Design a geographically distributed application architecture
- 8 minutes
When our networking components route requests to multiple regions to mitigate the effects of a regional outage, we must design application services that can respond to those requests in both primary and standby regions.
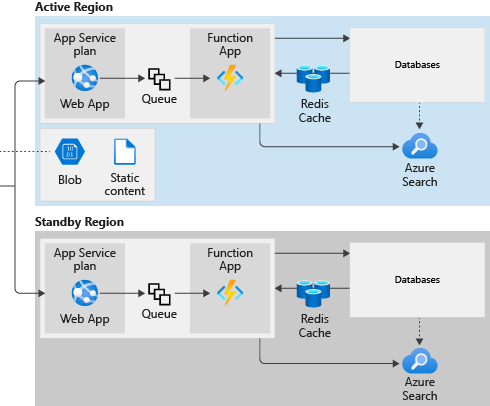
Recall from earlier that we plan to configure Azure Front Door with priority back-end assignment. We assign the East US region as our primary region, and the West US region as our standby region. When a regional failure occurs, requests route to the App Service in the nonfailing region. We have to configure resources in each region to support these failovers for user access, replicated storage, and application code.
Heres, we examine the application services in our solution and determine whether they need to be modified to function in a multi-region architecture. Specifically, we look at Active Directory, static content storage, web apps, web APIs, queues, Azure functions, and data caches.
Microsoft Entra ID
In our shipments tracking portal, users can track the delivery of their purchases by entering a tracking number. However, regular users can register for membership to access advanced features, such as delivery promptness and other statistics. We've developed the tracking portal to store user accounts in Microsoft Entra ID.
Microsoft Entra ID is designed as a global system by default. As such, it's not vulnerable to regional failures, and we don't have to modify this component of the system.
Azure Blob Storage
Static content, such as images and videos, are stored in Azure Storage accounts as Binary Large Objects (Blobs) and served to users through the Azure CDN.
In our original design, the storage account is contained in a single region because we chose to use Locally Redundant Storage (LRS). Our data is replicated only within a single datacenter with LRS. The storage account, therefore, is unavailable if there's a regional outage in this configuration. Any static content already cached by the CDN remains available to users.
The same is true of Zone Redundant Storage (ZRS). Even though data replicates to different data centers in this configuration, all these data centers are still in the same region. A regional outage also affects the storage account in this configuration.
In our design, we rely heavily on our CDN configuration to cache static content. There's a chance that, during an outage, a user might request a static file that isn't yet in the CDN cache. This request would result in a graphic or video that can't be displayed.
We can eliminate this possibility by replicating the storage account to multiple regions when we choose a geo-redundant storage option. A read-only replication option is also available to prevent adding static content during a regional outage.
We have two options to choose from when we need to enable geo-redundancy. These options are Read-Access Geo-Redundant Storage (RA-GRS) and Read-Access Geo-Zone-Redundant Storage (RA-GZRS). The choice we make depends on our budget and the percentage of up time that we need.
Azure App Service and Azure Function Apps
Our shipments tracking portal implements two Azure App Services. The first App Service hosts a web app that implements the user-facing web interface, and the second hosts a web API used by mobile apps to track shipments data. All of our background tasks run as Azure Function apps.
In our original design, each Azure App Service is localized to a single Azure region. We create a second App Service in the secondary region (West US) and deploy the web project there to support the new multi-region architecture. We configure the Azure Front Door priority routing mode to send requests to our secondary region when the primary region is unavailable.
To ensure the failover is as smooth as possible, make sure the web application doesn't store any session state information in memory. We change our website to make sure we don't end up with data loss. For example, if our code stores a list of the users' shipments in memory, this list would be lost if a failover occurred.
Each web request is handled without impacting the other when no session state is stored. If a failover occurs in the middle of a user's session, the failover should be transparent to the user.
We make a similar change to our Azure Function apps. We create a separate instance of the Azure Function in the secondary region and deploy the same custom code to it as runs in the primary region.
Important
When you deploy an update to the custom code in the App Service or Function App service, remember to distribute it to all the instances of the App Service. If you want to automate this process, Azure DevOps has tools that can help.
Azure Storage Queues
In our original single-region architecture, we used a queue in an Azure Storage account to manage communications between the App Service and the function app. When the web app or the web API needs to run a background task, it places a message with all the required information in the queue. The function app monitors the queue for new messages and executes the background task by running the necessary queries against the data stores.
We can manage a high demand in web requests in an orderly way when we use a queue in this way. When there are many background tasks to run, the queue may build up, but tasks aren't dropped. They stay in the queue until they're processed. The function apps work through the queue and reduce its size when demand falls. If demand persists, we increase the number of instances of the function app.
For the multi-region version of the shipments tracking portal, we must make sure that queue items aren't lost when failover occurs. Our queue is defined in Azure Storage, and we can use a redundancy option for geo-replication.
Keep in mind that we can't use a read-access redundancy option since our queue supports read and write operations. The App Service must add items to the queue, and the function app must remove completed items from the queue. Use Geo-Redundant Storage (GRS) or Geo-Zone-Redundant Storage (GZRS) instead.
Azure Redis Cache
We're using Azure Redis Cache to maximize the performance of data storage. Redis caches all query results generated from our apps as they request data from our database. Any further queries for similar data don't need a database query, and are fetched from the Redis cache.
For the multi-region architecture, we create a Redis Cache instance in both primary and standby regions. Keep in mind that when a failover occurs, the Redis Cache in the standby region is likely to be empty. That empty cache doesn't cause any errors, but performance may temporarily drop, as data fills the new cache.