Distributed file systems
- 10 minutes
Switching gears now, we will discuss distributed file systems (DFSs). A distributed file system is a file system that has files distributed among multiple file servers.
It is important to note that in a distributed file system, the client views a single, global namespace that encompasses all the files across all the file system servers, as shown in the following figure.
As with a shared file system, DFSs require metadata management so that clients can locate the required files and file blocks across the file servers. The metadata server can be asymmetric (single metadata server) or symmetric (metadata servers on each file server), similar to shared file systems.
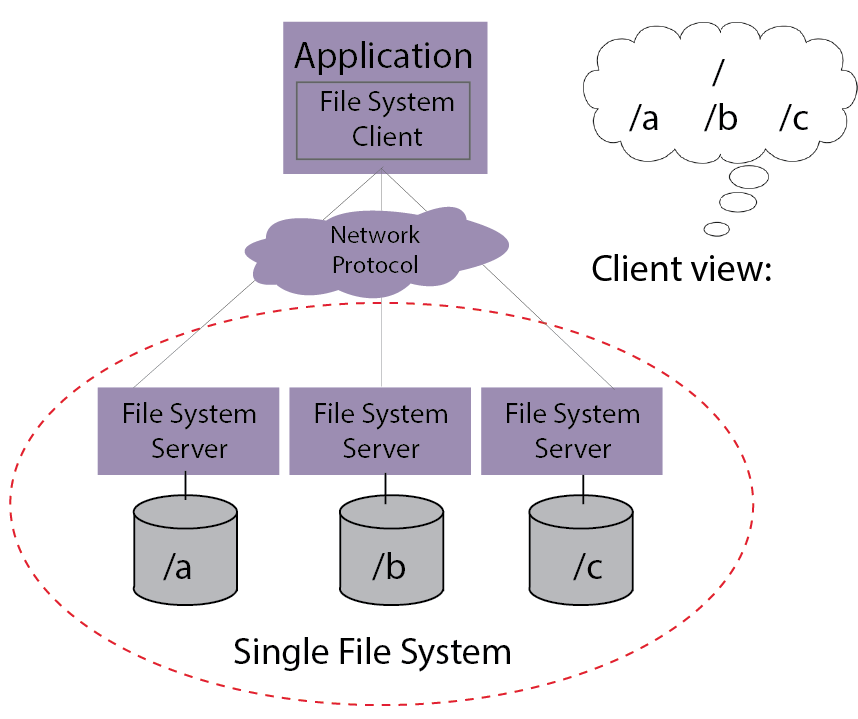
Figure 12: Distributed file system1
Origins and evolution of distributed file systems
Examples of DFSs include the Andrew File System (AFS). AFS is a distributed file system that enables cooperating hosts (clients and servers) to efficiently share file system resources across both local area and wide area networks. AFS consists of cells, an administrative grouping of servers that present a single cohesive file system. Cells can be combined to form a single global namespace. Any client that accesses data from AFS will first copy the file locally to the client. Changes to the file will be made locally as long as the file is open. When the file is closed, the AFS client will sync the changes back to the server. An evolution of AFS is CODA, which is a distributed file system that improves on AFS, particularly with respect to sharing semantics and replication.
In 2003, Google revealed the design of its distributed file system, called GFS2, which was designed from scratch to provide efficient, reliable access to data using large clusters of commodity hardware. GFS is designed to store very large files as chunks (typically 64 MB in size), in a replicated fashion. Although GFS has a singular client view like AFS, the location of file chunks is exposed to the user, given opportunities to fetch files from the closest available replica. GFS is the inspiration behind the Hadoop Distributed File System (HDFS), which is covered in detail in the next module.
Design characteristics in distributed file systems
DFSs are typically deployed on multiple file-sharing nodes and are intended for use by multiple users at the same time. As with any shared resource, multiple design considerations must be considered:
- Fault tolerance
- Replication
- Consistency
- File-sharing semantics
Shared and networked file systems must be designed with failures in mind. Fault tolerance can be defined as the ability of a system to respond gracefully to unexpected hardware and software failures. In the case of file systems, fault tolerance requires the file system to respond gracefully to disk, node, and network failures. With shared and networked file systems, the odds of a disk failing increase with the number of disks in the array/pool. At the hardware level, faults can be tolerated by using some form of RAID.
At the file system level, data in distributed systems may be replicated; the same data may be maintained on one or more nodes in the distributed file system. This replication is done in order to:
- Improve performance (a client can potentially find a replica that is nearest to its location).
- Enhance the scalability of the system (simultaneous requests for data can be handled by different servers).
- Enhance reliability (replicas can provide fault tolerance and provide a checksum mechanism to ensure the integrity of the data).
Replication is the primary mechanism to deliver fault tolerance in DFSs. The capacity of a DFS is usually impacted by the replication factor (the number of active replicas to be maintained). For example, a DFS configured with a raw capacity of 15 TB can store only 5 TB of data if all the data is triple replicated.
Replication poses the additional challenge of consistency. In a large distributed system, updates to files must be applied to all replicas. The level of consistency supported in a DFS also affects client interactions with the file system.
When a resource, such as a file, is shared between multiple users, it is necessary to define the semantics of reading and writing to the file. Following are some of the semantics that can be implemented with a DFS:
- UNIX semantics: In UNIX semantics, a read operation performed immediately after a write operation will always return the value that was just written. UNIX employs the strictest file-sharing semantics in file systems. With UNIX semantics, performance may be affected because reads and writes may have to be serialized to ensure that all file system operations are consistent.
- Session semantics: In session semantics, changes to an open file are initially visible only to the process that modified the file. Once the file is closed, the changes are made visible to other processes. Session semantics relaxes the strict requirements employed by UNIX semantics, but the question of conflict handling emerges: When two clients are simultaneously editing the same file, whose session is honored? Some approaches honor only the last client to close the file, while others might even be unspecified.
- Immutable semantics: In immutable semantics, files can be written only once to a file system and cannot be reopened for further modification. Files can be deleted, or a new file can be created to replace the old one. If two or more processes try to replace the file simultaneously, the file system should resolve the tie through first in, first out (FIFO) order or in a non-deterministic fashion. The file system must also account for the possibility that one of the processes can replace a file while another is busy reading it. In this scenario, the file system should either arrange for the reader to continue using the old file or detect that the file is now replaced and not allow the reading process to continue accessing the file.
- Atomic transactions: In an atomic transaction model, the start and end of sequences of read and write operations are marked as being a transaction in which the changes to files happen atomically (changes are either committed as a whole or not committed at all).
References
- Thomas Rivera (2012). The Evolution of File Systems SNIA Tutorial
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003). The Google File Systems 19th ACM Symposium on Operating Systems Principles