Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Before SQL Server 2016 (13.x), the in-row data size of a memory-optimized table couldn't be longer than 8,060 bytes. However, starting with SQL Server 2016 (13.x), and in Azure SQL Database, you can create a memory-optimized table with multiple large columns (for example, multiple varbinary(8000) columns) and LOB columns (that is, varbinary(max), varchar(max), and nvarchar(max)) and perform operations on them using natively compiled Transact-SQL (T-SQL) modules and table types.
Columns that don't fit in the 8,060-byte row size limit are placed off-row, in a separate internal table. Each off-row column has a corresponding internal table, which in turn has a single nonclustered index. For details about these internal tables used for off-row columns, see sys.memory_optimized_tables_internal_attributes.
There are certain scenarios where it's useful to compute the size of the row and the table:
How much memory a table uses.
The amount of memory used by the table can't be calculated exactly. Many factors affect the amount of memory used. Factors such as page-based memory allocation, locality, caching, and padding. Also, multiple versions of rows that either have active transactions associated or that are waiting for garbage collection.
The minimum size required for the data and indexes in the table is given by the calculation for
<table size>, discussed later in this article.Calculating memory use is at best an approximation and you're advised to include capacity planning in your deployment plans.
The data size of a row, and does it fit in the 8,060-byte row size limitation? To answer these questions, use the computation for
<row body size>, discussed later in this article.
A memory-optimized table consists of a collection of rows and indexes that contain pointers to rows. The following figure illustrates a table with indexes and rows, which in turn have row headers and bodies:
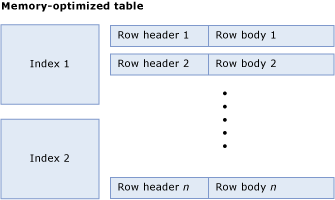
Compute table size
The in-memory size of a table, in bytes, is computed as follows:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
The size of a hash index is fixed at table creation time and depends on the actual bucket count. The bucket_count specified with the index definition is rounded up to the nearest power of 2 to obtain the actual bucket count. For example, if the specified bucket_count is 100000, the actual bucket count for the index is 131072.
<hash index size> = 8 * <actual bucket count>
The size of a nonclustered index is in the order of <row count> * <index key size>.
The row size is computed by adding the header and the body:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Compute row body size
The rows in a memory-optimized table have the following components:
The row header contains the timestamp necessary to implement row versioning. The row header also contains the index pointer to implement the row chaining in the hash buckets (described previously).
The row body contains the actual column data, which includes some auxiliary information like the null array for nullable columns and the offset array for variable-length data types.
The following figure illustrates the row structure for a table that has two indexes:

The begin and end timestamps indicate the period in which a particular row version is valid. Transactions that start in this interval can see this row version. For more information, see Transactions with Memory-Optimized Tables.
The index pointers point to the next row in the chain belonging to the hash bucket. The following figure illustrates the structure of a table with two columns (name, city), and with two indexes, one on the column name, and one on the column city.
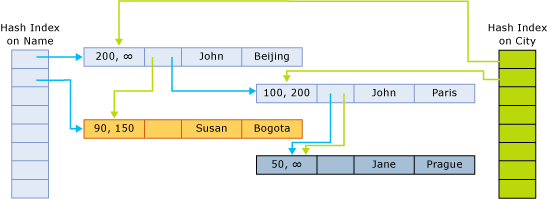
In this figure, the names John and Jane are hashed to the first bucket. Susan is hashed to the second bucket. The cities Beijing and Bogota are hashed to the first bucket. Paris and Prague are hashed to the second bucket.
Thus, the chains for the hash index on name are as follows:
- First bucket:
(John, Beijing);(John, Paris);(Jane, Prague) - Second bucket:
(Susan, Bogota)
The chains for the index on city are as follows:
- First bucket:
(John, Beijing),(Susan, Bogota) - Second bucket:
(John, Paris),(Jane, Prague)
An end timestamp ∞ (infinity) indicates that this is the currently valid version of the row. The row wasn't updated or deleted since this row version was written.
For a time greater than 200, the table contains the following rows:
| Name | City |
|---|---|
| John | Beijing |
| Jane | Prague |
However, any active transaction with begin time 100, see the following version of the table:
| Name | City |
|---|---|
| John | Paris |
| Jane | Prague |
| Susan | Bogota |
The calculation of <row body size> is discussed in the following table.
There are two different computations for row body size: computed size and the actual size:
The computed size, denoted with computed row body size, is used to determine if the row size limitation of 8,060 bytes is exceeded.
The actual size, denoted with actual row body size, is the actual storage size of the row body in memory and in the checkpoint files.
Both computed row body size and actual row body size are calculated similarly. The only difference is the calculation of the size of (n)varchar(i) and varbinary(i) columns, as reflected at the bottom of the following table. The computed row body size uses the declared size i as the size of the column, while the actual row body size uses the actual size of the data.
The following table describes the calculation of the row body size, given as <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Section | Size | Comments |
|---|---|---|
| Shallow type columns | SUM(<size of shallow types>). Size in bytes of the individual types is as follows:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8numeric (precision <= 18): 8time: 8numeric(precision > 18): 16uniqueidentifier: 16 |
|
| Shallow column padding | Possible values are:1 if there are deep type columns and the total data size of the shallow columns is as odd number.0 otherwise |
Deep types are the types (var)binary and (n)(var)char. |
| Offset array for deep type columns | Possible values are:0 if there are no deep type columns2 + 2 * <number of deep type columns> otherwise |
Deep types are the types (var)binary and (n)(var)char. |
| Null array | <number of nullable columns> / 8 rounded up to full bytes. |
The array has 1 bit per nullable column. This is rounded up to full bytes. |
| Null array padding | Possible values are:1 if there are deep type columns, and the size of the NULL array is an odd number of bytes.0 otherwise |
Deep types are the types (var)binary and (n)(var)char. |
| Padding | If there are no deep type columns: 0If there are deep type columns, 0 - 7 bytes of padding is added, based on the largest alignment required by a shallow column. Each shallow column requires alignment equal to its size as documented previously, except that GUID columns need alignment of 1 byte (not 16) and numeric columns always need alignment of 8 bytes (never 16). The largest alignment requirement among all shallow columns is used. 0 - 7 bytes of padding is added in such a way that the total size so far (without the deep type columns) is a multiple of the required alignment. |
Deep types are the types (var)binary and (n)(var)char. |
| Fixed-length deep type columns | SUM(<size of fixed length deep type columns>)The size of each column is as follows: i for char(i) and binary(i).2 * i for nchar(i) |
Fixed-length deep type columns are columns of type char(i), nchar(i), or binary(i). |
| Variable length deep type columns computed size | SUM(<computed size of variable length deep type columns>)The computed size of each column is as follows: i for varchar(i) and varbinary(i)2 * i for nvarchar(i) |
This row only applied to computed row body size. Variable-length deep type columns are columns of type varchar(i), nvarchar(i), or varbinary(i). The computed size is determined by the max length ( i) of the column. |
| Variable length deep type columns actual size | SUM(<actual size of variable length deep type columns>)The actual size of each column is as follows: n, where n is the number of characters stored in the column, for varchar(i).2 * n, where n is the number of characters stored in the column, for nvarchar(i).n, where n is the number of bytes stored in the column, for varbinary(i). |
This row only applied to actual row body size. The actual size is determined by the data stored in the columns in the row. |
Example: Table and row size computation
For hash indexes, the actual bucket count is rounded up to the nearest power of 2. For example, if the specified bucket_count is 100000, the actual bucket count for the index is 131072.
Consider an Orders table with the following definition:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
This table has one hash index and a nonclustered index (the primary key). It also has three fixed-length columns and one variable-length column, with one of the columns being nullable (OrderDescription). Let's assume the Orders table has 8,379 rows, and the average length of the values in the OrderDescription column is 78 characters.
To determine the table size, first determine the size of the indexes. The bucket_count for both indexes is specified as 10000. This is rounded up to the nearest power of 2: 16384. Therefore, the total size of the indexes for the Orders table is:
8 * 16384 = 131072 bytes
What remains is the table data size, which is:
<row size> * <row count> = <row size> * 8379
(The example table has 8,379 rows.) Now, we have:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
Next, let's calculate <actual row body size>:
Shallow type columns:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16Shallow column padding is 0, as the total shallow column size is even.
Offset array for deep type columns:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLarray = 1NULLarray padding = 1, as theNULLarray size is odd and there's a deep type column.Padding
- 8 is the largest alignment requirement
- Size so far is 16 + 0 + 4 + 1 + 1 = 22
- Nearest multiple of 8 is 24
- Total padding is 24 - 22 = 2 bytes
There are no fixed-length deep type columns (Fixed-length deep type columns: 0.).
The actual size of deep type column is 2 * 78 = 156. The single deep type column
OrderDescriptionhas typenvarchar.
<actual row body size> = 24 + 156 = 180 bytes
To complete the calculation:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
Total table size in memory is thus approximately 2 megabytes. This doesn't account for potential overhead incurred by memory allocation, and any row versioning required for the transactions accessing this table.
The actual memory allocated for and used by this table and its indexes can be obtained through the following query:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Off-row column limitations
Certain limitations and caveats to using off-row columns in a memory-optimized table are listed as follows:
- If there's a columnstore index on a memory-optimized table, then all the columns must fit in-row.
- All index key columns must be stored in-row. If an index key column doesn't fit in-row, adding the index fails.
- Caveats on altering a memory-optimized table with off-row columns.
- For LOBs, the size limitation mirrors that of disk based tables (2-GB limit on LOB values).
- For optimal performance, we recommend that most columns should fit within 8,060 bytes.
- Off-row data can cause excessive memory and/or disk usage.