Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server 2017 (14.x) and later versions
SQL Server 2017 (14.x) and later versions ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Automatic tuning is a database feature that provides insight into potential query performance problems, recommend solutions, and automatically fix identified problems.
Automatic tuning, introduced in SQL Server 2017 (14.x), notifies you whenever a potential performance issue is detected and lets you apply corrective actions, or lets the Database Engine automatically fix performance problems. Automatic tuning SQL Server identifies and fixes performance issues caused by query execution plan choice regressions. Automatic tuning in Azure SQL Database and SQL database in Microsoft Fabric also creates necessary indexes and drops unused indexes. For more information on query execution plans, see Execution Plans.
The SQL Server Database Engine monitors the queries that are executed on the database and automatically improves performance of the workload. The Database Engine has a built-in intelligence mechanism that can automatically tune and improve performance of your queries by dynamically adapting the database to your workload. There are two automatic tuning features that are available:
Automatic plan correction identifies problematic query execution plans, such as a parameter sensitivity or parameter sniffing issues, and fixes query execution plan-related performance problems by forcing the last known good plan before the regression occurred. Applies to: SQL Server (Starting with SQL Server 2017 (14.x)), Azure SQL Database, and SQL database in Microsoft Fabric, and Azure SQL Managed Instance
Automatic index management identifies indexes that should be added in your database, and indexes that should be removed. Applies to: Azure SQL Database and SQL database in Microsoft Fabric
Note
In this article, features and behaviors of Azure SQL Database also apply to SQL database in Microsoft Fabric.
Why automatic tuning?
Three of the main tasks in classic database administration are monitoring the workload, identifying critical Transact-SQL queries, and identifying indexes that should be added to improve performance, or indexes that are rarely used and could be removed to improve performance. The SQL Server Database Engine provides detailed insight into the queries and indexes that you need to monitor. However, constantly monitoring a database is a hard and tedious task, especially when dealing with many databases. Managing a huge number of databases might be impossible to do efficiently. Instead of monitoring and tuning your database manually, you might consider delegating some of the monitoring and tuning actions to the Database Engine using automatic tuning feature.
How does automatic tuning work?
Automatic tuning is a continuous monitoring and analysis process that constantly learns about the characteristics of your workload and identifies potential issues and improvements.
This process enables the database to dynamically adapt to your workload by finding what indexes and plans might improve the performance of your workloads and what indexes affect your workloads. Based on these findings, automatic tuning applies tuning actions that improve the performance of your workload. In addition, automatic tuning continuously monitors the performance of the database after implementing any changes to ensure that it improves performance of your workload. Any action that didn't improve performance is automatically reverted. This verification process is a key feature that ensures any change made by automatic tuning does not decrease the overall performance of your workload.
Automatic plan correction
Automatic plan correction is an automatic tuning feature that identifies execution plan choice regression and automatically fixes the issue by forcing the last known good plan. For more information about query execution plans and the Query Optimizer, see the Query Processing Architecture Guide.
Important
Automatic plan correction depends on Query Store being enabled in the database for workload tracking.
What is execution plan choice regression?
The SQL Server Database Engine may use different execution plans to execute the Transact-SQL queries. Query plans depend on the statistics, indexes, and other factors. The optimal plan that should be used to execute a Transact-SQL query might change over time depending on changes in these factors. In some cases, the new plan might not be better than the previous one, and the new plan might cause a performance regression, such as a parameter sensitivity or parameter sniffing related issue.
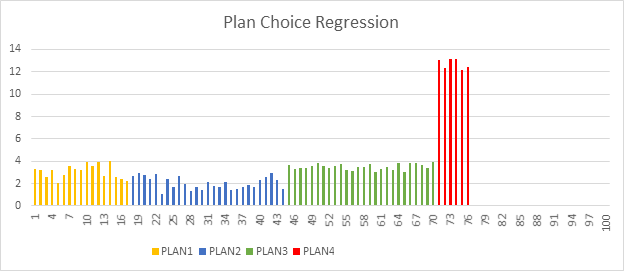
Whenever you notice a plan choice regression has occurred, you should find a previous good plan and force it to be used instead of the current one. This can be done by using the sp_query_store_force_plan procedure. The Database Engine in SQL Server 2017 (14.x) provides information about regressed plans and recommended corrective actions. Additionally, Database Engine enables you to fully automate this process and let Database Engine fix any problem found related to the plan change.
Important
Automatic plan correction should be used in the scope of a database compatibility level upgrade, after a baseline has been captured, to automatically mitigate workload upgrade risks. For more information about this use case, see Keep performance stability during the upgrade to newer SQL Server.
Automatic plan choice correction
The Database Engine can automatically switch to the last known good plan whenever a plan choice regression is detected.
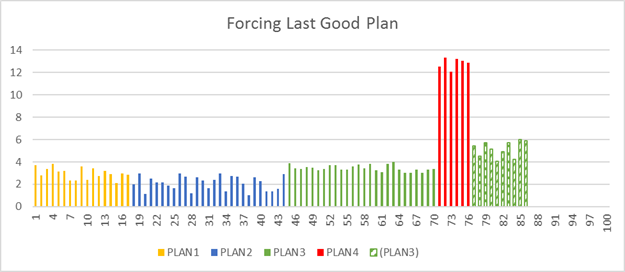
The Database Engine automatically detects any potential plan choice regression, including the plan that should be used instead of the wrong plan. The resulting execution plan forced by automatic plan correction will be the same or similar to the last known good plan. Because the resulting plan may not be identical to the last know good plan, the performance of forced plan may vary. In rare cases, the performance difference may be significant and negative; in this case, automatic plan correction will automatically stop attempting to force the replacement plan.
When the Database Engine applies the last known good plan before the regression occurred, it automatically monitors the performance of the forced plan. If the forced plan is not better than the regressed plan, the new plan will be unforced and the Database Engine will compile a new plan. If the Database Engine verifies that the forced plan is better than the regressed plan, the forced plan will be retained. It will be retained until a recompile occurs (for example, on the next statistics update or schema change). For more information about plan forcing and types of plans that can be forced, see Plan forcing limitations.
Note
If the SQL Server instance is restarted before a plan forcing action is verified, that plan will be automatically unforced. Otherwise, plan forcing is persisted on SQL Server restarts.
Enable automatic plan choice correction
You can enable automatic tuning per database and specify that the last good plan should be forced whenever some plan change regression is detected. Automatic tuning is enabled using the following command:
ALTER DATABASE <yourDatabase>
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
Once you enable this option, the Database Engine will automatically force any recommendation where the estimated CPU gain is higher than 10 seconds, or the number of errors in the new plan is higher than the number of errors in the recommended plan, and verify that the forced plan is better than the current one.
To enable automatic tuning in Azure SQL Database and Azure SQL Managed Instance, see Enable automatic tuning in Azure SQL Database using Azure portal.
Alternative - manual plan choice correction
Without automatic tuning, users must periodically monitor the system and look for the queries that have regressed. If any plan has regressed, the user should find a previous good plan and force it instead of the current one by using sp_query_store_force_plan procedure. The best practice would be to force the last known good plan because older plans might be invalid due to statistic or index changes. The user who forces the last known good plan should monitor performance of the query that is executed using the forced plan and verify that forced plan works as expected. Depending on the results of monitoring and analysis, the plan should be forced or the user should find another way to optimize the query, such as rewriting it. Manually forced plans should not be forced forever, because the Database Engine should be able to apply optimal plans. The user or DBA should eventually unforce the plan using sp_query_store_unforce_plan procedure, and let the Database Engine find the optimal plan.
Tip
Alternatively, use the Queries With Forced Plans Query Store view to locate and unforce plans.
SQL Server provides all necessary views and procedures required to monitor performance and fix problems in Query Store.
In SQL Server 2016 (13.x), you can find plan choice regressions using Query Store system views. Starting with SQL Server 2017 (14.x), the Database Engine detects and shows potential plan choice regressions and the recommended actions that should be applied in the sys.dm_db_tuning_recommendations (Transact-SQL) DMV. The DMV shows information about the problem, the importance of the issue, and details such as the identified query, the ID of the regressed plan, the ID of the plan that was used as baseline for comparison, and the Transact-SQL statement that can be executed to fix the problem.
| type | description | datetime | score | details | ... |
|---|---|---|---|---|---|
FORCE_LAST_GOOD_PLAN |
CPU time changed from 4 ms to 14 ms | 3/17/2017 | 83 | queryId recommendedPlanId regressedPlanId T-SQL |
|
FORCE_LAST_GOOD_PLAN |
CPU time changed from 37 ms to 84 ms | 3/16/2017 | 26 | queryId recommendedPlanId regressedPlanId T-SQL |
Some columns from this view are described in the following list:
- Type of the recommended action
FORCE_LAST_GOOD_PLAN. - Description that contains information why the Database Engine thinks that this plan change is a potential performance regression.
- Datetime when the potential regression is detected.
- Score of this recommendation.
- Details about the issues such as ID of the detected plan, ID of the regressed plan, ID of the plan that should be forced to fix the issue, Transact-SQL script that might be applied to fix the issue, etc. Details are stored in JSON format.
Use the following query to obtain a script that fixes the issue and additional information about the estimated gain:
SELECT reason, score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.*,
estimated_gain = (regressedPlanExecutionCount + recommendedPlanExecutionCount)
* (regressedPlanCpuTimeAverage - recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount > recommendedPlanErrorCount, 'YES','NO')
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
regressedPlanId int '$.regressedPlanId',
recommendedPlanId int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) AS planForceDetails;
Here's the result set.
| reason | score | script | query_id | current plan_id | recommended plan_id | estimated_gain | error_prone |
|---|---|---|---|---|---|---|---|
| CPU time changed from 3 ms to 46 ms | 36 | EXEC sp_query_store_force_plan 12, 17; | 12 | 28 | 17 | 11.59 | 0 |
The column estimated_gain represents the estimated number of seconds that would be saved if the recommended plan would be used for query execution instead of the current plan. The recommended plan should be forced instead of the current plan if the gain is greater than 10 seconds. If there are more errors (for example, time-outs or aborted executions) in the current plan than in the recommended plan, the column error_prone would be set to the value YES. An error prone plan is another reason why the recommended plan should be forced instead of the current one.
Although the Database Engine provides all the information required to identify plan choice regressions, continuous monitoring and fixing performance issues might become a tedious process. Automatic tuning makes this process much easier.
Note
Data in the sys.dm_db_tuning_recommendations DMV is not persisted after a restart of the database engine. Use the sqlserver_start_time column in sys.dm_os_sys_info to find the last database engine startup time.
Automatic index management
In Azure SQL Database, index management is easy because Azure SQL Database learns about your workload and ensures that your data is always optimally indexed. Proper index design is crucial for optimal performance of your workload, and automatic index management can help you optimize your indexes. Automatic index management can either fix performance issues in incorrectly indexed databases, or maintain and improve indexes on the existing database schema. Automatic tuning in Azure SQL Database performs the following actions:
- Identifies indexes that could improve the performance of your Transact-SQL queries that read data from the tables.
- Identifies redundant indexes or indexes that were not used in longer period of time that could be removed. Removing unnecessary indexes improves the performance of queries that update data in tables.
Why do you need index management?
Indexes speed up some of your queries that read data from the tables, however they can slow down the queries that update data. You need to carefully analyze when to create an index and what columns you need to include in the index. Some indexes might not be needed after some time. Therefore, you would need to periodically identify and drop these indexes that do not bring any benefits. If you ignore the unused indexes, performance of the queries that update data would be decreased without any benefit to the queries that read data. Unused indexes also affect overall performance of the system because additional updates require unnecessary logging.
Finding the optimal set of indexes that improve performance of the queries that read data from your tables and have minimal impact on updates might require continuous and complex analysis.
Azure SQL Database uses built-in intelligence and advanced rules that analyze your queries, identify indexes that would be optimal for your current workloads, and identify the indexes that might need to be removed. Azure SQL Database ensures that you have a minimal necessary set of indexes that optimize the queries that read data, with minimized impact on the other queries.
Automatic index management
In addition to detection, Azure SQL Database can automatically apply identified recommendations. If you find that the built-in rules improve the performance of your database, you might let Azure SQL Database automatically manage your indexes.
When Azure SQL Database applies a CREATE INDEX or DROP INDEX recommendation, it automatically monitors the performance of the queries that are affected by the index. New index will be retained only if performances of the affected queries are improved. Dropped index will be automatically re-created if there are some queries that run slower due to the absence of the index.
Automatic index management considerations
Actions required to create necessary indexes in Azure SQL Database might consume resources and temporally affect workload performance. To minimize the impact of index creation on workload performance, Azure SQL Database finds an appropriate time window for any index management operation. Tuning action is postponed if the database needs resources to execute your workload, and is restarted when the database has enough unused resources that can be used for the maintenance task. One important feature in automatic index management is a verification of the actions. When Azure SQL Database creates or drops an index, a monitoring process analyzes the performance of your workload to verify that the action improved the overall performance. If it did not bring significant improvement - the action is immediately reverted. This way, Azure SQL Database ensures that automatic tuning actions do not negatively impact the performance of your workload. Indexes created by automatic tuning are transparent for the maintenance operation on the underlying schema. Schema changes such as dropping or renaming columns are not blocked by the presence of automatically created indexes. Indexes that are automatically created by Azure SQL Database are immediately dropped when the related table or columns are dropped.
Alternative - manual index management
Without automatic index management, a user or DBA would need to manually query the sys.dm_db_missing_index_details (Transact-SQL) view or use the Performance Dashboard report in Management Studio to find indexes that might improve performance, create indexes using the details provided in this view, and manually monitor the performance of the query. In order to find the indexes that should be dropped, users should monitor operational usage statistics of the indexes to find rarely used indexes.
Azure SQL Database simplifies this process. Azure SQL Database analyzes your workload, identifies the queries that could be executed faster with a new index, and identifies unused or duplicated indexes. Find more information about identification of indexes that should be changed at Find index recommendations in Azure portal.
Next steps
- Automatic tuning in Azure SQL Database and Azure SQL Managed Instance
- ALTER DATABASE SET AUTOMATIC_TUNING (Transact-SQL)
- sys.database_automatic_tuning_options (Transact-SQL)
- sys.dm_db_tuning_recommendations (Transact-SQL)
- sys.dm_db_missing_index_details (Transact-SQL)
- sp_query_store_force_plan (Transact-SQL)
- sys.query_store_plan_forcing_locations (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- sys.database_query_store_options (Transact-SQL)
- sys.dm_os_sys_info (Transact-SQL)
- JSON functions
- Execution Plans
- Monitor and Tune for Performance
- Performance Monitoring and Tuning Tools
- Monitoring Performance By Using the Query Store
- Query Tuning Assistant