Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server
SQL Server
SQL Server Always On failover cluster instances use Windows Server Failover Clustering (WSFC) to provide local high availability. A failover cluster instance (FCI) is redundant at the server-instance level. An FCI is a single instance of SQL Server that's installed across Windows Server cluster nodes and, possibly, across multiple subnets. On the network, an FCI appears as an instance of SQL Server running on a single computer, but the FCI provides failover from one WSFC node to another if the current node becomes unavailable.
An FCI can use Always On availability groups to provide remote disaster recovery at the database level. For more information, see Failover clustering and Always On availability groups (SQL Server).
SQL Server failover cluster instances support Storage Spaces Direct for cluster storage resources, which was introduced in Windows Server 2016 Datacenter edition. For more information, see Storage Spaces Direct in Windows Server.
Failover cluster instances also support Cluster Shared Volumes (CSV). For more information, see Understanding Cluster Shared Volumes in a failover cluster.
Note
SQL Server 2025 (17.x) introduces support to enforce strict connections to your failover cluster instance.
Benefits of failover cluster instances
When there's server hardware or software failure, the applications or clients connecting to the server experience downtime. Redundant nodes protect the availability of the SQL Server instance when it's an FCI instead of a standalone instance. Only one of the nodes in the FCI owns the WSFC resource group at a time. If a failure occurs (such as hardware failure, operating system failure, application or service failure), or during a planned upgrade, the cluster moves the resource group ownership to another WSFC node. This process is transparent to the client or application connecting to SQL Server. The process minimizes the downtime the application or clients experience during a failure. Here are some key benefits that SQL Server failover cluster instances provide:
Protection at the instance level through redundancy.
Automatic failover in the event of a failure (hardware failures, operating system failures, or application and service failures).
Important
In an availability group, automatic failover from an FCI to other nodes within the availability group isn't supported. Therefore, FCIs and standalone nodes shouldn't be coupled together within an availability group if automatic failover is an important component of your high availability solution. However, this coupling can be made for your disaster recovery solution.
Support for a broad array of storage solutions, including WSFC cluster disks (iSCSI, Fiber Channel, and so on) and Server Message Block (SMB) file shares.
Disaster recovery via a multi-subnet FCI or running an FCI-hosted database inside an availability group. With the multi-subnet support in SQL Server 2012 (11.x), a multi-subnet FCI doesn't require a virtual LAN. This support increases the manageability and security of a multi-subnet FCI.
Zero reconfiguration of applications and clients during failovers.
Flexible failover policy for granular trigger events for automatic failovers.
Reliable failovers through periodic and detailed health detection using dedicated and persisted connections.
Configurability and predictability in failover time through indirect background checkpoints.
Throttled resource usage during failovers.
Recommendations
In a production environment, use static IP addresses in conjunction with the virtual IP address of a failover cluster instance.
Don't use DHCP in a production environment. In the event of downtime, if the DHCP IP lease expires, extra time is required to re-register the new DHCP IP address associated with the DNS name.
Failover cluster instance overview
An FCI runs in a WSFC resource group with one or more WSFC nodes. When the FCI starts up, one of the nodes assumes ownership of the resource group and brings its SQL Server instance online. The resources owned by this node include:
- Network name
- IP address
- Shared disks
- SQL Server Database Engine service
- SQL Server Agent service
- SQL Server Analysis Services service, if it's installed
- One file share resource, if the FILESTREAM feature is installed
At any time, only the resource group owner (and no other node in the FCI) is running its respective SQL Server services in the resource group. When a failover occurs, whether it's an automatic failover or a planned failover, the following sequence of events happens:
Unless a hardware or system failure occurs, all dirty pages in the buffer cache are written to disk.
All respective SQL Server services in the resource group are stopped on the active node.
The resource group ownership is transferred to another node in the FCI.
The new resource group owner starts its SQL Server services.
Client application connection requests are automatically directed to the new active node using the same virtual network name.
The FCI is online as long as its underlying WSFC cluster is in good quorum health. (The majority of the quorum WSFC nodes are available as automatic failover targets.) When the WSFC cluster loses its quorum, whether due to hardware, software, or network failure or improper quorum configuration, the entire WSFC cluster, along with the FCI, is brought offline. Manual intervention is then required in this unplanned failover scenario to reestablish quorum in the remaining available nodes in order to bring the WSFC cluster and FCI back online. For more information, see WSFC quorum modes and voting configuration (SQL Server).
Predictable failover time
Depending on when your SQL Server instance last performed a checkpoint operation, there can be a substantial number of dirty pages in the buffer cache. Consequently, failovers last as long as it takes to write the remaining dirty pages to disk, which can lead to long and unpredictable failover time. Beginning with SQL Server 2012 (11.x), the FCI can use indirect checkpoints to throttle the number of dirty pages kept in the buffer cache. Although this consumes more resources under regular workloads, it makes the failover time more predictable and more configurable. This is useful when the service-level agreement in your organization specifies the recovery time objective (RTO) for your high availability solution. For more information, see Indirect checkpoints.
Reliable health monitoring and flexible failover policy
After the FCI starts successfully, the WSFC service monitors both the health of the underlying WSFC cluster and the health of the SQL Server instance. Beginning with SQL Server 2012 (11.x), the WSFC service uses a dedicated connection to poll the active SQL Server instance for detailed component diagnostics through a system stored procedure. There are three resulting implications:
The dedicated connection to the SQL Server instance makes it possible to reliably poll for component diagnostics all the time, even when the FCI is under heavy load. This capability makes it possible to distinguish between a system that's under heavy load and a system that has failure conditions, thus preventing issues such as false failovers.
The detailed component diagnostics makes it possible to configure a more flexible failover policy, whereby you can choose which failure conditions trigger failovers.
The detailed component diagnostics also enables better troubleshooting of automatic failovers retroactively. The diagnostic information is stored to log files, which are collocated with the SQL Server error logs. You can load them into the Log File Viewer to inspect the component states leading up to the failover occurrence in order to determine what caused the failover.
For more information, see Failover policy for failover cluster instances.
Configure TLS 1.3 encryption
SQL Server 2025 (17.x) introduces TDS 8.0 support, which allows enforcing TLS 1.3 encryption for communication between the Windows Server Failover Cluster and your failover cluster instances.
To get started, review Connect with strict encryption.
Note
SQL Server 2025 (17.x) failover cluster instance installation fails if TLS 1.2 is disabled on the machine.
Elements of a failover cluster instance
An FCI consists of a set of physical servers (nodes) that contain similar hardware configuration and also identical software configuration that includes operating system version and patch level, and SQL Server version, patch level, components, and instance name. Identical software configuration is necessary to ensure that the FCI can be fully functional when it fails over between the nodes.
WSFC resource group
A SQL Server FCI runs in a WSFC resource group. Each node in the resource group maintains a synchronized copy of the configuration settings and check-pointed registry keys to ensure full functionality of the FCI after a failover. Only one of the nodes in the cluster owns the resource group at a time (the active node). The WSFC service manages the server cluster, quorum configuration, failover policy, and failover operations in addition to the virtual network name and virtual IP addresses for the FCI. If there's a failure (hardware failures, operating system failures, or application and service failures) or a planned upgrade, the resource group ownership is moved to another node in the FCI. The number of nodes that are supported in a WSFC resource group depends on your SQL Server edition. Also, the same WSFC cluster can run multiple FCIs (multiple resource groups), depending on your hardware capacity, such as CPUs, memory, and number of disks.
SQL Server binaries
The product binaries are installed locally on each node of the FCI in a process that's similar to SQL Server stand-alone installations. However, during startup, the services aren't started automatically but managed by WSFC.
Storage
Unlike an availability group, an FCI must use shared storage among all nodes of the FCI for database and log storage. The shared storage can be in the form of WSFC cluster disks, disks on a SAN, Storage Spaces Direct, or file shares on an SMB. Therefore, all nodes in the FCI have the same view of instance data whenever a failover occurs. This means, however, that the shared storage has the potential of being the single point of failure, and that FCI depends on the underlying storage solution to ensure data protection.
Network name
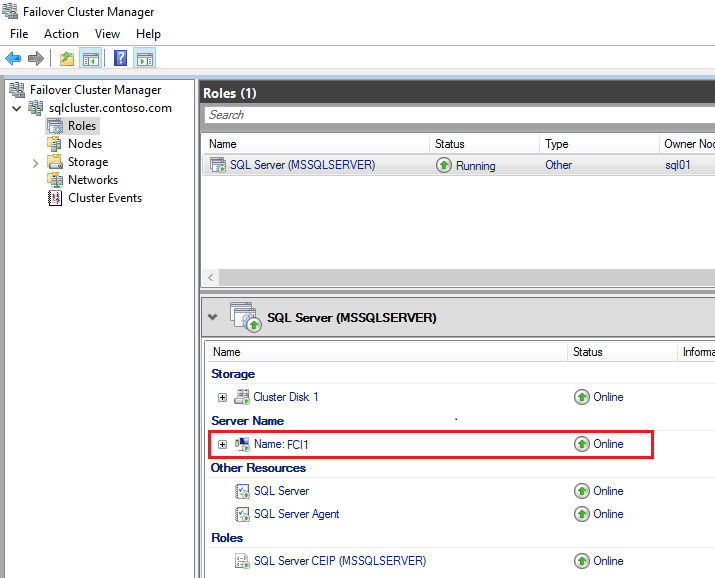
The virtual network name for the FCI provides a unified connection point for the FCI. This unified connection point allows applications to connect to the virtual network name without needing to know the currently active node. When a failover occurs, the virtual network name is registered to the new active node after it starts. This process is transparent to the client or application connecting to SQL Server, and it minimizes the downtime the application or clients experience during a failure.
The following screenshot shows the network name for the failover cluster instance in Failover Cluster Manager:
Virtual IPs
In the case of a multi-subnet FCI, a virtual IP address is assigned to each subnet in the FCI. During a failover, the virtual network name on the DNS server is updated to point to the virtual IP address for the respective subnet. Applications and clients can then connect to the FCI by using the same virtual network name after a multi-subnet failover.
SQL Server failover concepts and tasks
| Concepts and tasks | Article |
|---|---|
| Describes the failure detection mechanism and the flexible failover policy. | Failover policy for failover cluster instances |
| Describes concepts in FCI administration and maintenance. | Failover cluster instance administration and maintenance |
| Describes multi-subnet configuration and concepts. | SQL Server multi-subnet clustering |
SQL Server FCI-supported configuration on WSFC
SQL Server FCIs based on WSFC are supported in the following products:
- Windows Server 2012
- Windows Server 2012 R2
- Windows Server 2016 Standard and Datacenter editions
- Windows Server 2019 Standard and Datacenter editions
- Windows Server 2022 Standard and Datacenter editions
Windows Server provides two types of clustering services:
Only the server cluster solutions can be used together with SQL Server for high availability if a node is lost or if a problem exists with an instance of SQL Server. Network Load Balancing might be used in some cases together with stand-alone read-only SQL Server installations.
Each SQL Server FCI requires:
- A dedicated cluster group that has uniquely assigned disk drive letters.
- At least one unique IP address.
- Unique virtual server and instance names within the domain.
Non-Microsoft cluster solution support
SQL Server is developed and tested with Microsoft server clustering. If you use a non-Microsoft clustering product, your primary support contact for installation, performance, or cluster behavior issues should be the solution provider. Microsoft provides commercially reasonable support for non-Microsoft cluster installations, similar to support for stand-alone SQL Server deployments.
Number of supported nodes
For details on the maximum number of supported nodes for Always On failover cluster instances, see:
Supported operating system
For information about supported operating systems for SQL Server failover clustering, see Verify your operating system before installing failover clustering.
Mounted drives
The use of mounted drives isn't supported on clusters that include a SQL Server installation. For more information, see SQL Server support for mounted volumes.
Cluster Shared Volumes (CSV)
SQL Server 2012 (11.x) and earlier versions don't support the use of CSV for SQL Server in a failover cluster.
For information about using CSV with SQL Server 2014 (12.x) or later versions, see the following resources:
- Deploying SQL Server 2014 with Cluster Shared Volumes
- Cluster Shared Volumes
- Use Cluster Shared Volumes in a failover cluster
Domain controller restrictions
SQL Server failover cluster instances aren't supported on failover cluster instance nodes configured as domain controllers.
Domain migration considerations
SQL Server 2005 (9.x) and later versions can't be migrated to a new domain. You need to uninstall and re-install the failover cluster components. For more information, see Move a Windows Server cluster from one domain to another.
Before uninstalling SQL Server, you should take the following steps:
Set SQL Server to use mixed mode security, or add new domain accounts to the SQL Server logins.
Rename the
DATAfolder that contains system databases so that it can be swapped back in after re-installation to reduce downtime.Don't remove SQL Server support files, SQL Server Native Client, Integration Services, or Workstation Components, unless you're rebuilding the entire node.
Warning
If errors occur during the uninstallation process, you might need to rebuild the node to successfully install SQL Server again.
Related content
- Create a new Always On failover cluster instance (Setup)
- Upgrade a failover cluster instance
- Windows Server Failover Clustering with SQL Server
- Failover clustering and Always On availability groups (SQL Server)
- SQL Server enabled by Azure Arc
- View Always On failover cluster instances in Azure Arc
- Failover policy for failover cluster instances
- Support policy for Microsoft SQL Server products that are running in a hardware virtualization environment