How Azure Machine Learning works
Using Azure Machine Learning requires an Azure account and Azure subscription. The subscription has standard and free pricing tiers and provides an endpoint and subscription key to access the service.
You can access Azure Machine Learning on the cloud or on your local machine through the Python SDK, REST API, and Command Line Interface (CLI) extension. If you prefer low or no-code options, then you can use Azure Machine Learning studio to quickly train and deploy machine learning models.
Azure Machine Learning manages all the resources you need for the machine learning lifecycle inside a workspace. Multiple people can share workspaces, and they can include things like the computing resources available for your notebooks, training clusters, and pipelines. Workspaces are also the logical containers for your data stores and a repository for models and anything else within the model lifecycle.
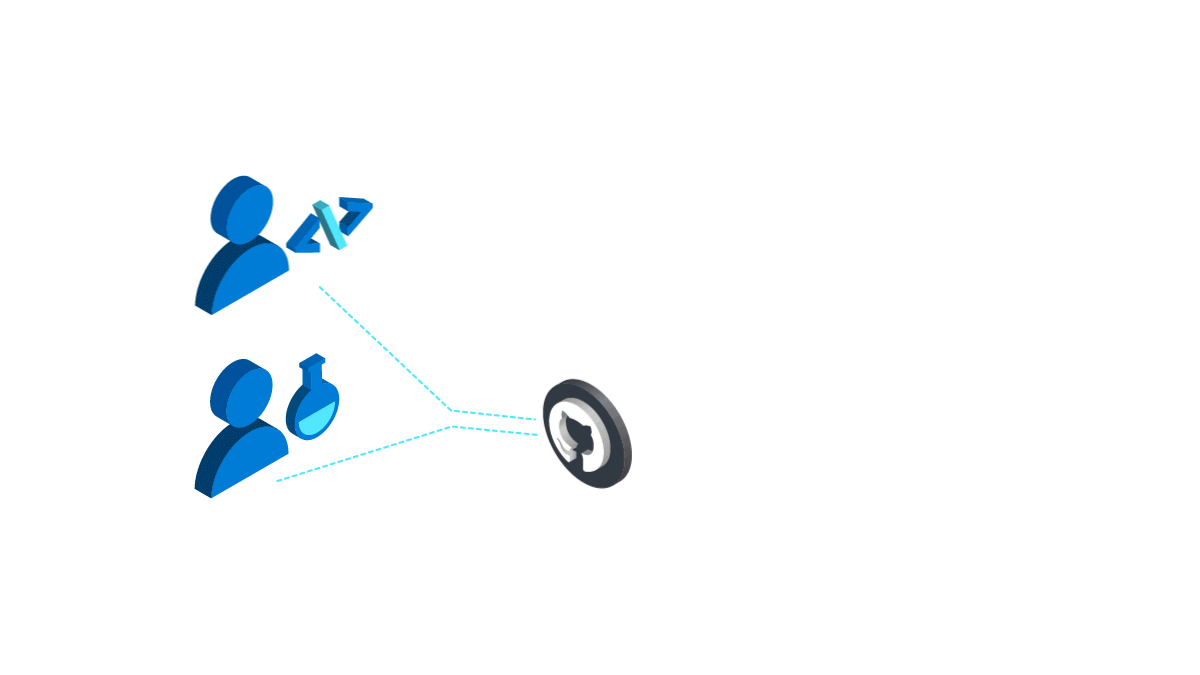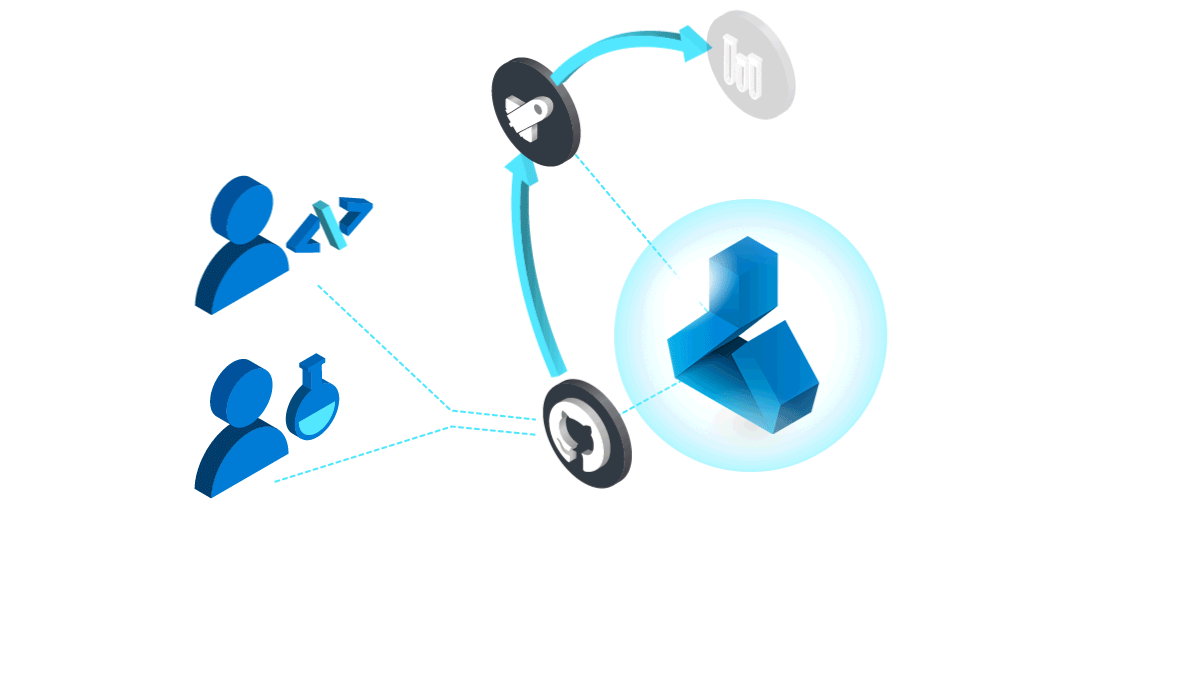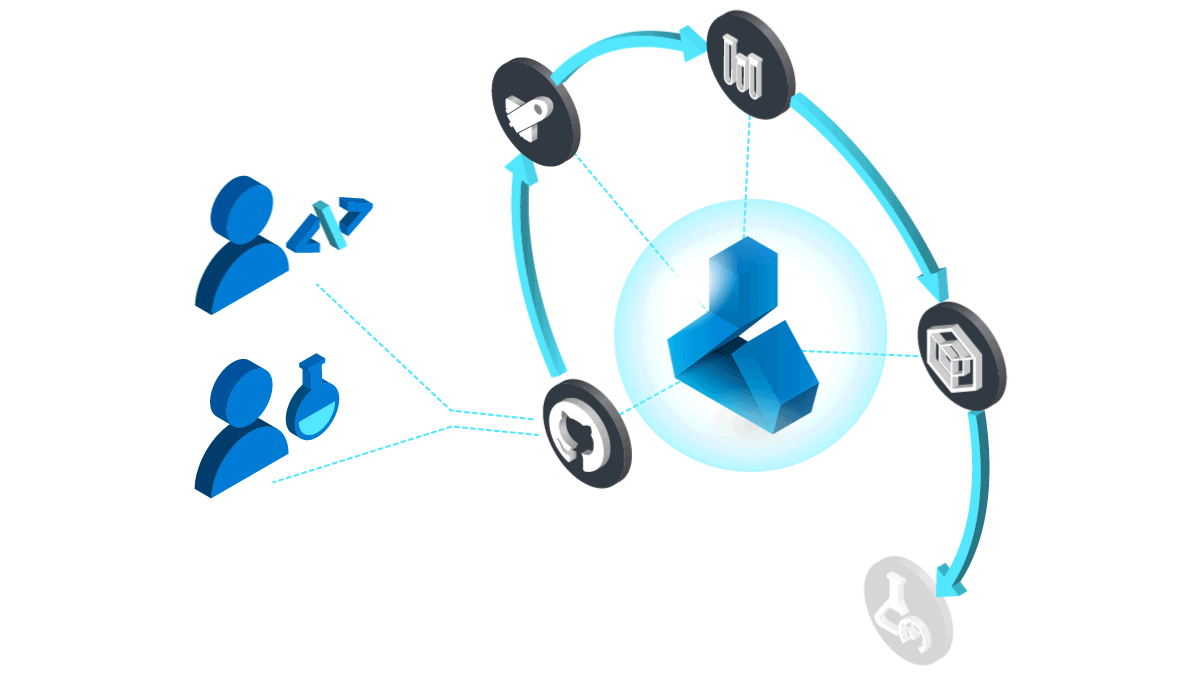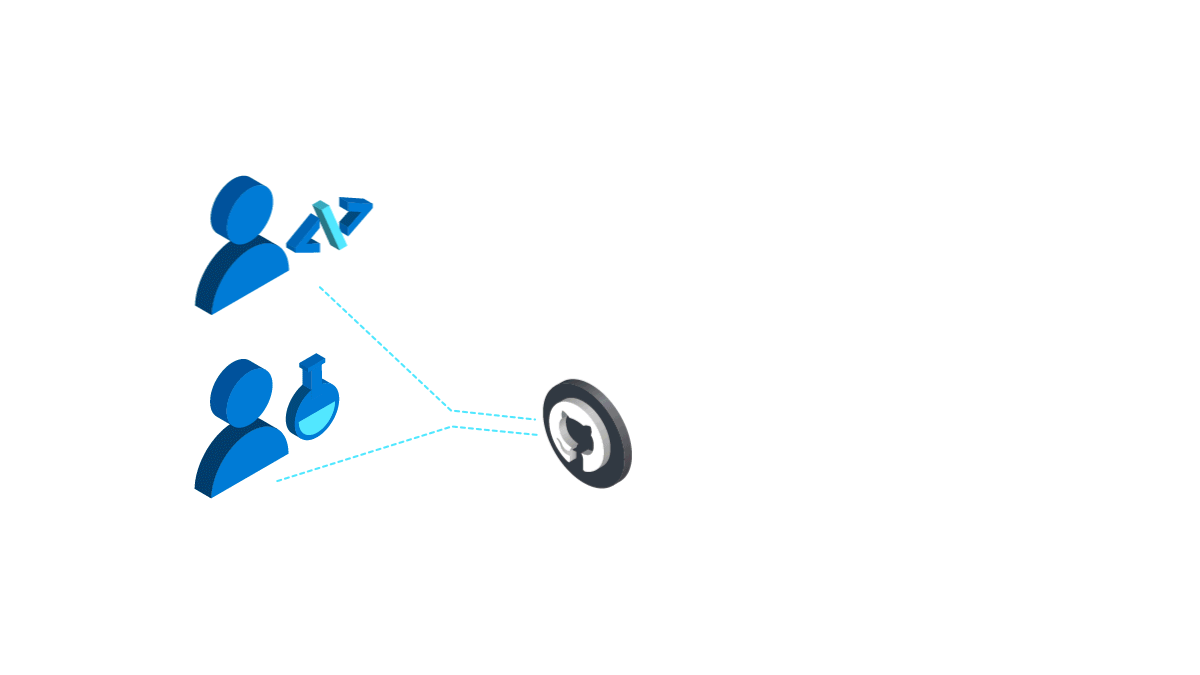
How to create machine learning models
You can create models using the SDK, import them from ML frameworks, or create them without code using the Azure Machine Learning studio. When you connect to a workspace, you can select various development environments with preloaded packages that contain curated environments for popular frameworks, such as TensorFlow and PyTorch. You can then choose compute targets to run a training script locally or on a virtual machine to create a model. Compute targets within Azure Machine Learning can automatically scale up and manage jobs to use GPU and CPU resources efficiently.
You can log and monitor the status of runs natively via the SDK, Azure Monitor, and Azure Machine Learning studio, or by installing packages to run MLFlow and TensorBoard. You can then view visualizations of training runs within the Azure Studio or workspace to drill down on results and metrics.
The following example shows how you can customize Azure Machine Learning studio's visualization to add charts, compare data, and apply filters to better analyze your results and metrics.

Experiments
To train a model in Azure Machine Learning, you run an experiment, which is when a training script runs that can generate metrics and outputs that are tracked. You can run the same experiment multiple times with different hyperparameters, data, code, or settings. The workspace keeps a history of all training runs, including logs, metrics, outputs, and a snapshot of your scripts within the environment. In a collaborative project, experiment logs are a great way to review and track progress. They can show who's publishing or changing models, why changes were made, and when models were deployed or used in production.
Pipelines
A pipeline is a workflow of a complete machine learning task that can include data preparation, training, testing, and deployment. Pipelines have many uses. You can make a pipeline that trains models, one that makes predictions in real time, or one that only cleans data. Because each step in a pipeline is independent, multiple people can work on different steps within the same pipeline at once. Azure Machine Learning Pipelines can save you time by only rerunning steps whose inputs have changed, drastically reducing runtimes if you're simply tweaking hyperparameters or other steps. Both Azure Data Factory and Azure Pipelines provide out-of-the-box pipelines for Azure Machine Learning, so you can focus on machine learning instead of infrastructure.
Data assets
You can create data assets from datastores, public URLs, and Azure Open Datasets. By creating a data asset, you reference the data source location so data from training sets and pipelines is stored without altering the original data. Data assets can then be registered, versioned, tracked, and traced to permit reuse and sharing across teams, roles, and experiments quickly. It's also possible to version reproducible experiments, allowing better analysis of data viability and model performance.
Azure Machine Learning can periodically check for newly stored data with an incremental refresh, which enables data assets to be updated automatically when new data is added to the datastore.
Labeling
Data labeling is a centralized place to create, manage, and monitor labeling tasks. You can administer all data labeling projects via the Azure Machine Learning studio or workspace dashboard, where team members can view progress and assist in collaborative labeling projects. Human-in-the-loop labeling can take place here, allowing team members to manually add tags to train the ML-labeling models. After enough labels are submitted, a classification model is used to predict tags. Team members can then accept or reject instances of ML-tagged data to help train the labeling model's accuracy. Eventually, the model will be capable of labeling the data without assistance.
The following shows an example of a labeling task underway in Azure Machine Learning studio.

Deploying machine learning models
Azure Machine Learning can package and run models in Docker containers for deployment. These containers are separate from the run script, so you can quickly swap or update your models with improved ones while leaving the script unmodified.
You can also download the model into the Open Neural Network Exchange (ONNX) format, which imparts broad flexibility in potential deployment platforms and devices such as iOS, Android, and Linux.
Azure Machine Learning provides prepackaged container images that include stable environments, with preloaded Python packages and settings. These container images help you deploy to popular machine learning frameworks such as TensorFlow and PyTorch with minimal setup.