Design a data integration solution with Azure Data Factory
Azure Data Factory is a cloud-based data integration service that can help you create and schedule data-driven workflows. You can use Azure Data Factory to orchestrate data movement and transform data at scale. The data-driven workflows, or pipelines, ingest data from disparate data stores. Azure Data Factory is an ETL data integration process, which stands for extract, transform, and load. This integration process combines data from multiple data sources into a single data store.
Things to know about Azure Data Factory
There are four major steps to create and implement a data-driven workflow in the Azure Data Factory architecture:
Connect and collect. First, ingest the data to collect all the data from different sources into a centralized location.
Transform and enrich. Next, transform the data by using a compute service like Azure Databricks and Azure HDInsight Hadoop.
Provide continuous integration and delivery (CI/CD) and publish. Support CI/CD by using GitHub and Azure Pipelines to deliver the ETL process incrementally before publishing the data to the analytics engine.
Monitor. Finally, use the Azure portal to monitor the pipeline for scheduled activities and for any failures.
The following diagram shows how Azure Data Factory orchestrates the ingestion of data from different data sources. Data is ingested into a Storage blob and stored in Azure Synapse Analytics. Analysis and visualization components are also connected to Azure Data Factory. Azure Data Factory provides a common management interface for all of your data integration needs.
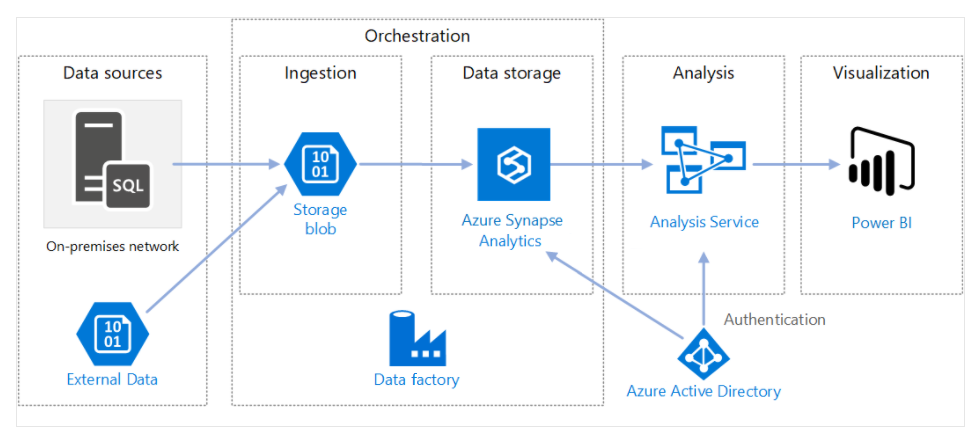
Components of Azure Data Factory
Azure Data Factory has the following components that work together to provide the platform for data movement and data integration.
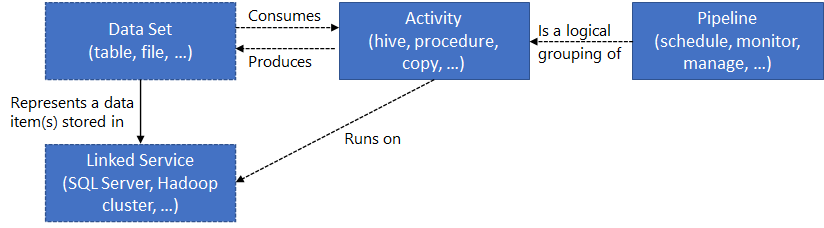
- Pipelines and activities: Pipelines provide a logical grouping of activities that perform a task. An activity is a single processing step in a pipeline. Azure Data Factory supports data movement, data transformation, and control activities.
- Datasets: Datasets are data structures within your data stores.
- Linked services: Linked services define the required connection information needed for Azure Data Factory to connect to external resources.
- Data flows: Data flows allow data engineers to develop data transformation logic without writing code. Data flow activities can be operationalized by using existing Azure Data Factory scheduling, control, flow, and monitoring capabilities.
- Integration runtimes: Integration runtimes are the bridge between the activity and linked Services objects. There are three types of integration runtime: Azure, self-hosted, and Azure-SSIS.
Business scenario
A significant challenge for a fast-growing home improvement retailer like Tailwind Traders is that it generates a high volume of data stored in relational, nonrelational, and other storage systems in both the cloud and on-premises. Management wants actionable business insights from this data as near real time as possible. Additionally, the sales team wants to set up and roll out up-selling and cross-selling solutions. How can you create a large-scale data ingestion solution in the cloud? What Azure services and solutions should you adopt to help with the movement and transformation of data between various data stores and compute resources?
Let's review how the Azure Data Factory components are involved in a data preparation and movement scenario for Tailwind Traders. They have many different data sources to connect to and that data needs to be ingested and transformed through stored procedures that are run on the data. Finally, the data should be pushed to an analytics platform for analysis.
In this scenario, the linked service enables Tailwind Traders to ingest data from different sources and it stores connection strings to fire up compute services on demand.
You can execute stored procedures for data transformation that happens through the linked service in Azure-SSIS, which is the integration runtime environment for Tailwind Traders.
The datasets components are used by the activity object and the activity object contains the transformation logic.
You can trigger the pipeline, which is all the activities grouped together.
You can use Azure Data Factory to publish the final dataset consumed by technologies, such as Power BI or Machine Learning.
Things to consider when using Azure Data Factory
Evaluate Azure Data Factory against the following decision criteria and consider how the service can benefit your data integration solution for Tailwind Traders.
Consider requirements for data integration. Azure Data Factory serves two communities: the big data community and the relational data warehousing community that uses SQL Server Integration Services (SSIS). Depending on your organization's data needs, you can set up pipelines in the cloud by using Azure Data Factory. You can access data from both cloud and on-premises data services.
Consider coding resources. If you prefer a graphical interface to set up pipelines, then Azure Data Factory authoring and monitoring tool is the right fit for your needs. Azure Data Factory provides a low code/no code process for working with data sources.
Consider support for multiple data sources. Azure Data Factory supports 100+ connectors, including Microsoft Fabric Warehouse and Fabric Lakehouse alongside Azure, AWS, Google Cloud, SaaS, and database sources.
Consider serverless infrastructure. There are advantages to using a fully managed, serverless solution for data integration. There's no need to maintain, configure, or deploy servers, and you gain the ability to scale with fluctuating workloads.