Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server
SQL Server
Merge replication, like transactional replication, typically starts with a snapshot of the publication database objects and data. Subsequent data changes and schema modifications made at the Publisher and Subscribers are tracked with triggers. The Subscriber synchronizes with the Publisher when connected to the network and exchanges all rows that have changed between the Publisher and Subscriber since the last time synchronization occurred.
Merge replication is typically used in server-to-client environments. Merge replication is appropriate in any of the following situations:
Multiple Subscribers might update the same data at various times and propagate those changes to the Publisher and to other Subscribers.
Subscribers need to receive data, make changes offline, and later synchronize changes with the Publisher and other Subscribers.
Each Subscriber requires a different partition of data.
Conflicts might occur and, when they do, you need the ability to detect and resolve them.
The application requires net data change rather than access to intermediate data states. For example, if a row changes five times at a Subscriber before it synchronizes with a Publisher, the row will change only once at the Publisher to reflect the net data change (that is, the fifth value).
Merge replication allows various sites to work autonomously and later merge updates into a single, uniform result. Because updates are made at more than one node, the same data might have been updated by the Publisher and by more than one Subscriber. Therefore, conflicts can occur when updates are merged and merge replication provides several ways to handle conflicts.
Merge replication is implemented by the SQL Server Snapshot Agent and Merge Agent. If the publication is unfiltered or uses static filters, the Snapshot Agent creates a single snapshot. If the publication uses parameterized filters, the Snapshot Agent creates a snapshot for each partition of data. The Merge Agent applies the initial snapshots to the Subscribers. It also merges incremental data changes that occurred at the Publisher or Subscribers after the initial snapshot was created, and detects and resolves any conflicts according to rules you configure.
To track changes, merge replication (and transactional replication with queued updating subscriptions) must be able to uniquely identify every row in every published table. To accomplish this merge replication adds the column rowguid to every table, unless the table already has a column of data type uniqueidentifier with the ROWGUIDCOL property set (in which case this column is used). If the table is dropped from the publication, the rowguid column is removed; if an existing column was used for tracking, the column isn't removed. A filter must not include the rowguidcol used by replication to identify rows. The newid() function is provided as a default for the rowguid column, however customers can provide a guid for each row if needed. However, don't provide value 00000000-0000-0000-0000-000000000000.
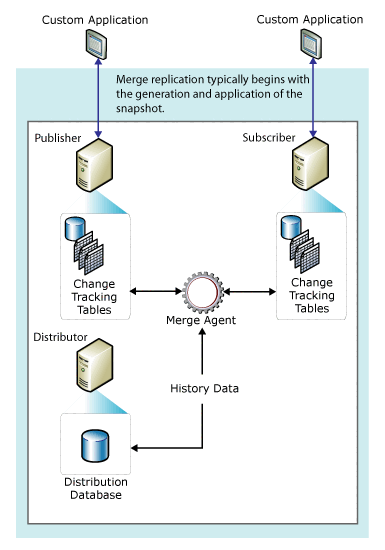
The following diagram shows the components used in merge replication.
Configure TLS 1.3 encryption
SQL Server 2025 (17.x) introduces TDS 8.0 support for merge replication, which includes:
- Configuring replication agents to use TLS 1.3 encryption between instances of SQL Server 2025 (17.x) and also between SQL Server 2025 (17.x) and Azure SQL Managed Instance.
- Default encryption for inter-instance linked server communication between SQL Server 2025 (17.x) instances in a replication topology. Linked servers in SQL Server 2025 (17.x) use the OLE DB v19 driver, which defaults to
Encrypt=Mandatoryencryption.
Note
For replication topologies with a remote distributor:
In this section
- How merge replication initializes publications and subscriptions
- How merge replication tracks and enumerates changes
- How merge replication evaluates partitions in filtered publications
- How merge replication detects and resolves conflicts
- Example of merge conflict resolution based on subscription type and assigned priorities
- How merge replication manages subscription expiration and metadata cleanup