The evolution of cloud computing
The cloud-computing concept first appeared during the early 1950s, when several academics, including Herb Grosch, John McCarthy, and Douglas Parkhill[1], envisioned computing as a utility similar to electric power. Over the next few decades, several emerging technologies laid the foundations for cloud computing (Figure 1.3). More recently, rapid growth of the World Wide Web and the advent of large Internet giants, such as Microsoft, Google, and Amazon, finally led to the creation of an economic and business environment that allowed the cloud-computing model to flourish.
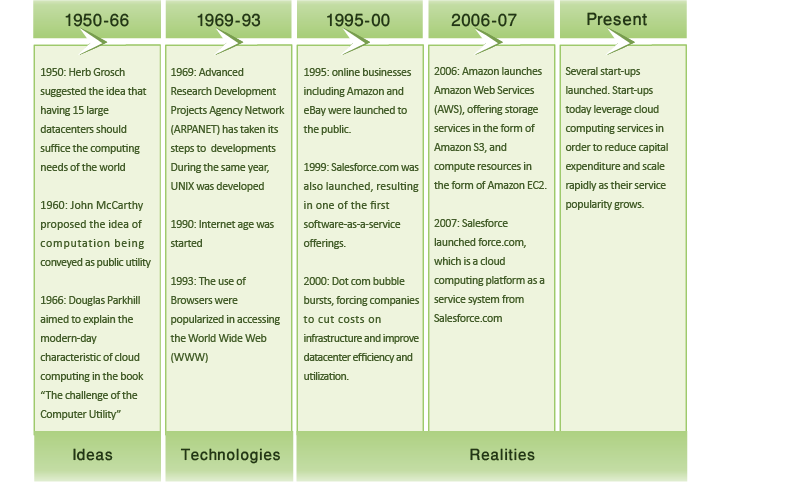
Figure 1.3: Evolution of cloud computing.
Evolution of Computing
Since the 1960s, some of the earliest forms of computers that were used by organizations were mainframe computers. Multiple users could share and connect to mainframes over basic serial connections using terminals. The mainframe was responsible for all the logic, storage, and processing of data, and the terminals connected to them had little if any computational power. These systems continued in widespread use for more than 30 years and, to some degree, continue to exist today.
With the birth of personal computing, cheaper, smaller, more powerful processors and memory led to a swing in the opposite direction, in which users ran their own software and stored data locally. This situation, in turn, led to issues of ineffective data sharing and rules to maintain order within an organization's IT environment.
Gradually, through the development of high-speed network technologies, local area networks (LANs) were born that allowed computers to connect and communicate with each other. Vendors designed systems that could encapsulate the benefits of both personal computers and mainframes, resulting in client-server applications that became popular over LANs. Clients would typically run client software (and process some data) or a terminal (for legacy applications) that connected to a server. The server, in the client-server model, provided application, storage, and data logic.
Eventually, in the 1990s, the global information age emerged with the Internet rapidly being adopted. Network bandwidth improved by many orders of magnitude, from ordinary dial-up access to dedicated fiber connectivity today. In addition, cheaper and more powerful hardware emerged. Furthermore, the evolution of the World Wide Web and dynamic websites necessitated multitier architectures.
Multitier architectures enabled the modularization of software by separating the application's presentation, logic, and storage layers as individual entities. With this modularization and decoupling, it was not long before individual software entities were running on distinct physical servers (typically due to differences in hardware and software requirements). This led to an increase of individual servers in organizations; however, it also led to poor average utilization of server hardware. In 2009, the International Data Corporation (IDC) estimated that the average x86 server had a utilization rate of approximately 5 to 10%[2].
Virtual machine technology matured well enough in the 2000s to become available as commercial software. Virtualization enables an entire server to be encapsulated as an image, which can be run seamlessly on hardware and enable multiple virtual servers to run simultaneously on a single physical server and share hardware resources. Virtualization thus enables servers to be consolidated, which accordingly improves system utilization.
Simultaneously, grid computing gained traction in the scientific community in an effort to solve large-scale problems in a distributed fashion. With grid computing, computer resources from multiple administrative domains work in unison for a common goal. Grid computing brought forth many resource-management tools (for example, schedulers and load balancers) to manage large-scale computing resources.
As the various computing technologies evolved, so did the economics of computing. Even during the early days of mainframe-based computing, companies such as IBM offered to host and run computers and software for various organizations such as banks and airlines. In the Internet Age, third-party web hosting also became popular. With virtualization, however, providers have unparalleled flexibility in accommodating multiple clients on a single server, sharing hardware and resources between them.
The development of these technologies, coupled with the economic model of utility computing, is what eventually evolved into cloud computing.
Enabling Technologies
Cloud computing has various enabling technologies (Figure 1.4), which include networking, virtualization and resource management, utility computing, programming models, parallel and distributed computing, and storage technologies.
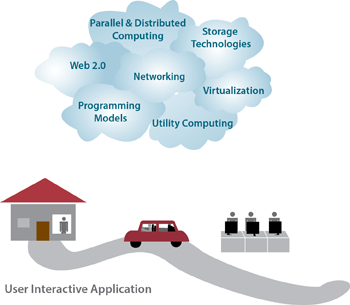
Figure 1.4: The enabling technologies in cloud computing.
The emergence of high-speed and ubiquitous networking technologies has greatly contributed to cloud computing as a viable paradigm. Modern networks make it possible for computers to communicate in a fast and reliable manner, which is important if we are to use services from a cloud provider. This enabled the user experience with software running in a remote data center to be comparable to the experience of software running on a personal computer. Web mail is a popular example, as is office productivity software. In addition, virtualization is key to enabling cloud computing. Virtualization allows managing the complexity of the cloud via abstracting and sharing its resources across users through multiple virtual machines. Each virtual machine can execute its own operating system and associated application programs.
Technologies such as large-scale storage systems, distributed file systems, and novel database architectures are crucial for managing and storing data in the cloud. Utility computing offers numerous charging structures for the leasing of compute resources. Examples include pay-per-resource-hour, pay-per-guaranteed-throughput, and pay-per-data stored per month, etc.
Parallel and distributed computing allow distributed entities located at networked computers to communicate and coordinate their actions in order to solve certain problems, represented as parallel programs. Writing parallel programs for distributed clusters is inherently difficult. To achieve high programming efficiency and flexibility in the cloud, a programming model is required.
Programming models for clouds give users the flexibility to express parallel programs as sequential computation units (for example, functions as in MapReduce and vertices as in GraphLab). Such programming models' runtime systems typically parallelize, distribute, and schedule computational units, manage inter-unit communication, and tolerate failures.
References
Simson L. Garfinkel (1999). Architects of the Information Society: Thirty-Five Years of the Laboratory for Computer Science at MIT. MIT Press.
Michelle Bailey (2009). The Economics of Virtualization: Moving Toward an Application-Based Cost Model. VMware Sponsored IDC Whitepaper.