Explore performance and security
The Azure ecosystem offers several performance and security options for SQL Server instance on Azure virtual machine. Each option provides several capabilities, such as different disk types that meet the capacity and performance requirements of your workload.
Storage considerations
SQL Server requires good storage performance to deliver robust application performance, whether it be an on-premises instance or installed in an Azure VM. Azure provides a wide variety of storage solutions to meet the needs of your workload. While Azure offers various types of storage (blob, file, queue, table) in most cases SQL Server workloads will use Azure managed disks. The exceptions are that a Failover Cluster Instance can be built on file storage and backups will use blob storage. Azure-managed disks act as a block-level storage device that is presented to your Azure VM. Managed disks offer a number of benefits including 99.999% availability, scalable deployment (you can have up to 50,000 VM disks per subscription per region), and integration with availability sets and zones to offer higher levels of resiliency in case of failure.
Azure-managed disks all offer two types of encryption. Azure Server-side encryption is provided by the storage service and acts as encryption-at-rest provided by the storage service. Azure Disk Encryption uses BitLocker on Windows, and DM-Crypt on Linux to provide OS and Data disk encryption inside of the VM. Both technologies integrate with Azure Key Vault and allow you to bring your own encryption key.
Each VM will have at least two disks associated with it:
Operating System disk – Each virtual machine will require an operating system disk that contains the boot volume. This disk would be the C: drive in the case of a Windows platform virtual machine, or /dev/sda1 on Linux. The operating system will be automatically installed on the operating system disk.
Temporary disk – Each virtual machine will include one disk used for temporary storage. This storage is intended to be used for data that doesn't need to be durable, such as page files or swap files. Because the disk is temporary, you shouldn't use it for storing any critical information like database or transaction log files as they'll be lost during maintenance or a reboot of the virtual machine. This drive will be mounted as D:\ on Windows, and /dev/sdb1 on Linux.
Additionally, you can and should add additional data disks to your Azure VMs running SQL Server.
- Data disks – The term data disk is used in the Azure portal, but in practice these are just additional managed disks added to a VM. These disks can be pooled to increase the available IOPs and storage capacity, using Storage Spaces on Windows or Logical Volume Management on Linux.
Furthermore, each disk can be one of several types:
| Feature | Ultra Disk | Premium SSD | Standard SSD | Standard HDD |
|---|---|---|---|---|
| Disk type | SSD | SSD | SSD | HDD |
| Best for | IO-intensive workload | Performance sensitive workload | Lightweight workloads | Backups, non-critical workloads |
| Max disk size | 65,536 GiB | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| Max throughput | 2,000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Max IOPS | 160,000 | 20,000 | 6,000 | 2,000 |
The best practices for SQL Server on Azure recommend using Premium Disks pooled for increased IOPs and storage capacity. Data files should be stored in their own pool with read-caching on the Azure disks.
Transaction log files won't benefit from this caching, so those files should go into their own pool without caching. TempDB can optionally go into its own pool, or using the VM’s temporary disk, which offers low latency since it's physically attached to the physical server where the VMs are running. Properly configured Premium SSD will see latency in single digit milliseconds. For mission critical workloads that require latency lower than that, you should consider Ultra SSD.
Security considerations
There are several industry regulations and standards that Azure complies with that makes it possible to build a compliant solution with SQL Server running in a virtual machine.
Microsoft Defender for SQL
Microsoft Defender for SQL provides Azure Security Center security features such as vulnerability assessments and security alerts.
Azure Defender for SQL can be used to identify and mitigate potential vulnerabilities in your SQL Server instance and database. The vulnerability assessment feature can detect potential risks in your SQL Server environment and help you remediate them. It also provides insight into your security state and actionable steps to resolve security issues.
Azure Security Center
Azure Security Center is a unified security management system that evaluates and offers opportunities for improving several security aspects of your data environment. Azure Security Center provides a comprehensive view of the security health of all your hybrid cloud assets.
Performance considerations
Most of the existing on-premises SQL Server performance features are also available on Azure virtual machines (VMs). Among the options offered is data compression, which can improve the performance of I/O-intensive workloads while decreasing the size of the database. Similarly, table and index partitioning can improve query performance of large tables, while improving performance and scalability.
Table partitioning
Table partitioning provides many benefits, but often this strategy is only considered when the table becomes large enough that starts compromising query performance. Identifying which tables are candidates for table partitioning is a good practice that could lead to fewer disruptions and interventions. When you filter your data using your partition column, only a subset of the data is accessed, not the entire table. Similarly, maintenance operations on a partitioned table will reduce maintenance duration, for example, by compressing specific data in a particular partition or rebuilding specific partitions of an index.
There are four main steps required when defining a table partition:
- The filegroups creation, which defines the files involved when the partitions are created.
- The partition function creation, which defines the partition rules based on the specified column.
- The partition scheme creation, which defines the filegroup of each partition.
- The table to be partitioned.
The example below illustrates how to create a partition function for January 1, 2021 through December 1, 2021, and distribute the partitions across different filegroups.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Data compression
SQL Server offers different options for compressing data. While SQL Server still stores compressed data on 8 KB pages, when the data is compressed, more rows of data can be stored on a given page, which allows the query to read fewer pages. Reading fewer pages has a twofold benefit: it reduces the amount of physical IO performed and it allows more rows to be stored in the buffer pool, making more efficient use of memory. We recommend enabling database page compression where appropriate.
The tradeoffs to compression are that it does require a small amount of CPU overhead, however, in most cases the storage IO benefits far outweigh any additional processor usage.
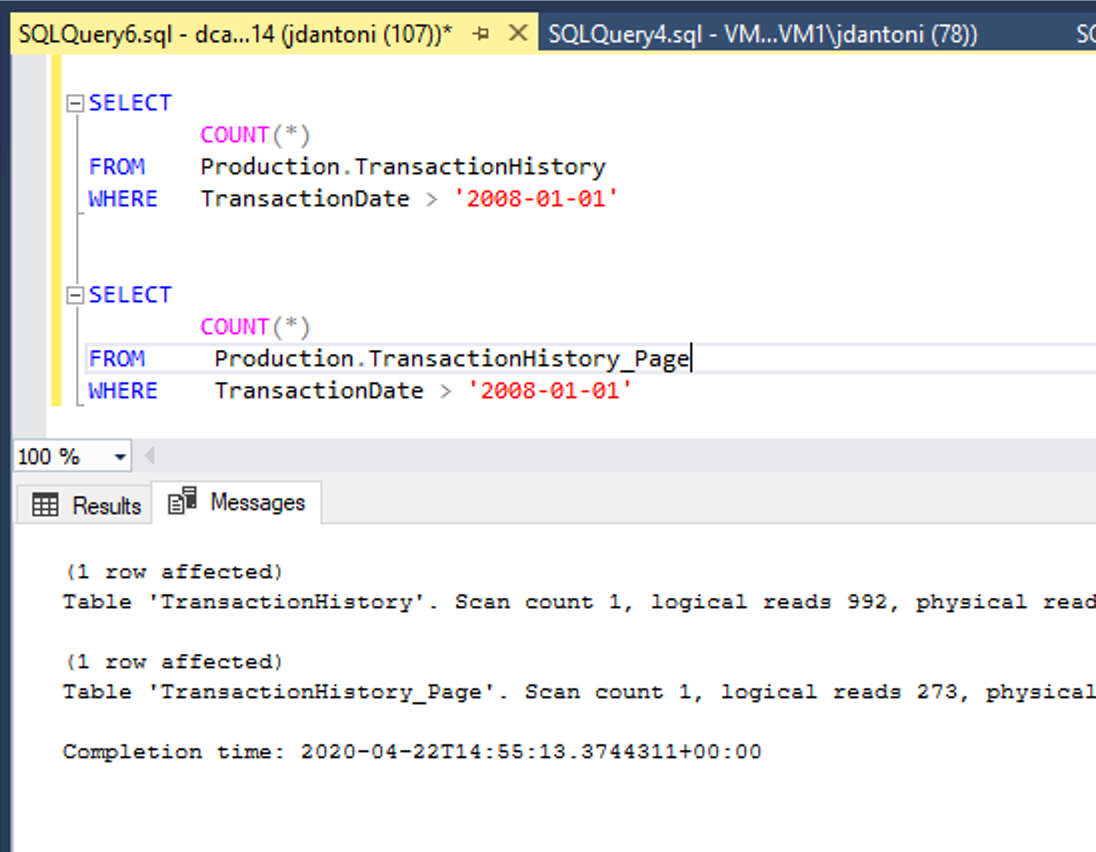
The image above shows this performance benefit. These tables have same underlying indexes; the only difference is that the clustered and nonclustered indexes on the Production.TransactionHistory_Pagetable are page compressed. The query against the page compressed object performs 72% fewer logical reads than the query that uses the uncompressed objects.
Compression is implemented in SQL Server at the object level. Each index or table can be compressed individually, and you have the option of compressing partitions within a partitioned table or index. You can evaluate how much space you'll save by using the sp_estimate_data_compression_savings system stored procedure. Prior to SQL Server 2019, this procedure didn't support columnstore indexes, or columnstore archival compression.
Row compression - Row compression is fairly basic and doesn't incur much overhead; however, it doesn't offer the same amount of compression (measured by the percentage reduction in storage space required) that page compression may offer. Row compression basically stores each value in each column in a row in the minimum amount of space needed to store that value. It uses a variable-length storage format for numeric data types like integer, float, and decimal, and it stores fixed-length character strings using variable length format.
Page compression - Page compression is a superset of row compression, as all pages will initially be row compressed prior to applying the page compression. Then a combination of techniques called prefix and dictionary compression are applied to the data. Prefix compression eliminates redundant data in a single column, storing pointers back to the page header. After that step, dictionary compression searches for repeated values on a page and replaces them with pointers, further reducing storage. The more redundancy in your data, the greater the space savings when you compress your data.
Columnstore archival compression - Columnstore objects are always compressed, however, they can be further compressed using archival compression, which uses the Microsoft XPRESS compression algorithm on the data. This type of compression is best used for data that is infrequently read, but needs to be retained for regulatory or business reasons. While this data is further compressed, the CPU cost of decompression tends to outweigh any performance gains from IO reduction.
Additional options
Below is a list of additional SQL Server features and actions to consider for production workloads:
- Enable backup compression
- Enable instant file initialization for data files
- Limit autogrowth of the database
- Disable autoshrink/autoclose for the databases
- Move all databases to data disks, including system databases
- Move SQL Server error log and trace file directories to data disks
- Set max SQL Server memory limit
- Enable lock pages in memory
- Enable optimize for adhoc workloads for OLTP heavy environments
- Enable Query Store.
- Schedule SQL Server Agent jobs to run DBCC CHECKDB, index reorganize, index rebuild, and update statistics jobs
- Monitor and manage the health and size of the transaction log files
For more information about performance best practices, see Best practices for SQL Server on Azure VMs.