Explore data ingestion pipelines
Now that you understand a little about the architecture of a large-scale data warehousing solution, and some of the distributed processing technologies that can be used to handle large volumes of data, it's time to explore how data is ingested into an analytical data store from one or more sources.
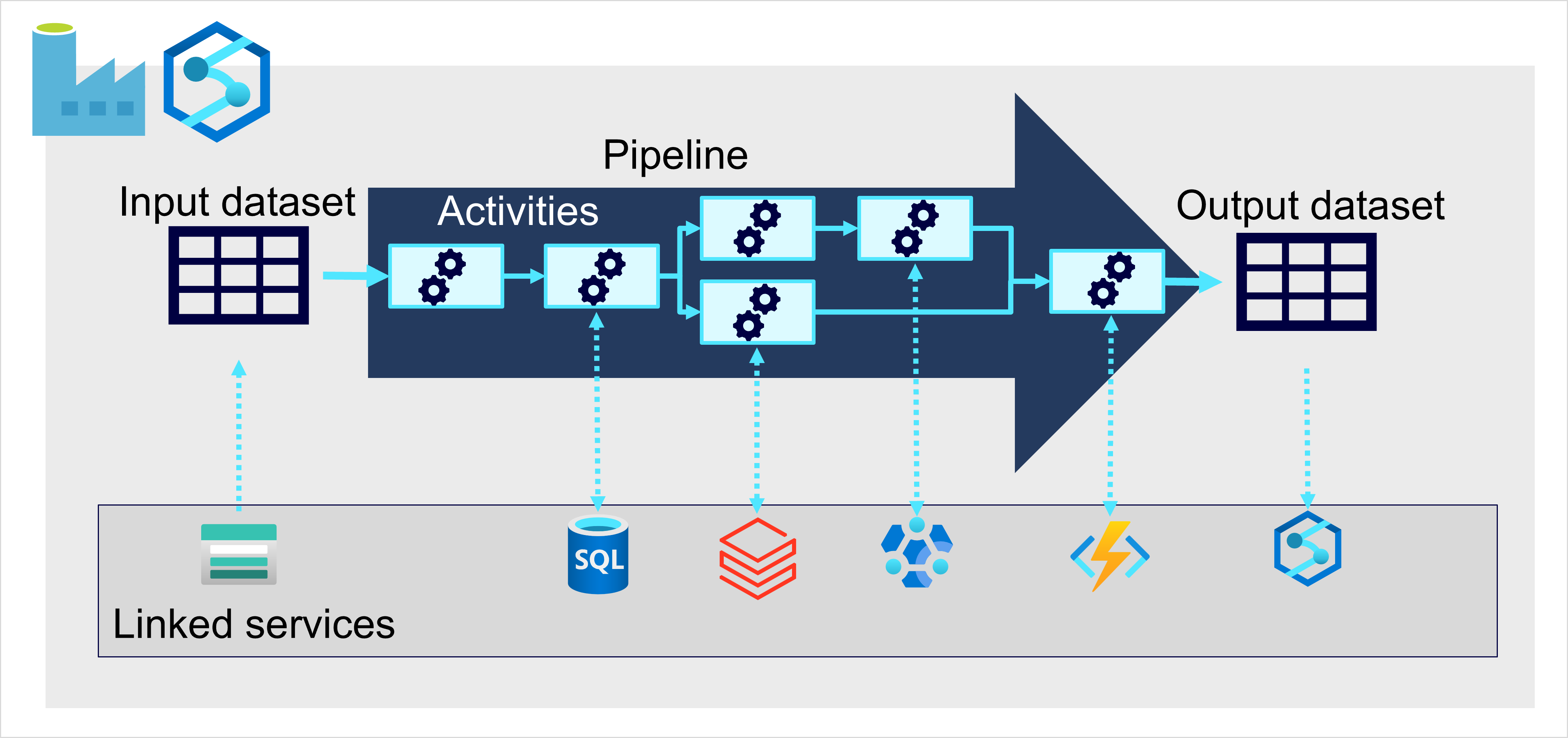
On Azure, large-scale data ingestion is best implemented by creating pipelines that orchestrate ETL processes. You can create and run pipelines using Azure Data Factory, or you can use the pipeline capability in Microsoft Fabric if you want to manage all of the components of your data warehousing solution in a unified workspace.
In either case, pipelines consist of one or more activities that operate on data. An input dataset provides the source data, and activities can be defined as a data flow that incrementally manipulates the data until an output dataset is produced. Pipelines use linked services to load and process data – enabling you to use the right technology for each step of the workflow. For example, you might use an Azure Blob Store linked service to ingest the input dataset, and then use services such as Azure SQL Database to run a stored procedure that looks up related data values, before running a data processing task on Azure Databricks, or apply custom logic using an Azure Function. Finally, you can save the output dataset in a linked service such as Microsoft Fabric. Pipelines can also include some built-in activities, which don’t require a linked service.