How Azure Data Factory works
Here, you learn about the components and interconnected systems of Azure Data Factory and how they work. This knowledge should help you determine how you can best use Azure Data Factory to meet your organization's requirements.
Azure Data Factory is a collection of interconnected systems that combine to provide an end-to-end data analytics platform. In this unit, you learn about the following Azure Data Factory functions:
- Connect and collect
- Transform and enrich
- Continuous integration and delivery (CI/CD) and publish
- Monitoring
You also learn about these key components of Azure Data Factory:
- Pipelines
- Activities
- Datasets
- Linked services
- Data flows
- Integration runtimes
Azure Data Factory functions
Azure Data Factory consists of several functions that combine to provide your data engineers with a complete data-analytics platform.
Connect and collect
The first part of the process is to collect the required data from the appropriate data sources. These sources can be located in different locations, including on-premises sources and in the cloud. The data might be:
- Structured
- Unstructured
- Semi-structured
In addition, this disparate data might arrive at different speeds and intervals. With Azure Data Factory, you can use the copy activity to move data from various sources to a single centralized data store in the cloud. After you copy the data, you use other systems to transform and analyze it.
The copy activity performs the following high-level steps:
Read data from source data store.
Perform the following tasks on the data:
- Serialization/deserialization
- Compression/decompression
- Column mapping
Note
There might be additional tasks.
Write data to the destination data store (known as the sink).
This process is summarized in the following graphic:

Transform and enrich
After you successfully copy the data to a central cloud-based location, you can process and transform the data as needed by using Azure Data Factory mapping data flows. Data flows enable you to create data transformation graphs that run on Spark. However, you don't need to understand Spark clusters or Spark programming.
Tip
Although not necessary, you might prefer to code your transformations manually. If so, Azure Data Factory supports external activities for running your transformations.
CI/CD and publish
Support for CI/CD enables you to develop and deliver your extract, transform, load (ETL) processes incrementally before you publish. Azure Data Factory provides for CI/CD of your data pipelines by using:
- Azure DevOps
- GitHub
Note
Continuous integration means automatically testing each change made to your codebase as soon as possible. Continuous delivery follows this testing and pushes changes to a staging or production system.
After Azure Data Factory refines the raw data, you can load the data into whichever analytics engine your business users can access from their business intelligence tools, including:
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Monitor
After you successfully build and deploy your data-integration pipeline, it's important that you can monitor your scheduled activities and pipelines. Monitoring allows you to track success and failure rates. Azure Data Factory provides support for pipeline monitoring by using one of the following methods:
- Azure Monitor
- API
- PowerShell
- Azure Monitor logs
- Health panels in the Azure portal
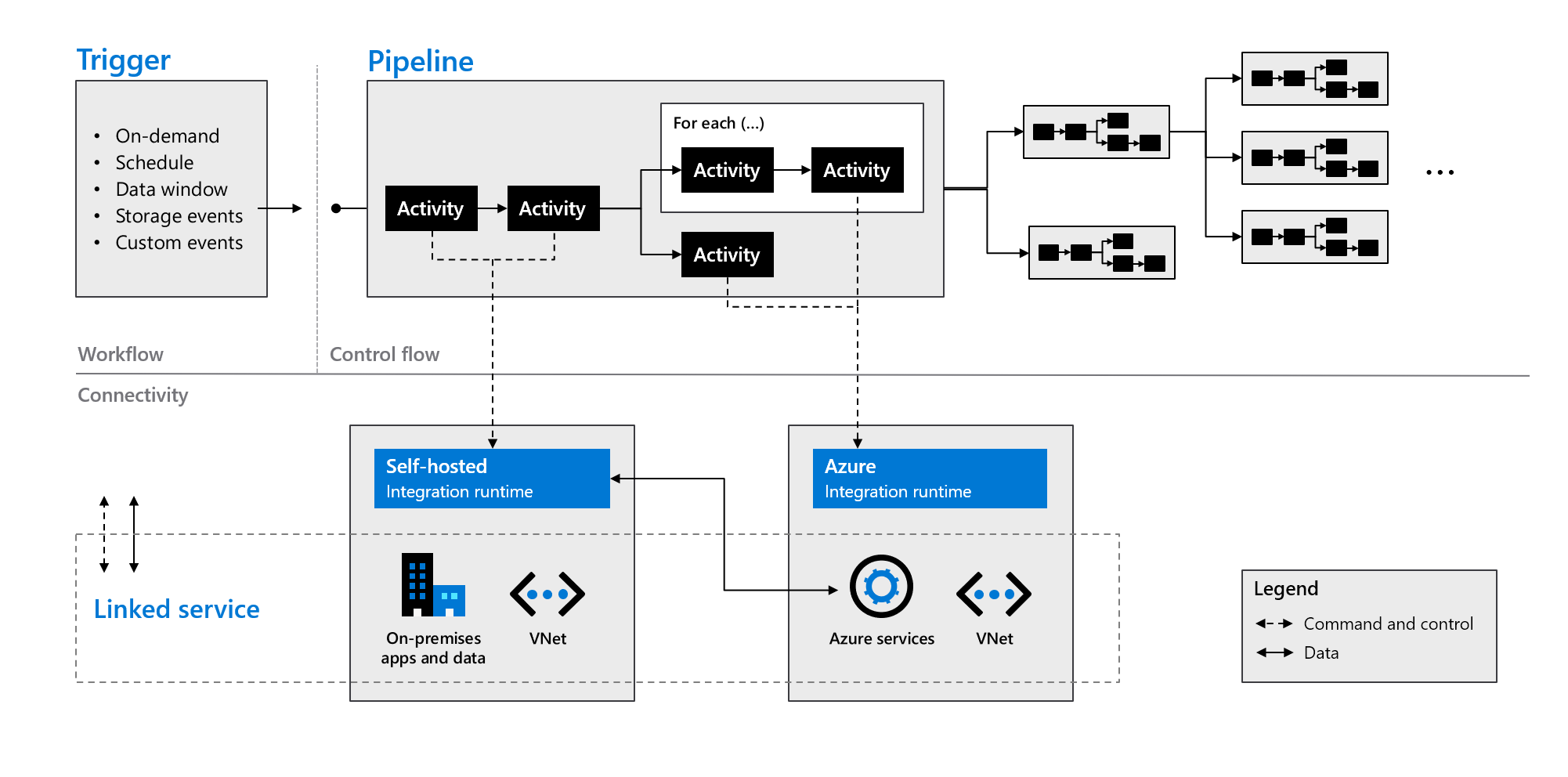
Azure Data Factory components
Azure Data Factory is composed of the components described in the following table:
| Component | Description |
|---|---|
| Pipelines | A logical grouping of activities that perform a specific unit of work. These activities together perform a task. The advantage of using a pipeline is that you can more easily manage the activities as a set instead of as individual items. |
| Activities | A single processing step in a pipeline. Azure Data Factory supports three types of activity: data movement, data transformation, and control activities. |
| Datasets | Represent data structures within your data stores. Datasets point to (or reference) the data that you want to use in your activities as either inputs or outputs. |
| Linked services | Define the required connection information needed for Azure Data Factory to connect to external resources, such as a data source. Azure Data Factory uses linked services for two purposes: to represent a data store or a compute resource. |
| Data flows | Enable your data engineers to develop data transformation logic without needing to write code. Data flows are run as activities within Azure Data Factory pipelines that use scaled-out Apache Spark clusters. |
| Integration runtimes | Azure Data Factory uses the compute infrastructure to provide the following data integration capabilities across different network environments: data flow, data movement, activity dispatch, and SQL Server Integration Services (SSIS) package execution. In Azure Data Factory, an integration runtime provides the bridge between the activity and linked services. |
As indicated in the following graphic, these components work together to provide a complete end-to-end platform for data engineers. By using Data Factory, you can:
- Set triggers on-demand and schedule data processing based on your needs.
- Associate a pipeline with a trigger, or manually start it as and when needed.
- Connect to linked services (such as on-premises apps and data) or Azure services via integration runtimes.
- Monitor all of your pipeline runs natively in the Azure Data Factory user experience or by using Azure Monitor.