Define the use cases and interoperability of Data Deduplication
Your Data Deduplication savings vary by data type, the mix of data, the size of the volumes, and the files that these volumes contain. You have the option to evaluate the savings by volume before you enable deduplication.
Data Deduplication use cases
The following list provides typical deduplication scenarios and their respective volume space savings:
| Use case | Content | Space savings |
|---|---|---|
| User documents | Group content publication or sharing, user home folders, and profile redirection for accessing offline files | 30 to 50 percent |
| Software deployment shares | Software binaries, cab files, symbols files, images, and updates | 70 to 80 percent |
| Virtualization libraries | virtual hard disk files (i.e., .vhd and .vhdx files) storage for provisioning to hypervisors | 80 to 95 percent |
| General file share | a mix of all the previously identified data types | 50 to 60 percent |
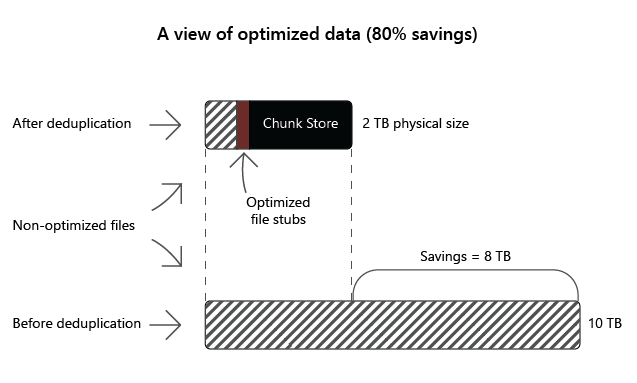
Recommended Data Deduplication use cases
Based on potentials savings and typical resource usage in Windows Server, deployment candidates for deduplication are ranked as ideal, should be evaluated or not ideal candidates.
- Ideal candidates for deduplication:
- Folder redirection servers.
- Virtualization depot or provisioning library.
- Software deployment shares.
- Microsoft SQL Server and Microsoft Exchange Server backup volumes.
- Files on Scale-out File Servers (SOFS) Cluster Shared Volumes (CSVs).
- Virtualized backup VHDs (for example, Microsoft System Center Data Protection Manager).
- Virtualized Desktop Infrastructure VDI VHDs (only personal VDIs).
Important
In most VDI deployments, special planning is required to consider boot storms. This term refers to the situation in which many users try to simultaneously sign in to their VDI, typically in the beginning of a business day. A boot storm imposes a heavy load on the VDI storage system and can result in long delays for VDI users during their initial sign-in. You can minimize the impact of boot storms by enabling deduplication. This way, chunks read from the on-disk deduplication store during startup of VMs are cached in memory. As a result, subsequent reads don't require frequent access to the chunks on disk because they're available in the cache.
Should be evaluated based on content:
- Line-of-business (LOB) servers.
- Static content providers.
- Web servers.
- High-performance computing (HPC).
Not ideal candidates for deduplication:
- Windows Server Update Service (WSUS).
- SQL Server and Exchange Server database volumes.
Evaluate savings with the Deduplication Evaluation Tool
You can use the Deduplication Evaluation Tool, DDPEval.exe, to determine the expected savings from deduplication on a particular volume. DDPEval.exe supports evaluating local drives and mapped or unmapped remote shares.
Tip
When you install the deduplication feature, DDPEval.exe is automatically installed to the \Windows\System32\ directory.
Data Deduplication interoperability
In Windows Server, you should consider the following related technologies and potential issues when deploying Data Deduplication:
Windows BranchCache
You can optimize access to data over the wide area network (WAN) by enabling BranchCache on Windows Server and Windows client operating systems. When combining the two technologies, all the deduplicated files are already indexed and hashed, which accelerates processing of requests for data from a branch office. This is like preindexing or prehashing a BranchCache-enabled server.
Note
BranchCache is a feature that can reduce WAN utilization and enhance network application responsiveness when users access content in a central office from branch office locations. When you enable BranchCache, a copy of the content that is retrieved from the web server or file server is cached within the branch office. If another client in the branch requests the same content, the client can download it directly from the local branch network instead of again having to use the WAN to retrieve the content from the central office.
Failover Clusters
Failover Clusters fully support Data Deduplication, which means deduplicated volumes fail over gracefully between nodes in the cluster. This, however, requires that you install the Data Deduplication feature on each node in the cluster that participates in a failover.
FSRM quotas
Although you shouldn't create a hard quota on a volume root folder enabled for deduplication, you can use File Server Resource Manager (FSRM) to create a soft quota in such scenario. When FSRM encounters a deduplicated file, it identifies the file's logical size for quota calculations. Consequently, quota usage (including any quota thresholds) doesn't change when deduplication processes a file. All other FSRM quota functionality, including volume-root soft quotas and quotas on subfolders, will work as expected when using deduplication.
Note
FSRM is a suite of tools that help you identify, control, and manage the type and quantity of data stored on your servers. FSRM enables you to configure hard or soft quotas on folders and volumes. A hard quota prevents users from saving files after the quota limit is reached; whereas, a soft quota doesn't enforce the quota limit, it generates a notification when the data on the volume reaches a threshold.
DFS Replication
Data Deduplication is compatible with Distributed File System (DFS) Replication. Optimizing or unoptimizing a file won't trigger a replication because the file doesn't change. DFS Replication uses remote differential compression (RDC) (not the chunks in the chunk store) for over-the-wire savings.