Explore the Windows Server File Server high-availability options
File services represent one of the prevailing types of Windows Server workloads. In many cases, their availability is critical to business operations. Windows Server offers several different methods to help ensure that availability.
Windows File Server high availability options
To implement resilient file services on Windows Server, you can leverage high availability inherent to Failover Clustering roles. Alternatively, you can provide resiliency by replicating content of volumes hosting file shares with Storage Replica.
Windows Server File Server Failover Clustering options
You can deploy and configure a clustered file server by using either of the following methods:
- File Server for general use. This is the traditional file server role that has been available ever since the introduction of Failover Clustering in Windows Server operating system. From the availability and scalability standpoint, the clustered role operates in the active-passive mode, which means that at any given time, the corresponding file shares, referred to as clustered file shares, are available on one of cluster nodes. If that node fails, another node takes ownership of the role and its resources, maintaining the availability of the shared folders. However, clients always access them via a single node. This type of file server implementation is suitable for information worker scenarios. This term represents standard business scenarios, where users rely on file shares to store their home folders, roaming profiles, departmental shared data, including documents, spreadsheets, and other types of unstructured or semi-structured data.
- SOFS for application data. This clustered file server type is intended for server application data, such as Microsoft Hyper-V virtual machine files or SQL Server database files. It offers superior reliability, availability, manageability, and performance, with the clustered role operating in the active-active mode. This means that all file shares, referred to in this case as scale-out file shares, are available simultaneously on all cluster nodes. This approach is optimal when deploying either Hyper-V over Server Message Block (SMB) or Microsoft SQL Server over SMB.
Storage Replica
Storage Replica is a Windows Server technology that enables unidirectional, storage-agnostic replication between storage volumes residing on standalone or clustered-servers for high-availability or disaster recovery purposes. You can choose synchronous or asynchronous replication depending on the network latency and distance between the servers. With Storage Replica, only the source volume is accessible during normal business operations. In case of a failure, you can fail over to the target volume and bring it online.
Storage Replica supports three scenarios:
- Server-to-server.
- Cluster-to-cluster.
- Stretch cluster.
With the clustering scenarios, you can implement either File Server for general use or SOFS. With server-to-server replication, Storage Replica provides resiliency for traditional, standalone file shares.
Synchronous and asynchronous replication
Storage Replica supports two types of replication:
- Synchronous replication replicates volumes between sites in relative proximity to each other. Replication is crash-consistent, which ensures zero data loss at the file system–level during a failover.
- Asynchronous replication enables replication across longer distances in cases where network round-trip latency exceeds 5 milliseconds (ms), however, it's subject to data loss. The extent of data loss depends on the lag of replication between the source and target volumes.
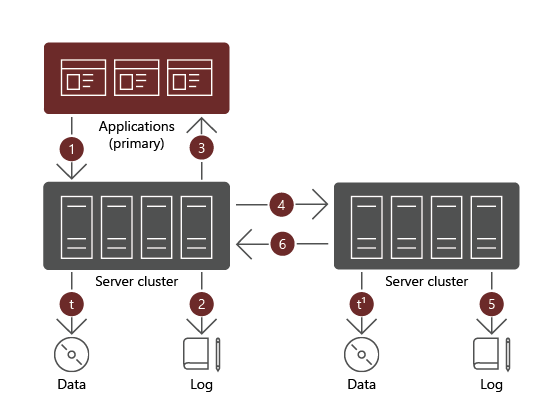
When using synchronous replication, a data write must complete successfully on both volumes. If that's not the case, the workload initiating the write must retry the same operation. With synchronous replication, the data on both volumes is identical.
Use synchronous replication when it's imperative that you avoid data loss. Synchronous replication requires low network latency to minimize wait for the acknowledgment of the remote write. This requirement limits the distance between the servers or clusters hosting each volume.
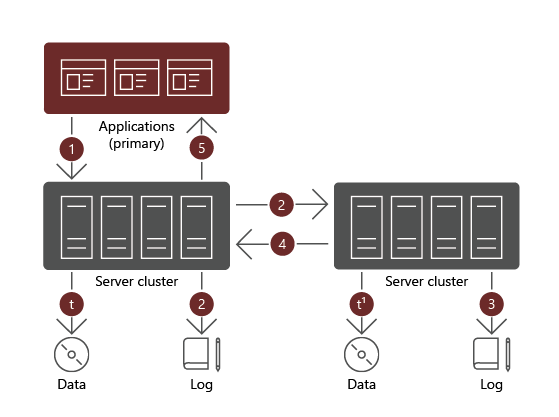
When using asynchronous replication, after a data write completes successfully on the primary volume, the workload initiating the write receives a confirmation and can proceed with another I/O operation. The corresponding data writes takes place afterwards on the secondary volume, without affecting the primary volume.