Understand the transformer architecture used for natural language processing (NLP)
The latest breakthrough in Natural Language Processing (NLP) is owed to the development of the Transformer architecture.
Transformers were introduced in the Attention is all you need paper by Vaswani, et al. from 2017. The Transformer architecture provides an alternative to the Recurrent Neural Networks (RNNS) to do NLP. Whereas RNNs are compute-intensive since they process words sequentially, Transformers don't process the words sequentially, but instead process each word independently in parallel by using attention.
The position of a word and the order of words in a sentence are important to understand the meaning of a text. To include this information, without having to process text sequentially, Transformers use positional encoding.
Understand positional encoding
Before Transformers, language models used word embeddings to encode text into vectors. In the Transformer architecture, positional encoding is used to encode text into vectors. Positional encoding is the sum of word embedding vectors and positional vectors. By doing so, the encoded text includes information about the meaning and position of a word in a sentence.
To encode the position of a word in a sentence, you could use a single number to represent the index value. For example:
| Token | Index value |
|---|---|
| The | 0 |
| work | 1 |
| of | 2 |
| William | 3 |
| Shakespeare | 4 |
| inspired | 5 |
| many | 6 |
| movies | 7 |
| ... | ... |
The longer a text or sequence, the larger the index values may become. Though using unique values for each position in a text is a simple approach, the values would hold no meaning, and the growing values may create instability during model training.
The solution proposed in the Attention is all you need paper uses sine and cosine functions, where pos is the position and i is the dimension:
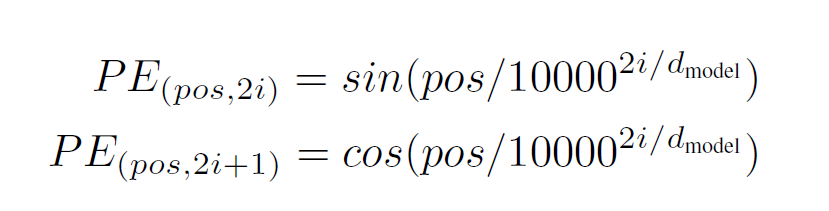
When you use these periodic functions together to create, you can create unique vectors for each position. As a result, the values are within a range and the index doesn't get larger when a larger text is encoded. Also, these positional vectors make it easier for the model to calculate and compare the positions of different words in a sentence against each other.
Understand multi-head attention
The most important technique used by Transformers to process text is the use of attention instead of recurrence.
Attention (also referred to as self-attention or intra-attention) is a mechanism used to map new information to learned information in order to understand what the new information entails.
Transformers use an attention function, where a new word is encoded (using positional encoding) and represented as a query. The output of an encoded word is a key with an associated value.
To illustrate the three variables that are used by the attention function: the query, keys, and values, let's explore a simplified example. Imagine encoding the sentence Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks. When encoding the query Vincent van Gogh, the output may be Vincent van Gogh as the key with painter as the associated value. The architecture stores keys and values in a table, which it can then use for future decoding:
| Keys | Values |
|---|---|
| Vincent Van Gogh | Painter |
| William Shakespeare | Playwright |
| Charles Dickens | Writer |
Whenever a new sentence is presented like Shakespeare's work has influenced many movies, mostly thanks to his work as a .... The model can complete the sentence by taking Shakespeare as the query and finding it in the table of keys and values. Shakespeare the query is closest to William Shakespeare the key, and thus the associated value playwright is presented as the output.
Using the scaled dot-product to compute the attention function
To calculate the attention function, the query, keys, and values are all encoded to vectors. The attention function then computes the scaled dot-product between the query vector and the keys vectors.
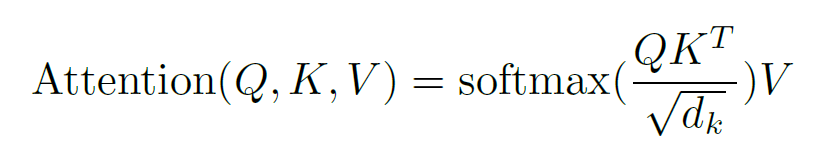
The dot-product calculates the angle between vectors representing tokens, with the product being larger when the vectors are more aligned.
The softmax function is used within the attention function, over the scaled dot-product of the vectors, to create a probability distribution with possible outcomes. In other words, the softmax function's output includes which keys are closest to the query. The key with the highest probability is then selected, and the associated value is the output of the attention function.
The Transformer architecture uses multi-head attention, which means tokens are processed by the attention function several times in parallel. By doing so, a word or sentence can be processed multiple times, in various ways, to extract different kinds of information from the sentence.
Explore the Transformer architecture
In the Attention is all you need paper, the proposed Transformer architecture is modeled as:
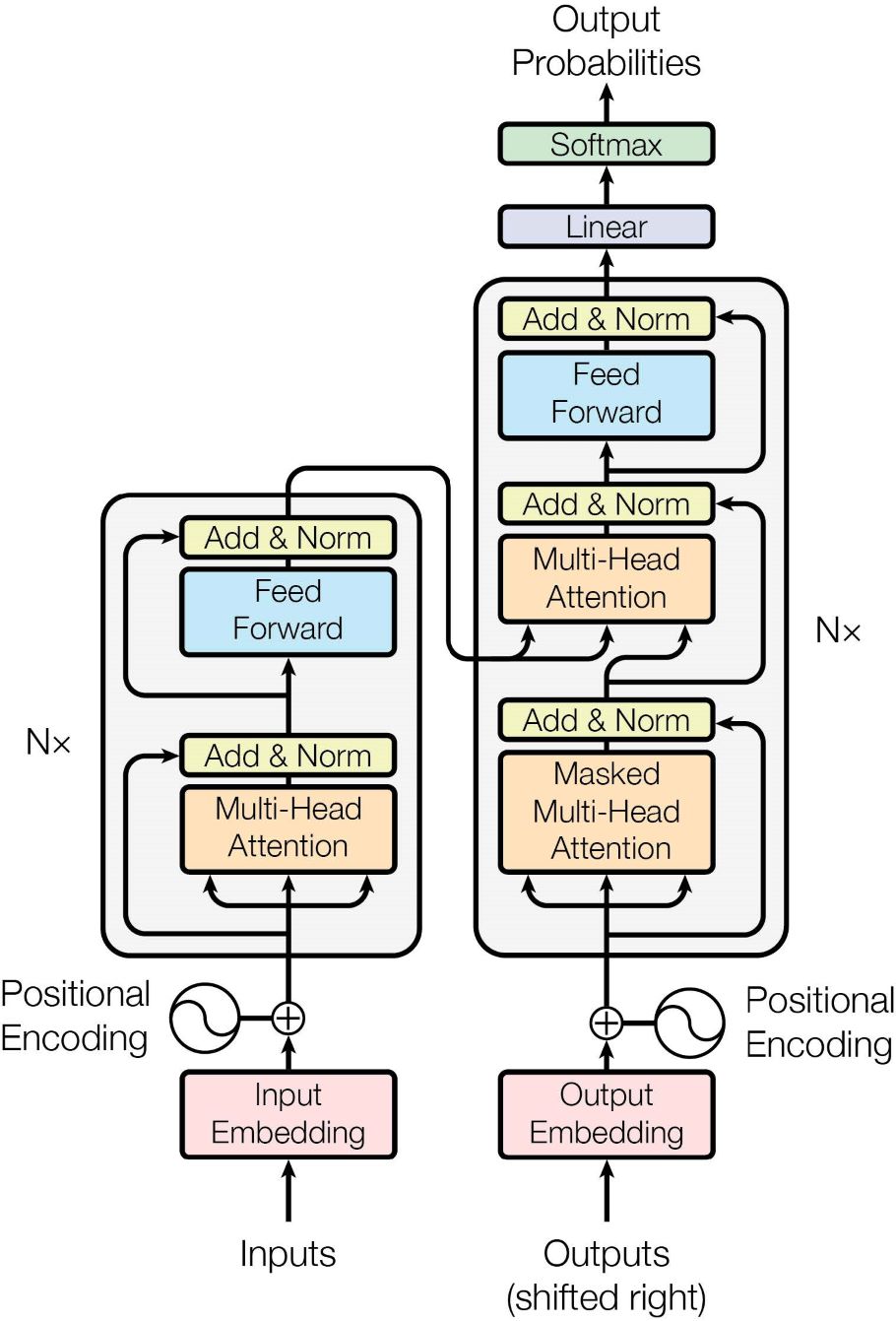
There are two main components in the original Transformer architecture:
- The encoder: Responsible for processing the input sequence and creating a representation that captures the context of each token.
- The decoder: Generates the output sequence by attending to the encoder's representation and predicting the next token in the sequence.
The most important innovations presented in the Transformer architecture were positional encoding and multi-head attention. A simplified representation of the architecture, focusing on these two components may look like:
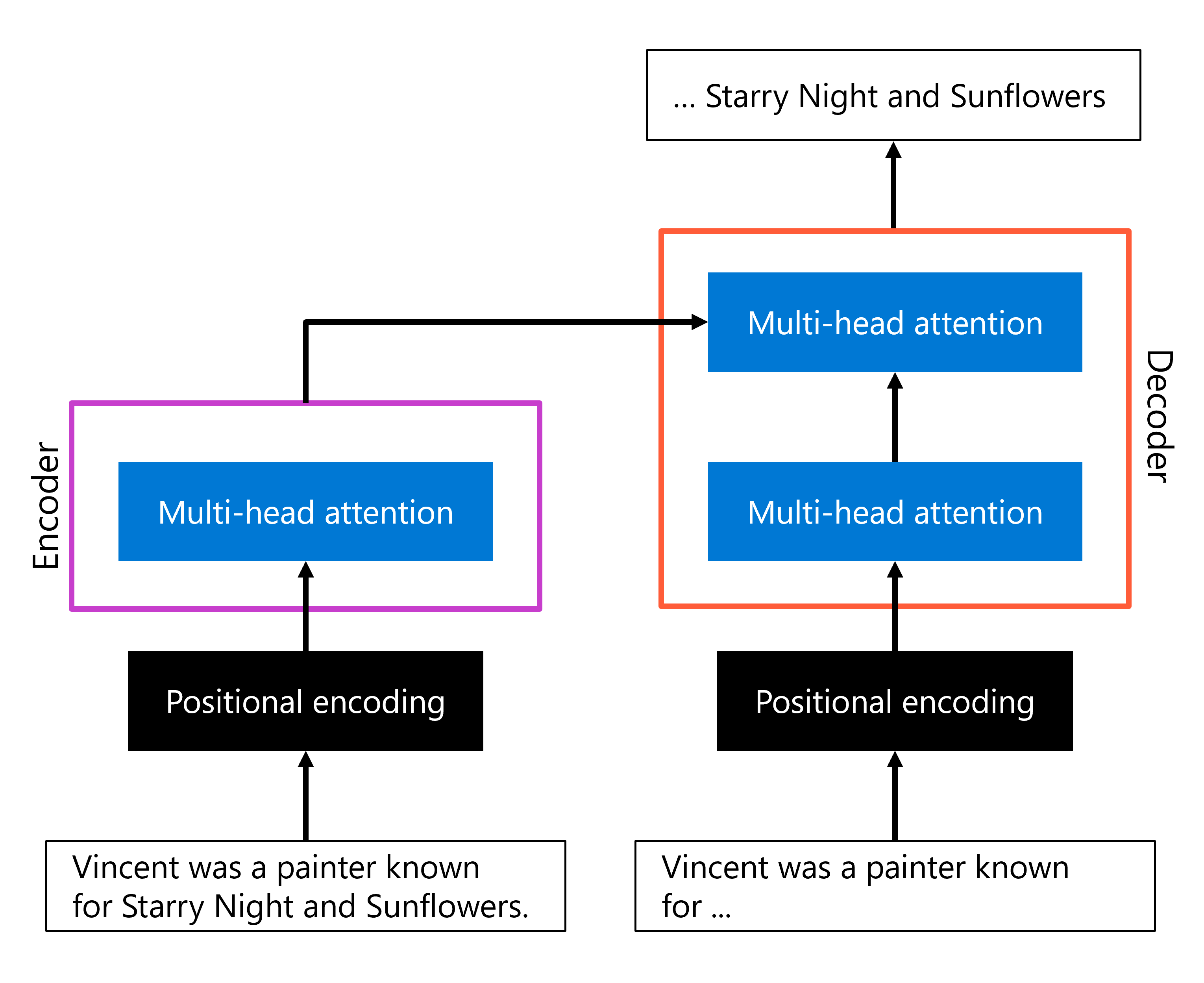
- In the encoder layer, an input sequence is encoded with positional encoding, after which multi-head attention is used to create a representation of the text.
- In the decoder layer, an (incomplete) output sequence is encoded in a similar way, by first using positional encoding and then multi-head attention. Then, the multi-head attention mechanism is used a second time within the decoder to combine the output of the encoder and the output of the encoded output sequence that was passed as input to the decoder part. As a result, the output can be generated.
The Transformer architecture introduced concepts that drastically improved a model's ability to understand and generate text. Different models have been trained using adaptations of the Transformer architecture to optimize for specific NLP tasks.