Introduction
Healthcare data solutions in Microsoft Fabric help you ingest Digital Imaging and Communications in Medicine (DICOM) data. By deploying the DICOM data ingestion solution into your Fabric workspace, you can ingest, store, and analyze imaging metadata across various modalities, such as X-rays, computed tomography (CT) scans, and magnetic resonance imaging (MRI) scans. By using this capability, you can store imaging and clinical data in Fast Health Interoperability Resources (FHIR) and Observational Medical Outcomes Partnership (OMOP) format. This data format helps clinicians and researchers interpret image findings in the correct clinical context. This interpretation leads to higher diagnostic accuracy, informative clinical decisions, and improved patient outcomes.
With the data in Microsoft Fabric, you can:
Share research datasets with role-based access control (RBAC).
De-identify text and imaging data for research and collaboration.
Use DICOM data to train and validate machine learning models.
Use DICOM data for conducting clinical studies, epidemiological analyses, and educational activities.
The healthcare data foundations solution provides a standardized data model that includes tables that contain the DICOM image metadata. DICOM data ingestion is optional, and you're not required to use it with other capabilities of the Fabric solution.
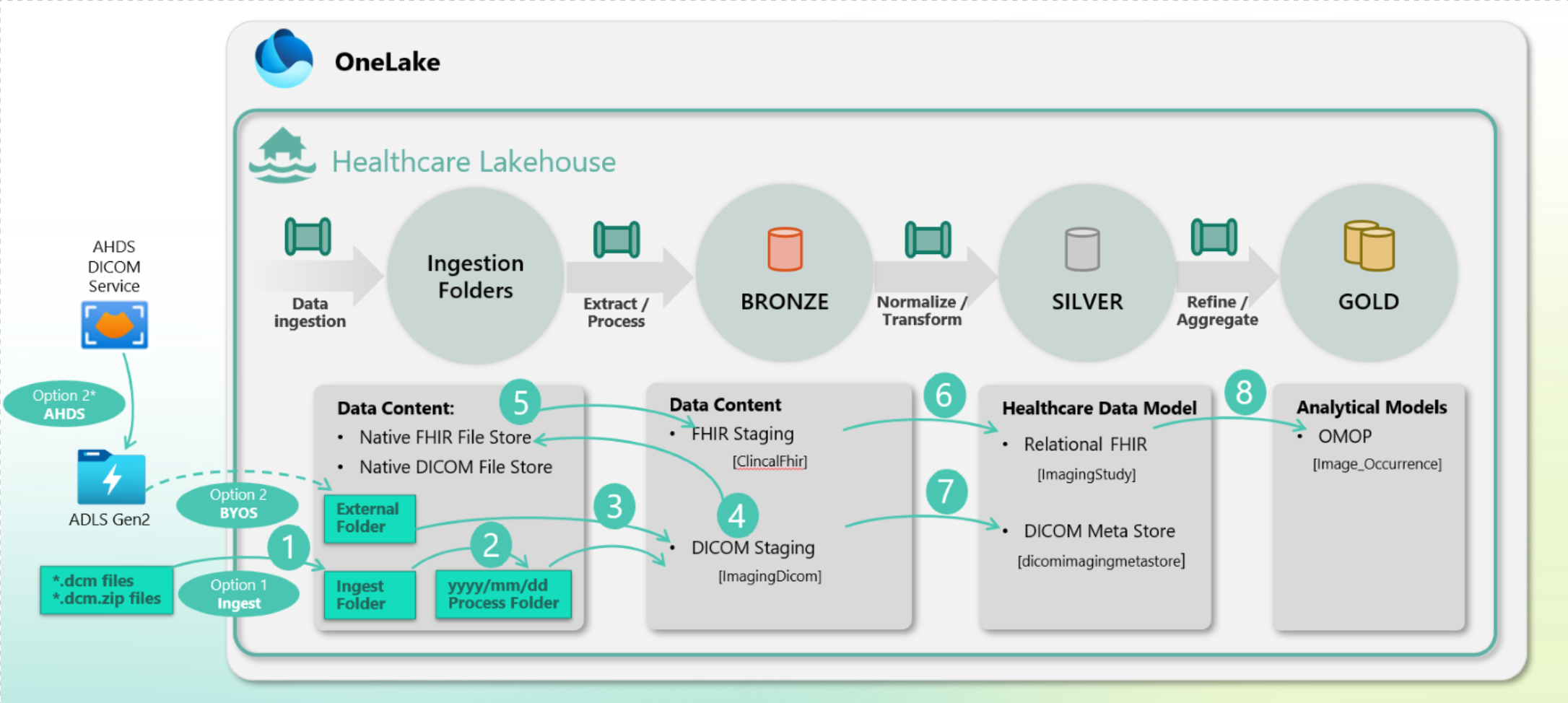
Three primary ways for ingesting your DICOM data into Microsoft Fabric for use with the healthcare data solutions are:
Integrate data directly from a Microsoft Azure Health Data Services DICOM service instance.
Ingest from your own storage.
Drop the files into the Ingest folder.
DICOM data transformation
Healthcare data solutions pipelines help with the transformation of the DICOM (imaging) data into tabular formats that can persist in the lake in FHIR (silver) and OMOP (gold) formats. These pipelines facilitate the conducting of exploratory analysis and running large-scale imaging analytics and radiomics. The data transformation process in the imaging ingestion pipeline consists of the following stages:
The pipeline ingests and persists the raw DICOM imaging files, which are present in the native DCM format, in the bronze lakehouse.
The system organizes the DCM files by using a best-practice lakehouse folder structure, with a timestamp appended to each filename. This approach ensures unique file names and facilitates robust data lineage.
The pipeline extracts all DICOM metadata (tags) from the imaging files and inserts them into the DICOM Staging bronze delta table to prepare the data for further transformation.
The system selects a portion of the most relevant DICOM metadata in the DICOM Staging delta table, converts it to FHIR ImagingStudy NDJSON files, and then stores it in the bronze lakehouse in the Native FHIR File Store.
The pipeline extracts the data from the NDJSON files and inserts them into the FHIR Staging bronze delta table to prepare the data for further transformation.
The system transforms the imaging data in the FHIR Staging delta table into a relational FHIR format and then stores it as the ImagingStudy delta table in the silver lakehouse.
Concurrently, the system transforms any DICOM metadata that isn't mapped to the silver ImagingStudy resource and then stores it in the DICOM Meta Store delta table in the silver layer, ensuring that no data is lost during the transition from bronze to silver.
The system transforms the data into the Image_Occurrence delta table in OMOP format (gold lakehouse).