Scaling with KEDA
- 5 minutes
Kubernetes Event-driven Autoscaling
Kubernetes Event-driven Autoscaling (KEDA) is a single-purpose and lightweight component that simplifies application autoscaling. You can add KEDA to any Kubernetes cluster and use it alongside standard Kubernetes components, like the Horizontal Pod Autoscaler (HPA) or Cluster Autoscaler, to extend their functionality. With KEDA, you can target specific apps that you want to leverage event-driven scaling and allow other apps to use different scaling methods. KEDA is a flexible and safe option to run alongside any number of Kubernetes applications or frameworks.
Key capabilities and features
- Build sustainable and cost-efficient applications with scale-to-zero capabilities
- Scale application workloads to meet demand using KEDA scalers
- Autoscale applications with
ScaledObjects - Autoscale jobs with
ScaledJobs - Use production-grade security by decoupling autoscaling and authentication from workloads
- Bring-your-own external scaler to use tailor-made autoscaling configurations
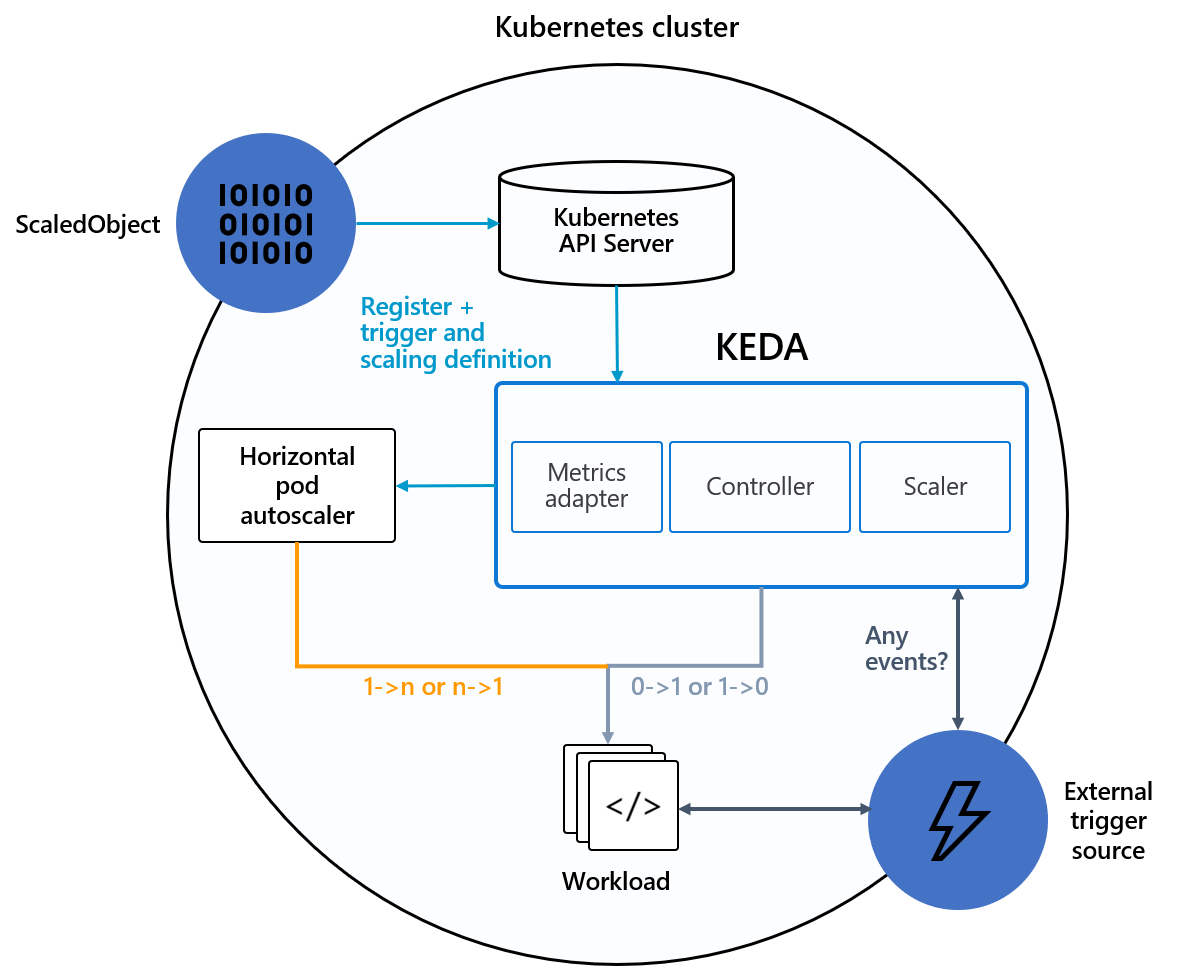
Architecture
KEDA provides two main components:
- KEDA operator: Allows end users to scale workloads in or out from zero to N instances with support for Kubernetes Deployments, Jobs, StatefulSets, or any customer resource that defines a
/scalesubresource. - Metrics server: Exposes external metrics to the HPA, such as messages in a Kafka topic or events in Azure Event Hubs, to drive autoscaling actions. Due to upstream limitations, the KEDA metrics server must be the only installed metrics adapter in the cluster.
The following diagram shows how KEDA integrates with the Kubernetes HPA, external event sources, and Kubernetes API Server to provide autoscaling functionality:
Tip
For more information, see the official KEDA documentation.
Event sources and scalers
KEDA scalers can detect if a Deployment should be activated or deactivated and feed custom metrics for a specific event source. Deployments and StatefulSets are the most common way to scale workloads with KEDA. You can also scale custom resources that implement the /scale subresource. You can define the Kubernetes Deployment or StatefulSet that you want KEDA to scale based on a scale trigger. KEDA monitors those services and automatically scales them in or out based on the events that occur.
Behind the scenes, KEDA monitors the event source and feeds that data to Kubernetes and the HPA to drive rapid resource scaling. Each replica of a resource actively pulls items from the event source. With KEDA and Deployments/StatefulSets, you can scale based on events while also preserving rich connection and processing semantics with the event source (for example, in-order processing, retries, deadletter, or checkpointing).
Scaled object spec
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Scaled job spec
As an alternative to scaling event-driven code as Deployments, you can also run and scale your code as a Kubernetes Job. The primary reason to consider this option is if you need to process long-running executions. Rather than processing multiple events within a Deployment, each detected event schedules its own Kubernetes Job. This approach allows you to process each event in isolation and scale the number of concurrent executions based on the number of events in the queue.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}