Choose a partition key
Remember that data in JSON documents is stored in Azure Cosmos DB databases within containers that are in turn distributed across physical partitions and where the data is routed to the appropriate physical partition based on the value of a partition key.
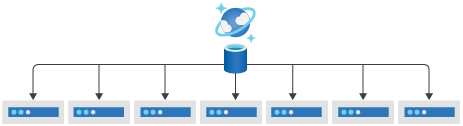
The partition key is a required document property that ensures documents with the same partition key value are routed to and stored within a specific physical partition. A physical partition supports a fixed maximum amount of storage and throughput (RU/s). Azure Cosmos DB automatically distributes the logical partitions across the available physical partitions, again using the partition key value to do so in a predictable way.
In this unit, you'll learn more about logical partitions and how to avoid hot partitions. This information will help us choose the appropriate partition key for the customer data in our scenario.
In Azure Cosmos DB, you increase storage and throughput by adding more physical partitions to access and store data. The maximum storage size of a physical partition is 50 GB, and the maximum throughput is 10,000 RU/s.
Logical partitions in Azure Cosmos DB
A logical partition is an abstraction above the underlying physical partitions. Multiple logical partitions can be stored within a single physical partition. A container can have an unlimited number of logical partitions. Individual logical partitions are moved to new physical partitions as they grow in size to ensure optimum storage utilization and growth. Moving logical partitions as a unit ensures that all documents within it reside on the same physical partition. The maximum size for a logical partition is 20 GB. Using a partition key with high cardinality allows you to avoid this 20-GB limit by spreading your data across a larger number of logical partitions. You can also use hierarchical partition keys which organize partition key values in a hierarchy to avoid this limit. These are covered in another learning path.
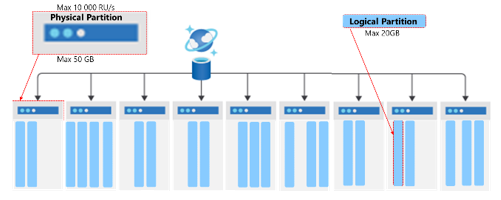
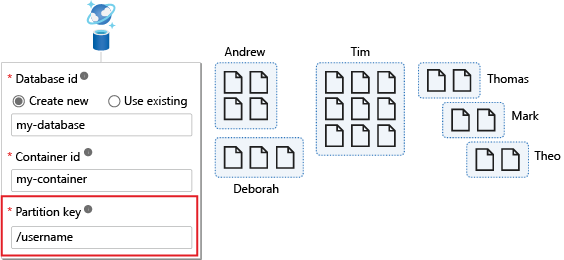
A partition key provides a way to route data for a logical partition. It's a property that exists within every document in your container that routes your data. A container is another abstraction for all data stored with the same partition key. The partition key is defined when you create a container.
In the following example, the container has a partition key of /username.
Avoid hot partitions
When you're modeling data for Azure Cosmos DB, it's critically important that the partition key that you choose results in an even distribution of data and requests across both logical and by extension, the physical partitions in your container. This is especially true when containers grow larger and have an increasing number of physical partitions.
If you don't test the design of your database under load during development, a poor choice for partition key might not be revealed until the application is in production and significant data has already been written.
When data is not partitioned correctly, it can result in hot partitions. Hot partitions prevent your application workload from scaling, and they can occur on both storage and throughput.
Storage hot partitions
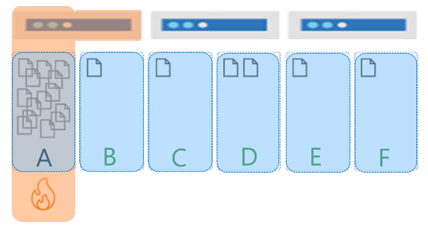
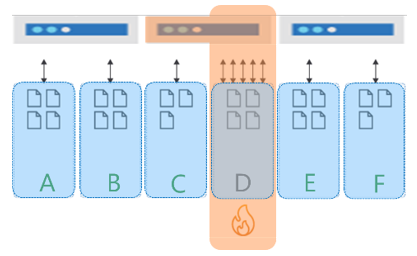
A hot partition on storage occurs when you have a partition key that results in highly asymmetric storage patterns. As an example, consider a multitenant application that uses TenantId as its partition key with six tenants: A to F. Tenants B,C,E and F are very small, Tenant D has a little more data. However Tenant A is massive and quickly hits the 20-GB limit for its partition. In this scenario, we need to select a different partition key that will spread the storage across more logical partitions.
Throughput hot partitions
Throughput can suffer from hot partitions when most or all of the requests go to the same logical partition.
It's important to understand the access patterns for your application to ensure that requests are spread as evenly as possible across partition key values. When throughput is provisioned for a container in Azure Cosmos DB, it's allocated evenly across all the physical partitions within a container.
As an example, if you have a container with 30,000 RU/s, this workload is spread across the three physical partitions for the same six tenants mentioned earlier. So each physical partition gets 10,000 RU/s. If tenant D consumes all of its 10,000 RU/s, it will be rate limited because it can't consume the throughput allocated to the other partitions. This results in poor performance for tenant C and D, and leaving unused compute capacity in the other physical partitions and remaining tenants. Ultimately, this partition key results in a database design where the application workload can't scale.
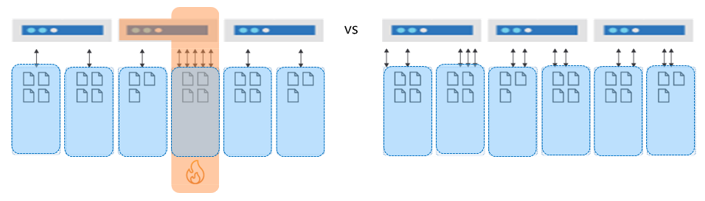
When data and requests are spread evenly, the database can grow in a way that fully utilizes both the storage and throughput. The result will be the best possible performance and highest efficiency. In short, the database design will scale.
Consider reads versus writes
When you're choosing a partition key, you also need to consider whether the data is read heavy or write heavy. You should seek to distribute write-heavy requests with a partition key that has high cardinality.
For read-heavy workloads, you should ensure that queries are processed by one or a limited number of partitions by including an WHERE clause with an equality filter on the partition key, or an IN operator on a subset of partition key values in your queries.
In scenarios where the application workload is both write heavy and read heavy, there is a solution. We'll explore that in the next module.
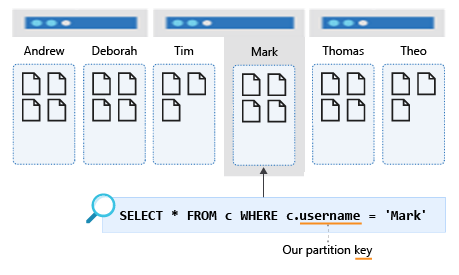
The following illustration shows a container that's partitioned by username. This query will hit only a single logical partition, so its performance will always be good.
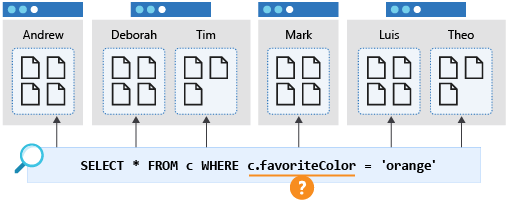
A query that filters on a different property, such as favoriteColor, would "fan out" to all partitions in the container. This is also known as a cross-partition query. Such a query will perform as expected when the container is small and occupies only a single partition. However, as the container grows and there are increasing number of physical partitions, this query will become slower and more expensive because it will need to check every partition to get the results whether the physical partition contains data related to the query or not.
Choose a partition key for customers
Now that you understand partitioning in Azure Cosmos DB, we can decide on a partition key for our customer data. As we covered earlier, we perform three operations on customers: create a customer, update a customer, and retrieve a customer. In this case, we'll retrieve the customer by their id. Because that operation will be called the most, it makes sense to make the customer's ID the partition key for the container.

You might worry here that making the ID the partition key means that we'll have as many logical partitions as there are customers, with each logical partition containing only a single document. Millions of customers would result in millions of logical partitions.
But this is perfectly fine! Logical partitions are a virtual concept, and there's no limit to how many logical partitions you can have. Azure Cosmos DB will collocate multiple logical partitions on the same physical partition. As logical partitions grow in number or in size, Cosmos DB will move them to new physical partitions when needed.