Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
SQL Server Distributed Replay isn't available with SQL Server 2022 (16.x) and later versions.
The Microsoft SQL Server Distributed Replay feature helps you assess the effect of future SQL Server upgrades. You can also use it to help assess the effect of hardware and operating system upgrades, and SQL Server tuning.
Distributed Replay deprecation in SQL Server 2022
Distributed Replay is deprecated as of SQL Server 2022 (16.x), as noted in Deprecated Database Engine features in SQL Server 2022 (16.x). Distributed Replay has a dependency on SQL Server Native Client (SNAC), which was removed from SQL Server 2022 (16.x). This change is documented in Support Policies for SQL Server Native Client. In addition, Distributed Replay relies on .trc files, which are captured with SQL Trace and SQL Server Profiler, both of which are also deprecated.
The Distributed Replay Controller has been removed from SQL Server 2022 (16.x) Setup, and the Distributed Replay Client is no longer available in SQL Server Management Studio (SSMS) starting with version 18. To obtain the Distributed Replay Controller, you must install SQL Server 2019 (15.x) or an earlier version. To obtain the Distributed Replay Client, you must install SSMS 17.9.1.
For customers on SQL Server 2022 (16.x), you can instead use Replay Markup Language (RML) Utilities, which includes ostress, to replay a workload.
Benefits of Distributed Replay
Similar to SQL Server Profiler, you can use Distributed Replay to replay a captured trace against an upgraded test environment. Unlike SQL Server Profiler, Distributed Replay isn't limited to replaying the workload from a single computer.
Distributed Replay offers a more scalable solution than SQL Server Profiler. With Distributed Replay, you can replay a workload from multiple computers and better simulate a mission-critical workload.
The Distributed Replay feature can use multiple computers to replay trace data and simulate a mission-critical workload. Use Distributed Replay for application compatibility testing, performance testing, or capacity planning.
When to use Distributed Replay
SQL Server Profiler and Distributed Replay provide some overlap in functionality.
You can use SQL Server Profiler to replay a captured trace against an upgraded test environment. You can also analyze the replay results to look for potential functional and performance incompatibilities. However, SQL Server Profiler can only replay a workload from a single computer. When replaying an intensive OLTP application that has many active concurrent connections or high throughput, SQL Server Profiler can become a resource bottleneck.
Distributed Replay offers a more scalable solution than SQL Server Profiler. Use Distributed Replay to replay a workload from multiple computers and better simulate a mission-critical workload.
The following table describes when to use each tool.
| Tool | Use when... |
|---|---|
| SQL Server Profiler | You want to use the conventional replay mechanism on a single computer. In particular, you need line-by-line debugging capabilities, such as the Step, Run to Cursor, and Toggle Breakpoint commands. You want to replay an Analysis Services trace. |
| Distributed Replay | You want to evaluate application compatibility. For example, you want to test SQL Server and operating system upgrade scenarios, hardware upgrades, or index tuning. The concurrency in the captured trace is so high that a single replay client can't sufficiently simulate it. |
Distributed Replay concepts
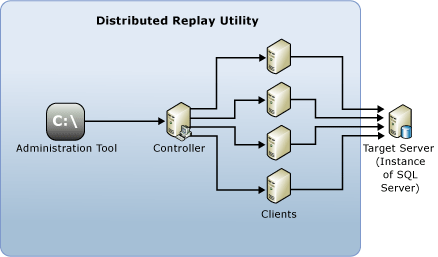
The following components make up the Distributed Replay environment:
Distributed Replay administration tool: A console application, DReplay.exe, used to communicate with the distributed replay controller. Use the administration tool to control the distributed replay.
Distributed Replay controller: A computer running the Windows service named SQL Server Distributed Replay controller. The Distributed Replay controller orchestrates the actions of the distributed replay clients. There can only be one controller instance in each Distributed Replay environment.
Distributed Replay clients: One or more computers (physical or virtual) running the Windows service named SQL Server Distributed Replay client. The Distributed Replay clients work together to simulate workloads against an instance of SQL Server. There can be one or more clients in each Distributed Replay environment.
Target server: An instance of SQL Server that the Distributed Replay clients can use to replay trace data. We recommend that the target server is located in a test environment.
The Distributed Replay administration tool, controller, and client can be installed on different computers or the same computer. There can be only one instance of the Distributed Replay controller or client service that is running on the same computer.
The following figure shows the SQL Server Distributed Replay physical architecture:
Distributed Replay tasks
| Task Description | Article |
|---|---|
| Describes how to configure Distributed Replay. | Configure Distributed Replay |
| Describes how to prepare the input trace data. | Prepare input trace data |
| Describes how to replay trace data. | Replay Trace Data |
| Describes how to review the Distributed Replay trace data results. | Review the Replay Results |
| Describes how to use the administration tool to initiate, monitor, and cancel operations on the controller. | Administration Tool Command-line Options (Distributed Replay Utility) |
Requirements
Before using the Distributed Replay feature, consider the product requirements that are outlined in this article.
Input trace requirements
To successfully replay trace data, it must meet the requirements for version and format, and contain the required events and columns.
Input trace versions
Distributed Replay supports input trace data that is collected on the following versions of SQL Server:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (Cumulative Update 1 and later versions - see SQL Server 2017 build versions)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Input trace formats
The input trace data can be in any of the following formats:
A single trace file that has the
.trcextension.A set of rollover trace files that follow the file rollover naming convention, for example:
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Input trace events and columns
The input trace data must contain specific events and columns to be replayed by Distributed Replay. The TSQL_Replay template in SQL Server Profiler contains all of the required events and columns, in addition to extra information. For more information about that template, see Replay Requirements.
Warning
If you don't use the TSQL_Replay template to capture the input trace data, or if the input trace requirements aren't satisfied, you might receive unexpected replay results.
You can also create a custom trace template and use it to replay events with Distributed Replay, as long as it contains the following events:
- Audit Login
- Audit Logout
- ExistingConnection
- RPC Output Parameter
- RPC:Completed
- RPC:Starting
- SQL:BatchCompleted
- SQL:BatchStarting
If you're replaying server-side cursors, the following events are also required:
- CursorClose
- CursorExecute
- CursorOpen
- CursorPrepare
- CursorUnprepare
If you're replaying server-side prepared SQL statements, the following events are also required:
- Exec Prepared SQL
- Prepare SQL
All input trace data must contain the following columns:
- Event Class
- EventSequence
- TextData
- Application Name
- LoginName
- DatabaseName
- Database ID
- HostName
- Binary Data
- SPID
- Start Time
- EndTime
- IsSystem
Supported input trace and target server combinations
The following table lists the supported versions of trace data, and for each, the supported versions of SQL Server that data can be replayed against.
| Version of input trace data | Supported versions of SQL Server for the target server instance |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Operating system requirements
Supported operating systems for running the administration tool and the controller and client services is the same as your SQL Server instance. For more information about which operating systems are supported for your SQL Server instance, see Hardware and software requirements for SQL Server 2016 and SQL Server 2017.
Distributed Replay features are supported on both x86-based and x64-based operating systems. For x64-based operating systems, only Windows on Windows (WOW) mode is supported.
Installation limitations
Any one computer can only have a single instance of each Distributed Replay feature installed. The following table lists how many installations of each feature are allowed in a single Distributed Replay environment.
| Distributed Replay Feature | Maximum Installations Per Replay Environment |
|---|---|
| SQL Server Distributed Replay controller service | 1 |
| SQL Server Distributed Replay client service | 16 (physical or virtual computers) |
| Administration tool | Unlimited |
Note
Although only one instance of the administration tool can be installed on a single computer, you can start multiple instances of the administration tool. Commands issued from multiple administration tools are resolved in the order in which they are received.
Data access provider
Distributed Replay only supports the SQL Server Native Client ODBC data access provider.
Target server preparation requirements
We recommend that the target server is located in a test environment. To replay trace data against a different instance of SQL Server than it was originally recorded, make sure that the following steps have been done on the target server:
All logins and users that are contained in the trace data must be present in the same database on the target server.
All logins and users on the target server must have the same permissions they had on the original server.
The database IDs on the target ideally should be the same as those on the source. However, if they aren't the same, matching can be performed based on DatabaseName if it's present in the trace.
The default database for each login that is contained in the trace data must be set (on the target server) to the respective target database of the login. For example, the trace data to be replayed contains activity for the login, Fred, in the database Fred_Db on the original instance of SQL Server. Therefore, on the target server, the default database for the login, Fred, must be set to the database that matches Fred_Db (even if the database name is different). To set the default database of the login, use the
sp_defaultdbsystem stored procedure.
Replaying events associated with missing or incorrect logins results in replay errors, but the replay operation continues.