independently of SQL tools, and is executed outside of core engine processes, in the extensibility framework. As part of the installation of Machine Learning Services with Python, you must consent to the terms of the GNU Public License.
SQL Server does not modify the Python executables, but you must use the version of Python installed by Setup because that version is the one that the proprietary packages are built and tested on. For a list of packages supported by the Anaconda distribution, see the Continuum analytics site: Anaconda package list.
The Anaconda distribution associated with a specific database engine instance can be found in the folder associated with the instance. For example, if you installed SQL Server 2017 database engine with Machine Learning Services and Python on the default instance, look under C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Python packages added by Microsoft for parallel and distributed workloads include the following libraries.
| Library | Description |
|---|---|
| revoscalepy | Supports data source objects and data exploration, manipulation, transformation, and visualization. It supports creation of remote compute contexts, as well as a various scalable machine learning models, such as rxLinMod. For more information, see revoscalepy module with SQL Server. |
| microsoftml | Contains machine learning algorithms that have been optimized for speed and accuracy, as well as in-line transformations for working with text and images. For more information, see microsoftml module with SQL Server. |
Microsoftml and revoscalepy are tightly coupled; data sources used in microsoftml are defined as revoscalepy objects. Compute context limitations in revoscalepy transfer to microsoftml. Namely, all functionality is available for local operations, but switching to a remote compute context requires RxInSqlServer.
Using Python in SQL Server
You import the revoscalepy module into your Python code, and then call functions from the module, like any other Python functions.
Supported data sources include ODBC databases, SQL Server, and XDF file format to exchange data with other sources, or with R solutions. Input data for Python must be tabular. All Python results must be returned in the form of a pandas data frame.
Supported compute contexts include local, or remote SQL Server compute context. A remote compute context refers to code execution that starts on one computer such as a workstation, but then switches script execution to a remote computer. Switching the compute context requires that both systems have the same revoscalepy library.
Local compute context, as you might expect, includes execution of Python code on the same server as the database engine instance, with code inside T-SQL or embedded in a stored procedure. You can also run the code from a local Python IDE and have the script execute on the SQL Server computer, by defining a remote compute context.
Execution architecture
The following diagrams depict the interaction of SQL Server components with the Python runtime in each of the supported scenarios: running script in-database, and remote execution from a Python terminal, using a SQL Server compute context.
Python scripts executed in-database
When you run Python "inside" SQL Server, you must encapsulate the Python script inside a special stored procedure, sp_execute_external_script.
After the script has been embedded in the stored procedure, any application that can make a stored procedure call can initiate execution of the Python code. Thereafter SQL Server manages code execution as summarized in the following diagram.
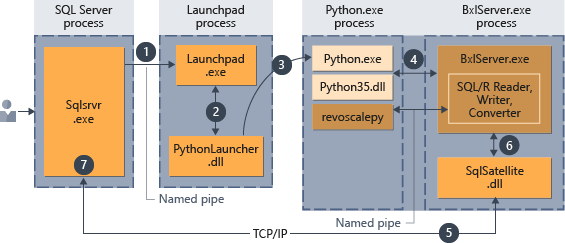
- A request for the Python runtime is indicated by the parameter
@language='Python'passed to the stored procedure. SQL Server sends this request to the launchpad service. In Linux, SQL uses a launchpadd service to communicate with a separate launchpad process for each user. See the Extensibility architecture diagram for details. - The launchpad service starts the appropriate launcher; in this case, PythonLauncher.
- PythonLauncher starts the external Python35 process.
- BxlServer coordinates with the Python runtime to manage exchanges of data, and storage of working results.
- SQL Satellite manages communications about related tasks and processes with SQL Server.
- BxlServer uses SQL Satellite to communicate status and results to SQL Server.
- SQL Server gets results and closes related tasks and processes.
Python scripts executed from a remote client
You can run Python scripts from a remote computer, such as a laptop, and have them execute in the context of the SQL Server computer, if these conditions are met:
- You design the scripts appropriately
- The remote computer has installed the extensibility libraries that are used by Machine Learning Services. The revoscalepy package is required to use remote compute contexts.
The following diagram summarizes the overall workflow when scripts are sent from a remote computer.
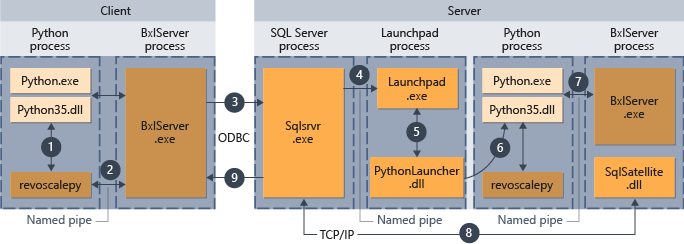
- For functions that are supported in revoscalepy, the Python runtime calls a linking function, which in turn calls BxlServer.
- BxlServer is included with Machine Learning Services (In-Database) and runs in a separate process from the Python runtime.
- BxlServer determines the connection target and initiates a connection using ODBC, passing credentials supplied as part of the connection string in the Python script.
- BxlServer opens a connection to the SQL Server instance.
- When an external script runtime is called, the launchpad service is invoked, which in turn starts the appropriate launcher: in this case, PythonLauncher.dll. Thereafter, processing of Python code is handled in a workflow similar to that when Python code is invoked from a stored procedure in T-SQL.
- PythonLauncher makes a call to the instance of the Python that is installed on the SQL Server computer.
- Results are returned to BxlServer.
- SQL Satellite manages communication with SQL Server and cleanup of related job objects.
- SQL Server passes results back to the client.