Design for monitoring
As part of a machine learning operations (MLOps) architecture, you should think about how to monitor your machine learning solution.
Monitoring is beneficial in any MLOps environment. You'll want to monitor the model, the data, and the infrastructure to collect metrics that help you decide on any necessary next steps.
Monitor the model
Most commonly, you want to monitor the performance of your model. During development, you use MLflow to train and track your machine learning models. Depending on the model you train, there are different metrics you can use to evaluate whether the model is performing as expected.
To monitor a model in production, you can use the trained model to generate predictions on a small subset of new incoming data. By generating the performance metrics on that test data, you're able to verify whether the model is still achieving its goal.
Additionally, you may also want to monitor for any responsible artificial intelligence (AI) issues. For example, whether the model is making fair predictions.
Before you can monitor a model, it's important to decide which performance metrics you want to monitor and what the benchmark for each metric should be. When should you be alerted that the model isn't accurate anymore?
Monitor the data
You typically train a machine learning model using a historical dataset that is representative of the new data that your model receives when deployed. However, over time there may be trends that change the profile of the data, making your model less accurate.
For example, suppose a model is trained to predict the expected gas mileage of an automobile based on the number of cylinders, engine size, weight, and other features. Over time, as car manufacturing and engine technologies advance, the typical fuel-efficiency of vehicles might improve dramatically; making the model's predictions trained on older data less accurate.
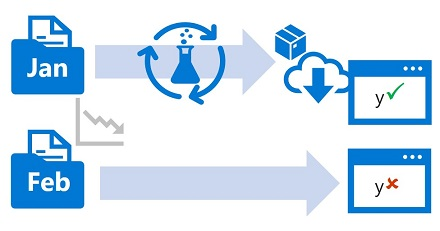
This change in data profiles between current and the training data is known as data drift, and it can be a significant issue for predictive models used in production. It's therefore important to be able to monitor data drift over time, and retrain models as required to maintain predictive accuracy.
Monitor the infrastructure
Next to monitoring the model and data, you should also monitor the infrastructure to minimize cost and optimize performance.
Throughout the machine learning lifecycle, you use compute to train and deploy models. With machine learning projects in the cloud, compute may be one of your biggest expenses. You therefore want to monitor whether you are efficiently using your compute.
For example, you can monitor the compute utilization of your compute during training and during deployment. By reviewing compute utilization, you know whether you can scale down your provisioned compute, or whether you need to scale out to avoid capacity constraints.
Tip
Learn more about monitoring the Azure Machine Learning workspace and its resources.