Introduction to Continuous Monitoring
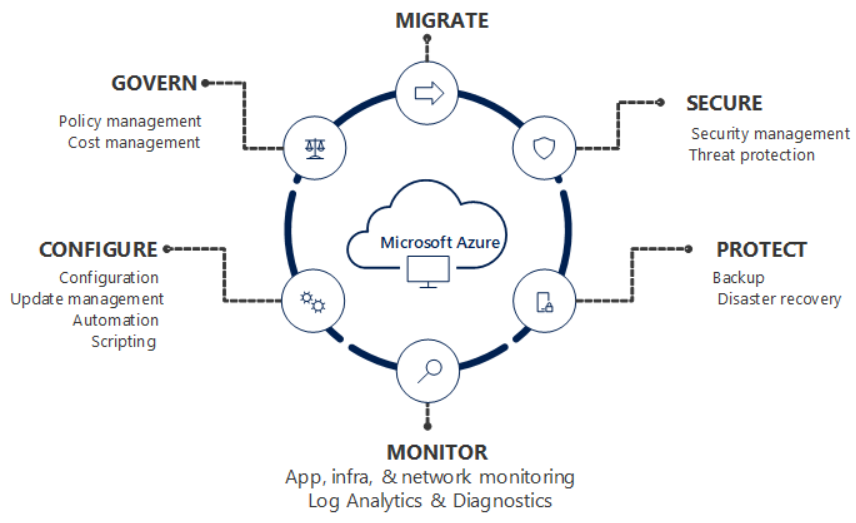
What is continuous monitoring?
Continuous monitoring refers to the process and technology required to incorporate monitoring across each phase of DevOps and IT operations lifecycles. It represents a fundamental shift from reactive to proactive operational practices, enabling teams to identify and address issues before they impact users.
In modern software development, continuous monitoring helps to ensure your application's health, performance, reliability, and infrastructure integrity as it moves from development to production. Rather than discovering problems after deployment, continuous monitoring provides real-time visibility into system behavior at every stage.
The continuous monitoring lifecycle
Continuous monitoring builds on the concepts of Continuous Integration (CI) and Continuous Deployment (CD), which help you develop and deliver software faster and more reliably to provide continuous value to your users. The monitoring lifecycle includes:
Development phase:
- Local testing with instrumentation
- Performance profiling during builds
- Automated test telemetry collection
Testing phase:
- Load testing with performance metrics
- Integration test monitoring
- Synthetic transaction validation
Staging phase:
- Pre-production health checks
- Canary deployment monitoring
- Configuration validation
Production phase:
- Real-time application performance monitoring
- Infrastructure health tracking
- User experience analytics
- Incident detection and alerting
Azure Monitor: The foundation for continuous monitoring
Azure Monitor is the unified monitoring solution in Azure that provides full-stack observability across applications and infrastructure in the cloud and on-premises. It serves as the central nervous system for your monitoring strategy, collecting, analyzing, and acting on telemetry from your entire environment.
Azure Monitor integrations across the development lifecycle:
Development tools:
- Works seamlessly with Visual Studio and Visual Studio Code during development and testing
- Provides debugging insights with Application Insights
- Enables local performance profiling
- Supports developer-friendly instrumentation APIs
DevOps platforms:
- Integrates with Azure DevOps for release management and work item management during deployment and operations
- Supports automated quality gates in release pipelines
- Provides deployment health tracking
- Enables rollback decisions based on telemetry
IT operations tools:
- Integrates with ITSM tools to track issues and incidents within your existing IT processes
- Connects to SIEM tools for security monitoring
- Supports webhook integrations for custom workflows
- Enables automation through Azure Automation and Logic Apps
What you'll learn
This unit describes specific steps for using Azure Monitor to enable continuous monitoring throughout your workflows. You'll explore:
- Application monitoring strategies for gaining visibility across all applications
- Infrastructure monitoring approaches for tracking the health of underlying resources
- Resource organization techniques for managing complex application architectures
- Deployment quality practices for ensuring continuous delivery excellence
- Alerting strategies for proactive issue detection and resolution
- Visualization approaches for dashboards and reports
- Optimization methodologies for continuous improvement
Each section includes links to detailed documentation for implementing specific features in your environment.
Enable monitoring for all your applications
To gain observability across your entire environment, you need to enable monitoring on all your web applications and services. Complete application coverage allows you to visualize end-to-end transactions and connections across all components, making it easier to identify bottlenecks, trace errors, and understand user journeys.
Why comprehensive application monitoring matters
Without monitoring:
- Issues are discovered by users reporting problems
- Root cause analysis relies on logs and guesswork
- Performance degradation goes unnoticed until critical
- Business impact of technical issues remains unknown
With monitoring:
- Issues are detected before user impact
- Telemetry data provides clear diagnostic paths
- Performance trends inform capacity planning
- Business metrics tie technical health to outcomes
Application monitoring approaches
1. Rapid deployment with Azure DevOps Projects
Azure DevOps Projects provides a simplified experience for getting started with CI/CD and monitoring:
- Bring your code: Connect your existing code and Git repository
- Use samples: Choose from sample applications to create a complete pipeline
- Automatic setup: CI/CD pipeline to Azure with monitoring pre-configured
- Monitoring included: Application Insights integrated from day one
This approach is ideal for teams wanting to quickly establish best practices without extensive configuration.
2. Pipeline integration with continuous monitoring
Continuous monitoring in your DevOps release pipeline allows you to gate or roll back your deployment based on monitoring data:
- Quality gates: Define thresholds for performance and reliability metrics
- Automated decisions: Allow or block deployments based on telemetry
- Progressive exposure: Use monitoring data to control rollout percentage
- Automated rollback: Revert deployments that exceed error thresholds
Example scenario: A deployment is automatically rolled back when error rate exceeds 1% or response time increases by 50% compared to previous version.
3. Runtime instrumentation with Status Monitor
Status Monitor allows you to instrument a live .NET app on Windows with Azure Application Insights without modifying or redeploying your code:
- Zero code changes: No application modifications required
- No redeployment: Enable monitoring on running applications
- Immediate insights: Start collecting telemetry instantly
- Production safe: Non-invasive instrumentation approach
This approach is valuable for monitoring legacy applications or production systems where code changes are risky or time-consuming.
4. SDK-based comprehensive monitoring
If you have access to the code for your application, enable complete monitoring with Application Insights by installing the Azure Monitor Application Insights SDK:
Supported languages and platforms:
- .NET: ASP.NET, ASP.NET Core, console apps
- Java: Spring Boot, Jakarta EE, servlets
- Node.js: Express, Koa, HTTP servers
- Other languages: Python, PHP, Ruby, Go
SDK capabilities:
- Custom events: Track business-specific activities (purchase completed, user registered)
- Custom metrics: Measure application-specific values (items in cart, processing queue length)
- Page views: Monitor user navigation and engagement patterns
- Dependencies: Automatically track calls to databases, APIs, and external services
- Exceptions: Capture and analyze application errors with full stack traces
- Performance counters: Monitor CPU, memory, and resource utilization
Example custom telemetry:
// Track a custom business event
telemetryClient.TrackEvent("OrderPlaced",
properties: new Dictionary<string, string> { {"Category", "Electronics"} },
metrics: new Dictionary<string, double> { {"OrderValue", 599.99} });
Enable monitoring for your entire infrastructure
Applications are only as reliable as their underlying infrastructure. A perfectly coded application will fail if the hosting infrastructure experiences CPU exhaustion, memory pressure, network connectivity issues, or disk space limitations. Infrastructure monitoring is not optional—it's the foundation for application reliability.
Why infrastructure monitoring is critical
Monitoring enabled across your entire infrastructure will help you achieve full observability and make discovering a potential root cause easier when something fails:
Detect infrastructure issues before application impact:
- Capacity planning: Identify resource trends before running out of capacity
- Performance correlation: Link application slowness to infrastructure constraints
- Proactive maintenance: Address resource exhaustion before outages occur
- Cost optimization: Identify underutilized resources for rightsizing
Root cause analysis capabilities:
- Unified view: See infrastructure and application metrics together
- Historical analysis: Compare current state against baseline behavior
- Dependency mapping: Understand how infrastructure impacts applications
- Automated diagnostics: Leverage Azure's AI to identify likely causes
Azure infrastructure monitoring capabilities
Azure Monitor helps you track the health and performance of your entire hybrid infrastructure, including resources such as VMs, containers, storage, and network across cloud and on-premises environments.
1. Automatic baseline monitoring
You automatically get platform metrics, activity logs, and diagnostics logs from most of your Azure resources with no configuration required:
Platform metrics (automatic):
- CPU percentage and utilization
- Memory available and usage
- Disk read/write operations and throughput
- Network in/out bandwidth
- Resource-specific metrics (requests, connections, etc.)
Activity logs (automatic):
- Resource creation, modification, deletion
- Configuration changes
- Scaling operations
- Access control changes
- Service health events
Diagnostics logs (requires enablement):
- Detailed operation logs
- Performance data at granular level
- Security audit trails
- Custom application logs
2. Enhanced VM monitoring
Enable deeper monitoring for VMs with Azure Monitor for VMs:
VM insights capabilities:
- Performance monitoring: CPU, memory, disk, network at process level
- Dependency mapping: Automatically discover and map application dependencies
- Process monitoring: Track running processes and their resource consumption
- Connection tracking: Monitor inbound and outbound network connections
- Trend analysis: Identify performance patterns and anomalies
- Health model: Pre-built health criteria for common VM scenarios
Use cases:
- Identify which processes consume the most CPU or memory
- Map application dependencies across multiple VMs
- Detect failed network connections or slow database queries
- Plan for capacity based on historical resource trends
3. Container and Kubernetes monitoring
Enable deeper monitoring for AKS clusters with Azure Monitor for containers:
Container insights capabilities:
- Cluster performance: Node and pod CPU/memory metrics
- Container logs: Centralized log collection from all containers
- Live data streaming: Real-time view of logs and events
- Resource utilization: Track requests, limits, and actual usage
- Cluster health: Monitor control plane and node status
- Alerting: Pre-configured alerts for common issues
Monitoring scope:
- AKS (Azure Kubernetes Service)
- Azure Container Instances
- Self-managed Kubernetes clusters
- Azure Arc-enabled Kubernetes
4. Specialized monitoring solutions
Add monitoring solutions for different applications and services in your environment:
Available solutions include:
- SQL Analytics: Monitor SQL Server, Azure SQL Database, and Managed Instances
- Key Vault Analytics: Track access patterns and performance of key vaults
- Network Performance Monitor: Monitor network connectivity and performance
- Service Fabric Analytics: Monitor Service Fabric cluster health
- Storage Analytics: Track storage account performance and capacity
- Backup and Recovery: Monitor backup operations and compliance
Each solution provides pre-built dashboards, queries, and alerts tailored to specific resource types.
Infrastructure as Code for monitoring
Infrastructure as code manages infrastructure in a descriptive model, using the same versioning as DevOps teams use for source code. This approach adds reliability and scalability to your environment and allows you to apply similar processes used to manage applications to your infrastructure and monitoring configurations.
Benefits of IaC for monitoring:
- Consistency: Deploy identical monitoring across environments
- Version control: Track changes to monitoring configurations
- Automation: Deploy monitoring alongside infrastructure
- Repeatability: Create standardized monitoring patterns
- Documentation: Monitoring configuration serves as documentation
1. Resource Manager templates for monitoring at scale
Use Resource Manager templates to enable monitoring and configure alerts over a large set of resources:
Template capabilities:
- Deploy diagnostic settings to Log Analytics workspaces
- Configure metric alerts with dynamic thresholds
- Enable Application Insights instrumentation
- Set up action groups for notifications
- Deploy workbooks and dashboards
- Configure autoscale rules
Example scenario: Deploy a template that automatically configures Application Insights, enables diagnostic logs, creates standard alerts (high CPU, memory pressure, failed requests), and sets up an action group for your operations team—all resources deployed consistently across dev, test, and production.
2. Azure Policy for monitoring governance
Use Azure Policy to enforce rules over your resources, ensuring those resources comply with your corporate standards and service level agreements:
Policy enforcement examples:
- Required diagnostics: Automatically enable diagnostic settings for all resources
- Tagging requirements: Ensure resources have required tags for cost allocation
- Monitoring agent deployment: Automatically deploy monitoring agents to VMs
- Log retention: Enforce minimum log retention periods
- Regional restrictions: Ensure resources are deployed in compliant regions
- Required resource configurations: Enforce specific SKUs or settings
Policy effects:
- Audit: Report on non-compliant resources
- Deny: Prevent non-compliant resource creation
- Deploy if not exists: Automatically configure monitoring for resources
- Modify: Change resource properties to comply with standards
Example policy: Automatically deploy the Log Analytics agent to all VMs and configure them to send logs to a central workspace.
Combine resources in Azure Resource Groups
Today, a typical application on Azure includes multiple resources working together as a distributed system. Understanding these resources as a cohesive unit rather than individual components is essential for effective monitoring.
Modern application architecture complexity
Typical e-commerce application components:
- Compute: VMs for legacy services, App Services for web front-end, Azure Functions for event processing
- Containers: AKS clusters hosting microservices, Azure Container Instances for batch jobs
- Data stores: Azure SQL Database for transactions, Cosmos DB for product catalog, Redis Cache for sessions
- Messaging: Event Hubs for event streaming, Service Bus for reliable messaging, Event Grid for event routing
- Storage: Blob Storage for images and documents, Queue Storage for background tasks
- Security: Key Vault for secrets and certificates
- Networking: Application Gateway for load balancing, Front Door for global distribution
These applications frequently use complex dependencies where failures in one component cascade to others. For example, a storage account throttling issue could cause the web application to time out, triggering a spike in retry attempts that overwhelms the message queue.
Resource group monitoring strategy
Combine resources in Azure Resource Groups to get complete visibility of all the resources that make up your different applications. Azure Monitor for Resource Groups provides a simple way to keep track of the health and performance of your entire full-stack application.
Benefits of resource group-based monitoring:
1. Unified visibility:
- See health status of all related resources in a single view
- Identify which component is causing application-level issues
- Understand resource interdependencies
- Track aggregate metrics across the application
2. Simplified investigation:
- Drill down into specific components for detailed analysis
- Navigate from application symptoms to infrastructure causes
- View correlated metrics across related resources
- Access logs and metrics within context of the application
3. Operational efficiency:
- Monitor applications as logical units, not individual resources
- Reduce time to identify failing components
- Understand blast radius of resource failures
- Coordinate monitoring with deployment boundaries
4. Cost visibility:
- Track total cost of an application
- Identify expensive resources within the context of their contribution
- Monitor resource utilization patterns
- Support chargeback or showback scenarios
Best practices for resource group organization:
- Group by application lifecycle: Resources deployed and retired together
- Align with deployment boundaries: Match resource groups to deployment units
- Consider RBAC requirements: Group resources with similar access needs
- Respect resource limits: Stay within subscription and resource group limits
- Enable tagging: Use tags for additional categorization beyond resource groups
Ensure quality through continuous deployment
Continuous Integration / Continuous Deployment (CI/CD) allows you to automatically integrate and deploy code changes to your application based on automated testing results. CI/CD streamlines the deployment process and ensures the quality of any changes before they move into production, but automated tests alone cannot catch all issues—monitoring data provides crucial validation.
Monitoring-driven deployment quality
Traditional deployment validation:
- Unit tests verify code behavior in isolation
- Integration tests confirm components work together
- Automated UI tests validate user workflows
Monitoring-enhanced validation:
- Pre-deployment checks: Validate target environment health before deploying
- Post-deployment verification: Confirm deployment didn't degrade performance
- Progressive rollout: Use monitoring data to gradually increase exposure
- Automated rollback: Revert deployments that violate quality thresholds
Azure Pipelines for continuous deployment
Use Azure Pipelines to implement Continuous Deployment and automate your entire process from code commit to production based on your CI/CD tests:
Pipeline stages with monitoring integration:
1. Build stage:
- Compile code and run unit tests
- Scan for security vulnerabilities
- Create deployment artifacts
- Tag artifacts with build metadata for traceability
2. Deploy to development:
- Deploy to dev environment
- Run integration tests
- Collect Application Insights telemetry
- Validate baseline performance metrics
3. Deploy to staging:
- Deploy to staging environment with production-like configuration
- Run automated UI and API tests
- Execute load tests with Azure Load Testing
- Quality gate: Compare performance against production baseline
4. Deploy to production (with gates):
- Pre-deployment gate: Verify no active incidents in production
- Deploy to subset of production (canary deployment)
- Post-deployment gate: Monitor telemetry for 15-30 minutes
- Automated approval or rollback based on monitoring data
- Gradual rollout to remaining production instances
Quality gates for monitoring-driven deployment
Use Quality Gates to integrate monitoring into your pre-deployment or post-deployment process. Quality gates ensure that you meet the key health/performance metrics (KPIs) as your applications move from dev to production:
Quality gate metrics:
Performance metrics:
- Response time: Average, 95th percentile, 99th percentile must stay within thresholds
- Throughput: Requests per second compared to baseline
- Resource utilization: CPU and memory usage within acceptable ranges
Reliability metrics:
- Error rate: Failed requests below threshold (e.g., <1%)
- Exception rate: Unhandled exceptions remain minimal
- Dependency failures: External service calls succeed at expected rate
Availability metrics:
- Health probe success rate: Endpoint health checks passing
- Synthetic test results: Multi-step user scenarios succeeding
Example quality gate configuration:
Pre-deployment gate:
- No active P0/P1 incidents in production
- Production error rate < 0.5% over last 15 minutes
Post-deployment gate (evaluate for 20 minutes):
- Response time 95th percentile < 2 seconds
- Error rate < 1%
- No increase in exceptions compared to previous version
- At least 100 requests processed (minimum sample size)
If gates fail: Automatic rollback to previous version
Handling environment differences:
Any differences in the infrastructure environment or scale between environments shouldn't negatively impact your KPIs. Strategies include:
- Baseline comparison: Compare against the same environment's baseline, not other environments
- Proportional thresholds: Scale thresholds based on environment size (10 errors in dev ≠ 10 errors in production)
- Environment-specific gates: Different thresholds for dev (lenient), staging (moderate), production (strict)
Monitoring instance separation
Maintain separate monitoring instances between your different deployment environments, such as Dev, Test, Canary, and Prod:
Why separate instances:
- Data isolation: Development experiments don't pollute production analytics
- Access control: Limit production telemetry access to authorized personnel
- Cost visibility: Track monitoring costs per environment
- Independent configuration: Different sampling rates, retention policies, alert thresholds
- Performance impact: Development traffic doesn't skew production metrics
When to correlate across environments:
Sometimes you need to compare behavior across environments to diagnose issues:
Cross-environment analysis approaches:
- Use multi-resource charts in Metrics Explorer to compare metrics side-by-side
- Create cross-resource queries in Log Analytics to query multiple Application Insights instances
- Use correlation IDs that span environments for end-to-end transaction tracing
- Build dashboards that show metrics from multiple environments for comparison
Example cross-environment query:
union
workspace("Dev-AppInsights").requests,
workspace("Staging-AppInsights").requests,
workspace("Prod-AppInsights").requests
| where timestamp > ago(24h)
| summarize RequestCount=count(), AvgDuration=avg(duration) by Environment=tostring(split(_ResourceId, "/")[8])
| order by Environment
This query compares request volume and average duration across all three environments in a single result set.
Create actionable alerts with actions
A critical monitoring aspect is proactively notifying administrators of current and predicted issues before they impact users. However, alert fatigue—where teams receive so many alerts that they ignore them—is a common problem. The solution is creating actionable alerts that drive specific responses.
Characteristics of actionable alerts
Actionable alerts must:
- Represent actual critical conditions: Each alert indicates a real problem requiring attention
- Be specific: Clear indication of what's wrong and where
- Include context: Sufficient information to begin investigation
- Suggest actions: Guidance on what to do or automate the response
- Avoid false positives: High signal-to-noise ratio maintains trust
Alert anti-patterns to avoid:
- Alerting on metrics that don't indicate user impact
- Setting static thresholds that don't account for normal variation
- Creating alerts without defining who responds and how
- Generating duplicate alerts for the same underlying issue
- Alerting on informational events that don't require action
Creating alerts in Azure Monitor
Create alerts in Azure Monitor based on logs and metrics to identify predictable failure states:
Alert rule components:
1. Target resource: What are you monitoring?
- Specific Azure resource (VM, App Service)
- Resource group or subscription
- Application Insights instance
- Log Analytics workspace
2. Condition: When should the alert fire?
- Metric exceeds threshold
- Log query returns results
- Activity log event occurs
- Resource health changes
3. Action group: What happens when the alert fires?
- Notifications (email, SMS, push, voice)
- Automated responses (webhook, runbook, Logic App)
- ITSM ticket creation
4. Alert details: How is the alert described?
- Severity (Critical, Error, Warning, Informational)
- Description with troubleshooting guidance
- Custom properties for routing and correlation
Dynamic thresholds for intelligent alerting
Use dynamic thresholds to automatically calculate baselines on metric data rather than defining static thresholds:
Static threshold problems:
- Don't account for daily or weekly patterns (traffic higher during business hours)
- Require manual adjustment as application scales
- May be too sensitive (false positives) or too lenient (missed issues)
- Need different values for different resources
Dynamic threshold advantages:
- Machine learning: Automatically learns normal behavior patterns
- Adapts to growth: Thresholds adjust as application scales
- Seasonal awareness: Understands daily, weekly, and monthly patterns
- Anomaly detection: Identifies unusual deviations from expected behavior
- Per-resource learning: Each resource has individually tuned thresholds
Example scenario: An e-commerce site has 5,000 requests/minute during business hours and 500 requests/minute overnight. A static threshold of 1,000 requests/minute would either miss business-hour spikes or alert constantly during off-hours. Dynamic thresholds learn this pattern and alert on anomalies at any time of day.
Notification actions
Define actions for alerts to use the most effective means of notifying your administrators. Available actions for notification include:
Immediate notification methods:
- Email: Detailed alert information with links to Azure Portal
- SMS: Brief alert for critical issues requiring immediate attention
- Push notifications: Azure mobile app notifications
- Voice calls: Automated voice calls for critical P0 incidents
Notification best practices:
- Match severity to method: Critical alerts → SMS/voice, Warning → email
- Avoid alert fatigue: Limit SMS/voice to true emergencies
- Include context: Email body should contain investigation starting points
- Time-based routing: Route alerts differently during business hours vs. on-call shifts
- Escalation policies: Start with primary on-call, escalate if not acknowledged
Integration actions
Use more advanced actions to connect to your ITSM tool or other alert management systems through webhooks:
ITSM integration capabilities:
- ServiceNow: Automatically create incidents with alert details
- BMC Remedy: Create work items with full alert context
- Provance: Track alerts in ITSM workflow
- Cherwell: Generate tickets linked to Azure resources
Webhook integration scenarios:
- Post alerts to Microsoft Teams or Slack channels
- Create tickets in third-party systems (Jira, GitHub Issues)
- Trigger PagerDuty or Opsgenie escalation policies
- Update status pages (StatusPage.io)
- Invoke custom APIs for specialized handling
Automated remediation
Remediate situations identified in alerts with Azure Automation runbooks or Logic Apps that can be launched from an alert using webhooks:
Automation runbook examples:
- High disk usage alert: Automatically clean up temporary files or expand disk size
- Application pool hang: Restart the application pool without manual intervention
- Database connection pool exhaustion: Scale up the database tier temporarily
- Certificate expiration: Renew certificates and update configurations
Logic App examples:
- Security alert: Disable compromised accounts and notify security team
- Performance degradation: Collect diagnostics, create support ticket with logs attached
- Resource threshold: Approve pre-authorized scaling operation automatically
- Backup failure: Retry backup job and notify if second attempt fails
Example automated response workflow:
- Alert fires: CPU > 90% for 10 minutes
- Webhook triggers Azure Automation runbook
- Runbook collects diagnostics (top processes, memory usage)
- Runbook attempts to restart non-critical services
- If CPU remains high, runbook scales up the VM tier
- Notification sent to team with actions taken
Proactive scaling with autoscaling
Use autoscaling to dynamically increase and decrease your compute resources based on collected metrics, preventing issues before alerts fire:
Autoscaling strategies:
Metric-based autoscaling:
- Scale out when CPU > 70% for 5 minutes
- Scale in when CPU < 30% for 10 minutes
- Scale based on request queue length
- Scale based on custom Application Insights metrics
Schedule-based autoscaling:
- Scale up during known peak times (9 AM - 5 PM weekdays)
- Scale down during off-peak periods (nights and weekends)
- Pre-scale before marketing campaigns or expected traffic spikes
- Different profiles for holidays or special events
Autoscaling benefits:
- Prevent issues: Add capacity before performance degrades
- Cost optimization: Reduce capacity during low-utilization periods
- Consistent performance: Maintain user experience during traffic variations
- Reduce alert noise: Fewer alerts because system self-heals through scaling
Prepare dashboards and workbooks
Ensuring that your development and operations teams have access to the same telemetry and tools allows them to view patterns across your entire environment and minimize your Mean Time To Detect (MTTD) and Mean Time To Restore (MTTR). When both teams share visibility, communication improves and issue resolution accelerates.
Why shared visibility matters
Without shared dashboards:
- Development and operations see different data sources
- Teams use different terminology and metrics
- Issue handoffs require extensive explanation
- Each team builds isolated monitoring views
- Blame culture emerges due to information asymmetry
With shared dashboards:
- Common operating picture: Everyone sees the same real-time data
- Shared vocabulary: Consistent metrics and terminology
- Faster diagnosis: Both teams can investigate together
- Collaborative culture: Shared responsibility for reliability
- Reduced MTTD: Issues visible to both teams immediately
- Reduced MTTR: Coordinated response with full context
Custom dashboards for different roles
Prepare custom dashboards based on standard metrics and logs for the different roles in your organization. Dashboards can combine data from all Azure resources into a single view:
Role-specific dashboard examples:
1. Executive dashboard:
- Business metrics: Revenue, orders, active users
- Availability: Uptime percentage and incident count
- Performance: User satisfaction scores
- Cost: Monthly Azure spend and trends
- Purpose: High-level view of system health and business impact
2. Operations dashboard:
- Infrastructure health: VM CPU/memory, disk space, network throughput
- Application health: Request rate, response time, error rate
- Dependencies: Database performance, external API health
- Alerts: Active incidents and their severity
- Purpose: Real-time operational awareness and incident response
3. Developer dashboard:
- Application performance: Response times by endpoint
- Error tracking: Exception types, frequency, affected users
- Dependency performance: Database query times, API call latencies
- Feature usage: Telemetry for newly deployed features
- Purpose: Development feedback and performance optimization
4. Support dashboard:
- User experience metrics: Page load times, failed requests
- Error search: Find exceptions affecting specific users
- Transaction tracking: End-to-end traces for troubleshooting
- Known issues: Links to incident reports and workarounds
- Purpose: Customer support and troubleshooting
Dashboard best practices:
- Limit information density: 6-12 visualizations per dashboard maximum
- Use consistent time ranges: All charts should show the same time window
- Include context: Add text tiles explaining what charts show
- Enable drill-down: Link to detailed logs or metrics for investigation
- Auto-refresh: Update dashboards automatically for real-time monitoring
- Share widely: Publish dashboards to teams, display on monitors
Workbooks for knowledge sharing
Prepare Workbooks to ensure knowledge sharing between development and operations. Workbooks are interactive documents that combine:
- Narrative text: Explanations, documentation, troubleshooting steps
- Metric charts: Visualizations of time-series data
- Log queries: KQL queries showing detailed telemetry
- Parameters: User-selectable filters (time range, environment, application)
- Conditional content: Show different sections based on data values
Workbook use cases:
1. Dynamic reports:
- Weekly performance review: Automated weekly report showing key metrics
- Deployment impact analysis: Compare performance before/after deployments
- Capacity planning: Historical resource utilization trends
- Cost analysis: Breakdown of Azure spending by resource type
- User engagement: Application usage patterns and trends
2. Troubleshooting guides:
- High CPU investigation: Step-by-step guide with embedded queries
- Slow request diagnosis: Analyze request duration with dependency breakdown
- Error spike investigation: Identify root cause of sudden error increases
- Memory leak detection: Queries and visualizations for memory analysis
- Database performance: Query performance analysis and index recommendations
3. Runbooks and playbooks:
- Incident response: Standardized steps for different incident types
- Deployment checklist: Pre- and post-deployment validation steps
- Scaling procedures: When and how to scale resources
- Failover procedures: Steps for failing over to disaster recovery region
Example troubleshooting workbook structure:
Section 1: Symptom identification
- Parameter selection: Time range, application, environment
- Overview chart: Request rate, response time, error rate
- Conditional alert: "Error rate is elevated - continue investigation"
Section 2: Error analysis
- Query: Top 10 exception types with counts
- Chart: Error timeline showing when spike began
- Query: Affected users and geographic distribution
Section 3: Dependency check
- Query: Response times for all dependencies (database, APIs)
- Chart: Dependency failure rates over time
- Query: Slow database queries with execution times
Section 4: Recent changes
- Query: Recent deployments from Application Insights
- Query: Recent configuration changes from Azure Activity Log
- Text: "Compare timeline with error spike - correlation?"
Section 5: Recommended actions
- Conditional text based on findings: "Database queries are slow - review query plan"
- Links to runbooks for specific remediation steps
- Button to create incident with pre-filled information
Workbook creation best practices:
- Start with common scenarios: Build workbooks for frequently encountered issues
- Involve both teams: Developers write queries, operations refine workflow
- Test with real incidents: Validate workbooks during actual troubleshooting
- Version control: Store workbook JSON in source control
- Share and iterate: Publish workbooks, gather feedback, improve over time
- Document parameters: Clearly explain how to use filters and selections
Continuously optimize
Monitoring is one of the fundamental aspects of the popular Build-Measure-Learn philosophy, which recommends continuously tracking your KPIs and user behavior metrics and optimizing them through planning iterations. Continuous optimization means you don't just monitor to maintain current performance—you monitor to identify opportunities for improvement.
The Build-Measure-Learn cycle
Build: Develop and deploy features based on hypotheses
- "Adding a product recommendation engine will increase purchases"
- "Implementing caching will reduce database load"
- "Redesigning the checkout flow will reduce abandonment"
Measure: Collect data about feature performance and impact
- Track custom events for feature usage
- Monitor performance metrics before and after changes
- Measure business outcomes (conversion rate, revenue, engagement)
Learn: Analyze data to validate or refute hypotheses
- Did the change achieve the expected outcome?
- Were there unintended consequences?
- What should we build next?
Iterate: Use learnings to inform next development cycle
- Double down on successful changes
- Roll back or refine unsuccessful changes
- Generate new hypotheses from insights
How Azure Monitor enables continuous optimization
Azure Monitor helps you collect metrics and logs relevant to your business and add new data points in the following deployment:
Baseline establishment:
- Capture current performance metrics before changes
- Document existing user behavior patterns
- Record resource utilization levels
- Measure business KPIs at baseline
Incremental instrumentation:
- Add custom events for new features with each deployment
- Instrument A/B test variants to compare outcomes
- Track business-specific metrics (cart value, time to conversion)
- Measure user engagement with specific features
Trend analysis:
- Compare performance across releases
- Identify gradual degradation before it becomes critical
- Spot opportunities for optimization (underutilized features, bottlenecks)
- Forecast future capacity needs based on growth trends
Tracking end-user behavior and engagement
Use tools in Application Insights to track end-user behavior and engagement:
User analytics capabilities:
1. User flows:
- Visualize the path users take through your application
- Identify where users drop off in multi-step processes
- Understand common navigation patterns
- Discover unexpected usage patterns
Example insight: "60% of users abandon checkout at the shipping information page—simplify this step."
2. Funnels:
- Define conversion funnels for critical business processes
- Measure drop-off rates between steps
- Compare funnel performance across user segments
- Identify optimization opportunities
Example funnel: Home page → Product page → Add to cart → Checkout → Payment → Confirmation
- Measure percentage completing each step
- Identify which step has highest abandonment
3. Cohorts:
- Group users by behavior, demographics, or other attributes
- Compare metrics across different user segments
- Track cohort behavior over time
- Understand which user groups drive the most value
Example cohorts:
- Mobile vs. desktop users
- First-time vs. returning customers
- Geographic regions
- Users who completed specific actions
4. Retention:
- Measure how many users return to the application
- Understand which features drive engagement
- Calculate customer lifetime value
- Identify at-risk user segments
Retention metrics:
- Daily Active Users (DAU)
- Monthly Active Users (MAU)
- DAU/MAU ratio (stickiness)
- User churn rate
5. User timeline:
- View complete history of individual user interactions
- Reconstruct user sessions for support scenarios
- Understand context around errors or issues
- Validate hypotheses about user behavior
Impact analysis for prioritization
Use Impact Analysis to help you prioritize which areas to focus on to drive important KPIs:
Impact analysis answers:
- Page load time impact: How does page load time affect conversion rate?
- Feature usage impact: Do users who use feature X have higher engagement?
- Performance impact: Does slow response time correlate with abandonment?
- Error impact: How do exceptions affect user satisfaction?
Example impact analysis:
Question: How does checkout page load time impact purchase completion rate?
Analysis results:
| Page Load Time | Conversion Rate | Sample Size |
|---|---|---|
| < 1 second | 45% | 15,000 users |
| 1-2 seconds | 38% | 22,000 users |
| 2-3 seconds | 28% | 18,000 users |
| > 3 seconds | 15% | 12,000 users |
Insight: Improving checkout page load time from 2.5 seconds to under 1 second could increase conversion rate from 28% to 45%—a 17 percentage point improvement.
Prioritization decision: This optimization would have massive business impact and should be prioritized over other performance improvements.
Optimization workflow example
Week 1: Baseline measurement
- Current average response time: 800ms
- Conversion rate: 12%
- Cart abandonment rate: 68%
Week 2-3: Implement optimization
- Add Redis cache for product catalog
- Optimize database queries
- Implement CDN for static assets
- Deploy using canary release pattern
Week 4: Measure impact
- New average response time: 350ms (56% improvement)
- Conversion rate: 14.5% (21% improvement)
- Cart abandonment rate: 62% (6 percentage point improvement)
Week 5: Learn and iterate
- Response time improvement directly correlates with conversion improvement
- Next hypothesis: Further reducing response time below 300ms will continue improvement
- New experiment: Implement edge caching and API gateway
Week 6: Next optimization cycle
- Based on impact analysis, focus on most valuable pages first (product detail, checkout)
- Monitor both technical metrics (response time) and business metrics (conversion)
- Continue iterative improvement
Key metrics for continuous optimization
Technical performance metrics:
- Response time: 95th percentile should be primary metric (average hides issues)
- Error rate: Track errors per thousand requests
- Availability: Uptime percentage with realistic measurement (exclude maintenance)
- Throughput: Requests per second to understand capacity
Business outcome metrics:
- Conversion rate: Percentage of users completing desired action
- Revenue per user: Direct business value measurement
- Time to value: How quickly users achieve their goal
- User satisfaction: Net Promoter Score or similar surveys
User engagement metrics:
- Session duration: How long users spend in the application
- Pages per session: Depth of engagement
- Return visit rate: Percentage of users who return
- Feature adoption: Percentage of users utilizing new features
Optimization best practices:
- One change at a time: Isolate variables to understand causation
- Sufficient sample size: Ensure statistical significance before drawing conclusions
- Consider seasonality: Account for day-of-week and time-of-year variations
- Measure both sides: Track intended benefits and unintended consequences
- Document decisions: Record what you learned and why you made changes
- Share insights: Ensure entire organization learns from optimization experiments