Automation and Resiliency for Modern Platforms
As platforms evolve, the concept of Everything as Code (EaC) becomes essential in platform engineering, extending the principles of automation and scalability to every aspect of system management, from infrastructure to application configurations. EaC expands the idea of Infrastructure as Code (IaC) by incorporating the entire stack—encompassing application code, configuration, security policies, and operational procedures—into code that can be versioned, automated, and managed through continuous integration and deployment (CI/CD) pipelines. This approach not only simplifies the process of scaling complex platforms but also ensures that every component can be easily tested, updated, and maintained in a consistent, automated manner.
In this context, automation and configuration management become critical enablers for achieving reliability and agility across all layers of the platform. With EaC, the manual steps traditionally required for provisioning, configuring, and deploying resources are replaced with automated processes that can be monitored and adjusted as needed. CI/CD pipelines play a crucial role in this transformation by enabling continuous delivery of code, configurations, and infrastructure changes, thus streamlining development cycles and reducing the risk of human error. By automating both infrastructure and application deployment, EaC empowers platform engineers to build and manage resilient, scalable systems with enhanced speed, flexibility, and reliability.
Infrastructure as Code (IaC) and Everything as Code (EaC)
Infrastructure as Code (IaC) is a transformative approach that automates the management and provisioning of infrastructure, enhancing consistency, repeatability, and scalability across environments. By treating infrastructure elements like virtual machines, networks, and storage as code, engineers can define, deploy, and manage these resources programmatically. Instead of manually configuring systems, engineers create templates or scripts that specify the desired state of infrastructure, which are then executed by IaC tools to provision resources automatically, ensuring environments are accurately created and configured.
Everything as Code (EaC) applies the Infrastructure as Code (IaC) pattern to more than just application delivery, extending to any tools or services that need to be provisioned and configured. For example, shared infrastructure like Kubernetes clusters, monitoring systems, or even collaboration tools can be managed in the same way. Centralized repositories house the code for these configurations, and developers can submit pull requests, which are reviewed by operations teams before being merged. Once merged, CI/CD tools are triggered to automate the provisioning and deployment processes.
The concept of Everything as Code (EaC) applies Git’s secure and auditable framework to manage various types of configurations and infrastructure in a consistent, automated manner. Git repositories act as the centralized, secure source for various types of configuration files, whether for infrastructure provisioning or other services, with features like commit history, pull requests, and branch protection enhancing collaboration and control.
Let's consider a scenario that illustrates the integration of GitHub Actions with IaC and deployment identities housed in Azure Deployment Environments.
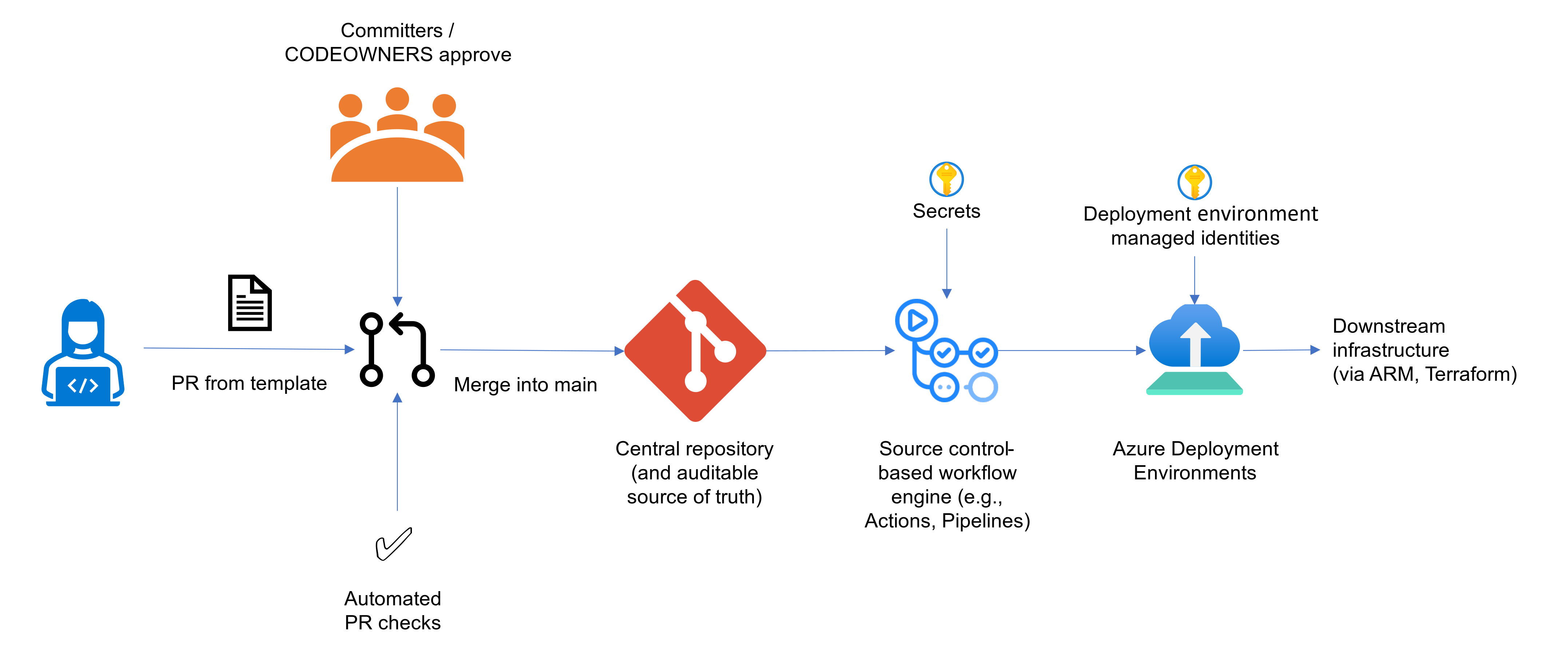
In this setup, a secure, centralized repository stores a collection of files that define what should be provisioned and configured, including formats like Bicep, Terraform, Helm charts, and other Kubernetes-native configurations. The repository is managed by an operations team or administrators, and developers (or automated systems) can submit pull requests for updates. Once the pull requests are reviewed and merged into the main branch by the administrators, the same CI/CD tools used for application development are triggered to process the changes and implement them across the environment.
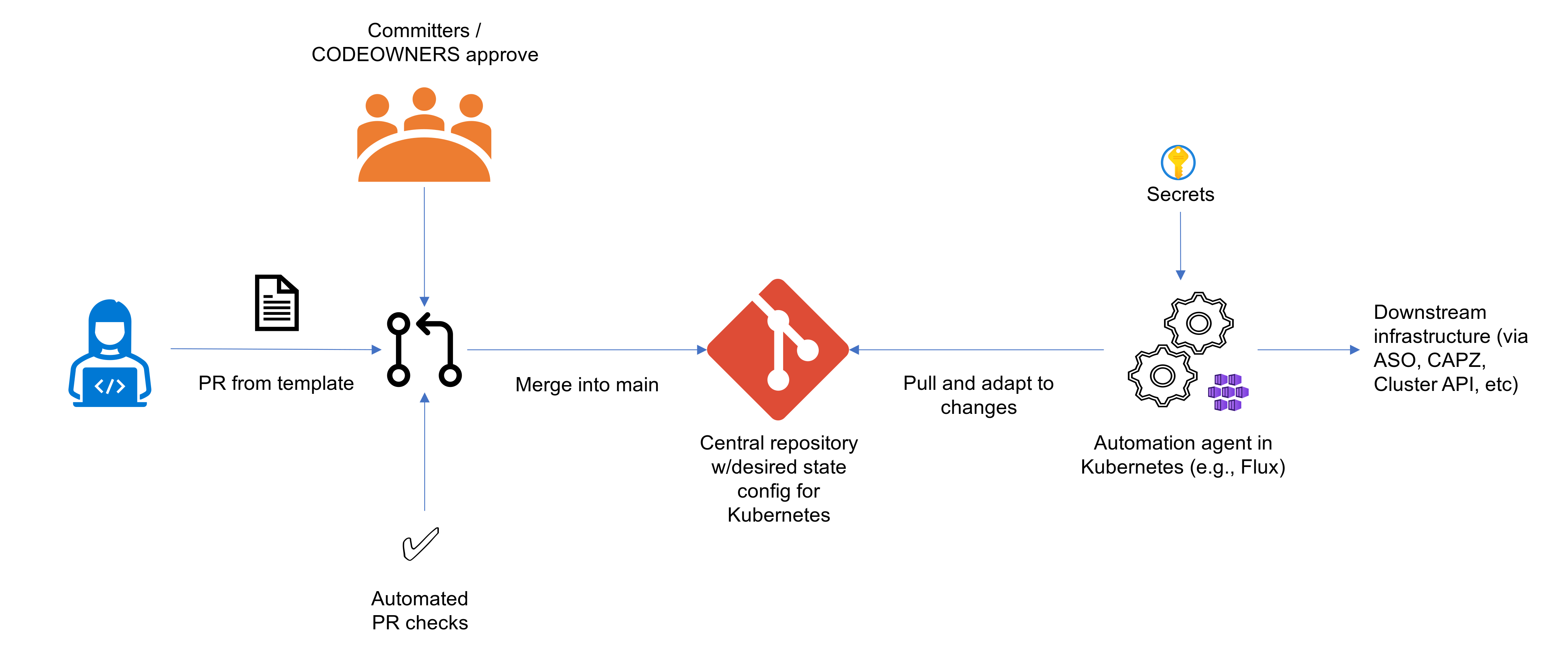
As with application development, any secrets or managed identities required for these workflows are securely stored in the pipeline engine or within the native capabilities of the provisioning service. Since the individuals making the pull requests won't have direct access to these secrets, this process ensures that developers can initiate actions they don’t have direct permission to execute. This approach follows the principle of least privilege while still providing developers with a self-service option for making changes.
In some cases, the self-service automation needs might not align with the Everything as Code pattern, especially when dealing with tasks that don't naturally fit into file-based workflows or when a user interface is needed to drive the process. Most CI systems, like GitHub Actions and Azure Pipelines, allow you to set up parameterized workflows that can be manually triggered through their UI or CLI. This flexibility enables you to automate tasks that don't require a pull request process, or that should be fully automated without file-based triggers. Additionally, these workflows can be triggered via APIs, such as GitHub’s Actions REST API or Azure DevOps Pipeline API, allowing integration with custom user experiences.
These manual or externally triggered workflows still benefit from the same security, auditability, and visibility advantages as the Everything as Code approach. CI/CD systems track activities, report status, and generate detailed logs, which provide valuable insights for developers and operations teams to diagnose issues. However, it's worth noting that actions executed by these workflows appear as system identities (for example, service principals or managed identities) in downstream systems. While the CI/CD system provides visibility into who triggered the workflows, it's important to assess whether this level of tracking meets your auditing needs.
CI/CD Pipelines for Automated Deployment
Continuous Integration and Continuous Deployment (CI/CD) pipelines automate the software delivery lifecycle, reducing manual intervention and improving the speed and reliability of code releases. A typical CI/CD pipeline consists of stages like code integration, testing, building, and deployment, with automation at its core. The CI portion focuses on integrating and testing code changes, running unit tests, static code analysis, and packaging the application. The CD portion automates the deployment of the application to staging or production environments, ensuring that infrastructure changes, defined through IaC templates, are applied during deployment to ensure alignment between infrastructure and application code.
The integration of IaC with CI/CD pipelines is a powerful tool for automating infrastructure provisioning alongside application deployments. This integration minimizes configuration drift and ensures that infrastructure and application environments are consistently aligned. Automated testing is a vital component of CI/CD, helping to ensure that both the application code and the infrastructure it relies on are error-free before deployment. Tools such as Terraform's Test Framework or Packer can validate IaC templates, ensuring they meet expectations before they're deployed.
Security is a critical consideration in CI/CD pipelines. Security scanning tools, such as Static and Dynamic Application Security Testing (SAST and DAST), can be integrated into the pipeline to identify vulnerabilities in both the application and infrastructure code before production deployment. Additionally, managing sensitive data securely using encrypted secrets management systems are essential to protect access keys and certificates throughout the CI/CD process. By embedding security practices into the CI/CD pipeline, teams can catch vulnerabilities early, minimizing the risk of deploying insecure code or infrastructure.
Configuration Management and Automation
Configuration management tools are crucial for maintaining consistency across distributed and dynamic environments. While IaC handles infrastructure provisioning, configuration management tools automate the ongoing management and maintenance of system configurations after provisioning. These tools define the desired state of systems, automatically ensuring that servers and services are configured correctly and remain consistent across environments. By continuously monitoring systems, configuration management tools can detect and rectify any deviations from the desired state, preventing configuration drift and ensuring all environments—whether in test, staging, or production—are aligned.
In large, multicloud, or hybrid cloud environments, configuration management tools help ensure consistency across different cloud providers and on-premises data centers. These tools simplify cross-cloud operations, allowing teams to automate the provisioning, configuration, and maintenance of applications and services, regardless of the platform. In addition, many configuration management tools offer monitoring and alerting capabilities that provide real-time insights into infrastructure performance and security. They can also automatically apply patches or updates, ensuring systems remain secure and up-to-date.
Scaling becomes more efficient with configuration management tools, as they not only automate infrastructure provisioning but also ensure that configurations are applied consistently across new instances or containers. As new servers are added to a cloud environment, these tools ensure that required software is installed, configurations are updated, and services are aligned with organizational standards and security policies.
Together, IaC for provisioning and configuration management tools for ongoing management ensure that platforms remain scalable, resilient, and aligned with organizational needs. This level of automation is valuable in large, distributed environments where manual management would be inefficient and error-prone. Tools like PowerShell Desired State Configuration, Ansible, Chef, Puppet, Bicep, and Terraform each contribute to this automation in unique ways, enabling teams to focus on improving platform capabilities rather than managing configurations manually.
High Availability and Fault Tolerance
As organizations scale their platforms to accommodate an increasing number of users and transactions, ensuring high availability (HA) and fault tolerance becomes essential to maintaining customer trust and business continuity. In any environment, failures represent an unavoidable fact of life, so businesses must design their platforms to withstand disruptions without compromising performance or uptime.
High availability and fault tolerance are foundational to creating resilient platform architectures. When operating in Azure, achieving high availability typically involves implementing redundancy and distributing workloads across multiple availability zones. Availability zones offer fault isolation and allow services to remain operational even when a particular zone experiences an outage. By combining them with services such as Azure Load Balancer and Azure Front Door, platforms can ensure that traffic is automatically rerouted to healthy instances when failures occur, thus minimizing downtime.
While there's no general rule regarding support for availability zones, the tendency is to incorporate them into new services, especially those within the realm of platform engineering. For example, availability zones are enabled automatically for all resources in Azure Deployment Environments (as long as the target Azure region supports it).
Redundancy is also implemented through data replication across geographically distributed resources. For example, Azure SQL Database and Azure Cosmos DB provide built-in data replication, which ensures that data remains available even during localized failures. Automated health checks and failover mechanisms are crucial in detecting and responding to failures. Failover processes, such as automatic switchover to secondary instances, are configured to ensure services continue running without significant interruption.
To further enhance fault tolerance, it's essential to design for graceful recovery. Azure offers native tools like Azure Functions and Azure Logic Apps to implement retries, timeouts, and circuit breakers, which allow services to recover automatically from temporary issues without triggering cascading failures.
The ability to scale resources dynamically based on demand—enabled by services like Azure Virtual Machine Scale Sets and Azure Kubernetes Service (AKS)—also plays a critical role in maintaining high availability. These services allow platforms to seamlessly adjust to traffic fluctuations while maintaining the integrity of applications and data.
In the case of stateful applications, managing data consistency across multiple instances of a service requires careful design. Azure offers tools like Azure Cosmos DB’s tunable consistency model to help manage consistency levels based on application needs. For containerized applications, Azure Kubernetes Service (AKS) can be configured with StatefulSets to manage state across multiple groups of pods, ensuring that services are resilient and available even in the event of an instance failure.
Disaster Recovery (DR) and Backup Strategies
A robust disaster recovery (DR) strategy is essential to complement high availability and ensure that platforms remain operational in the face of catastrophic events. For Azure-hosted workloads, Microsoft applies the shared responsibility model. In this model, Microsoft generally handles the resiliency of the baseline infrastructure and a range of platform services. However, many Azure services don't automatically replicate data or fall back from a failed region to another enabled region. For those services, platform engineers would be responsible for setting up a disaster recovery plan according to customer-defined recovery point objectives (RPOs) and recovery time objectives (RTOs). These objectives guide the backup and failover strategies, minimizing service disruption and data loss according to business priorities.
For virtual machine-based workloads, Azure Site Recovery (ASR) is a key service that automates the process of replicating workloads to secondary regions and enables rapid failover in the event of a failure. Most platform as a service (PaaS) offerings provide features and guidance to support DR and you can use service-specific features to support fast recovery as part of your own DR plan. For example, you can replicate most of the Deployment Environments resources in an alternate region to mitigate service loss if there is a regional failure, including dev centers, projects, catalogs, catalog items, dev center environment types, project environment types, and environments. Automated backup and replication services, such as Azure Backup and Azure Storage replication, allow businesses to implement a continuous data protection strategy across regions, ensuring that data is available for recovery even if an entire region goes down.
Regular testing and validation of disaster recovery plans are crucial for ensuring that they'll function as expected during a real-world event. Services like Azure Chaos Studio and Azure Site Recovery helps you measure, understand, and improve the resilience of your cloud applications and services by simulating outages and validate failover processes without impacting production environments. By integrating Azure’s native disaster recovery tools with a solid testing strategy, businesses can validate their disaster recovery plans.