Identify key components of LLM applications
Large Language Models (LLMs) are like sophisticated language processing systems designed to understand and generate human language. Think of them as having four essential parts that work together, similar to how a car needs an engine, fuel system, transmission, and steering wheel to function properly.
- Prompt: Your instructions to the model. The prompt is how you communicate with the LLM. It's your question, request, or instruction.
- Tokenizer: Breaks down language. The tokenizer is a language translator that converts human text into a format the computer can understand.
- Model: The 'brain' of the operation. The model is the actual 'brain' that processes information and generates responses. It's typically based on the transformer architecture, utilizes self-attention mechanisms to process text, and generates contextually relevant responses.
- Tasks: What LLMs can do. Tasks are the different language-related jobs that LLMs can perform, such as text classification, translation, and dialogue generation.
These components create a powerful language processing system:
- You provide a prompt (your instruction)
- The tokenizer breaks it down (makes it computer-readable)
- The model processes it (using transformer architecture and self-attention)
- The model performs the task (generates the response you need)
This coordinated system is what enables LLMs to perform complex language tasks with remarkable accuracy and fluency, making them useful for everything from writing assistance to customer service to creative content generation.
Understand the tasks LLMs perform
LLMs are designed to perform a wide range of language-related tasks. LLMs are ideal for natural language processing, or NLP (1), tasks, because of their deep understanding of text and context. Natural Language Processing (NLP) is the field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language in a way that is meaningful and useful. In the context of LLM tasks, NLP represents the category of language-related functions that LLMs models excel at because of their deep understanding of text and context.
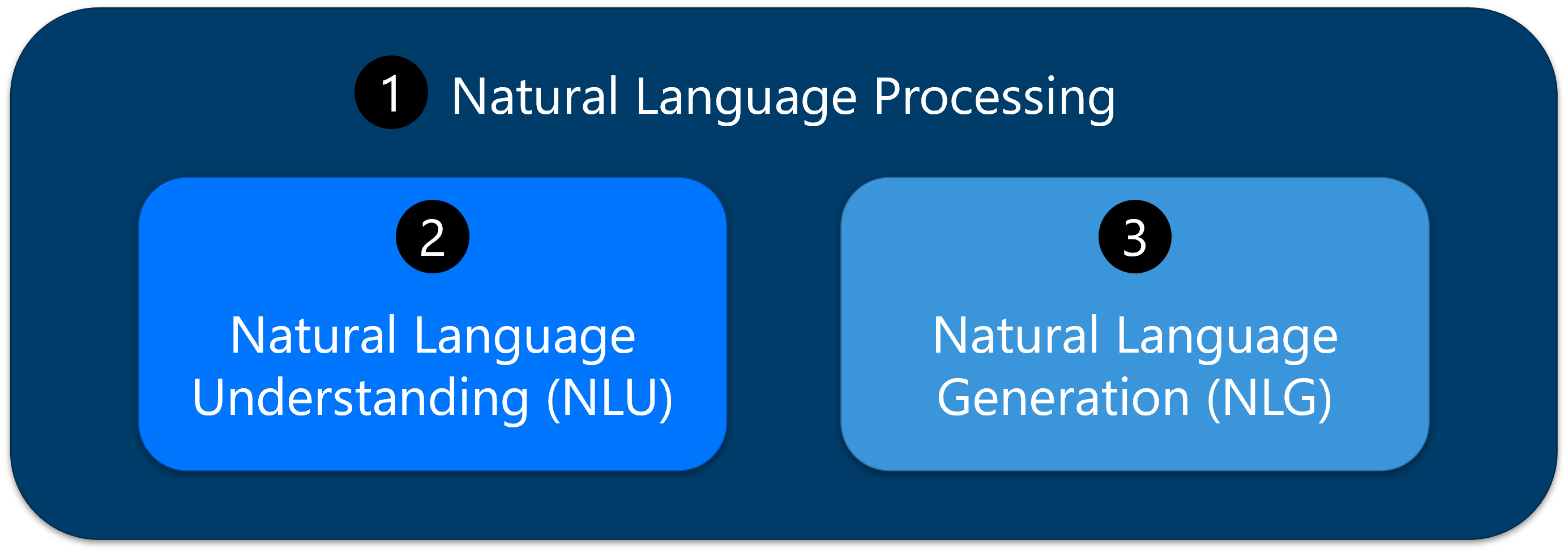
One category of NLP tasks includes natural language understanding, or NLU (2), tasks such as sentiment analysis, named entity recognition (NER), and text classification, which involve extracting meaning and identifying specific elements within the text.
Another set of NLP tasks falls under natural language generation, or NLG (3), including text completion, summarization, translation, and content creation, where the model generates coherent and contextually appropriate text based on given inputs.
LLMs are also used in dialogue systems and conversational agents, where they can engage in human-like conversations, providing relevant and accurate responses to user queries.
Understand the importance of the tokenizer
Tokenization is a vital preprocessing step in LLMs. It converts human text into a format a computer can understand. The text is broken down into manageable units called tokens. These tokens can be words, subwords, or even individual characters, depending on the tokenization strategy employed.
The tokenization process can be summarized like this:
- Break text into tokens: "Hello world" might become ["Hello", "world"] or even ["Hel", "lo", "wor", "ld"]
- Handle different languages: Processes English, Spanish, Chinese, etc.
- Make processing efficient: Smaller pieces are easier for the model to work with
- Convert to numbers: Computers work with numbers, not letters, so "Hello" becomes something like [7592, 1917]
Modern tokenizers, such as Byte Pair Encoding (BPE) and WordPiece, split rare or unknown words into subword units, allowing the model to handle out-of-vocabulary terms more effectively.
For example, consider the following sentence:
I heard a dog bark loudly at a cat
To tokenize this text, you can identify each discrete word and assign token IDs to them. For example:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- a (3)
- cat (8)
The sentence can now be represented with the tokens:
{1 2 3 4 5 6 7 3 8}
Tokenization helps the model to maintain a balance between vocabulary size and representational efficiency, ensuring that it can process diverse text inputs accurately.
Tokenization also enables the model to convert text into numerical formats that can be efficiently processed during training and inference.
Understand the underlying model architecture
Think of an LLM's architecture like the blueprint of a house - it shows how all the parts are organized and work together to create something functional.
LLMs are built using something called the transformer architecture. Imagine you're reading a book and you need to understand how different sentences relate to each other. The traditional approach is to read word by word, left to right, like reading normally. In the transformer approach, you could look at the entire page at once and instantly see how all the words connect to each other.
Self-attention is a key innovation used in the transformer architecture. It's like having a super-smart highlighter that automatically marks the most important words for understanding each sentence.
For example: In the sentence "The dog chased the ball because it was excited," self-attention helps the model know that "it" refers to "the dog" (not the ball), even though "dog" appears earlier in the sentence.
Transformers consist of layers of encoders and decoders that work together to analyze input text and generate outputs. The self-attention mechanism allows the model to weigh the importance of different words in a sentence, enabling it to capture long-range dependencies and context effectively.
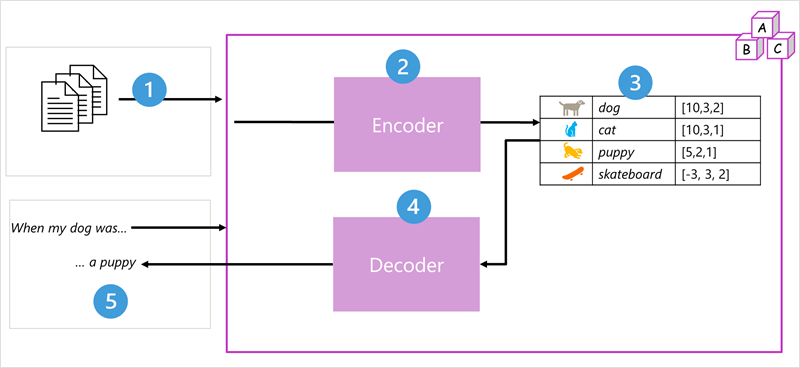
Let's use this diagram as an example of how LLM processing works.
The LLM is trained on a large volume of natural language text.
Step 1: Input - Training documents and a prompt "When my dog was..." enter the system.
Step 2: Encoder (The analyzer) - Breaks text into tokens and analyzes its meaning. The encoder block processes token sequences using self-attention to determine the relationships between tokens or words.
Step 3: Embeddings are created - The output from the encoder is a collection of vectors (multi-valued numeric arrays) in which each element of the vector represents a semantic attribute of the tokens. These vectors are referred to as embeddings. They're numerical representations that capture meaning:
- dog [10,3,2] - animal, pet, subject
- cat [10,3,1] - animal, pet, different species
- puppy [5,2,1] - young animal, related to dog
- skateboard [-3,3,2] - object, unrelated to animals
Step 4: Decoder (The writer) - The decoder block works on a new sequence of text tokens and uses the embeddings generated by the encoder to generate an appropriate natural language output. It compares the options and chooses the most appropriate response.
Step 5: Output generated - Given an input sequence like
When my dog was, the model can use the self-attention mechanism to analyze the input tokens and the semantic attributes encoded in the embeddings to predict an appropriate completion of the sentence, such asa puppy.
This architecture is highly parallelizable, making it efficient for training on large datasets. The size of the LLM, often defined by the number of parameters, determines its capacity to store linguistic knowledge and perform complex tasks. Think of parameters as millions or billions of tiny memory cells that store language rules and patterns. More memory cells mean the model can remember more about language and handle harder tasks. Large models, such as GPT-3 and GPT-4, contain billions of parameters, allowing them to store vast language knowledge.
Understand the importance of the prompt
Prompts are the initial inputs given to LLMs to guide their responses. They’re the conductor that makes all four LLM components (prompt, tokenizer, model, output) work together effectively. The quality and clarity of the prompt significantly influence the model’s performance, and a well-structured prompt can lead to more accurate and relevant responses.
Crafting effective prompts is crucial for obtaining the desired output from the model. Prompts can range from simple instructions to complex queries, and the model generates text based on the context and information provided in the prompt.
For example, a prompt can be:
Translate the following English text to French: "Hello, how are you?"
In addition to standard prompts, techniques such as prompt engineering involve refining and optimizing prompts to enhance the model’s output for specific tasks or applications.
An example of prompt engineering, where more detailed instructions are provided:
Generate a creative story about a time-traveling scientist who discovers a new planet. Include elements of adventure and mystery.
The interaction between tasks, tokenization, the model, and prompts is what makes LLMs so powerful and versatile. The model’s ability to perform various tasks is improved when you have effective tokenization, which ensures that text inputs are processed accurately. The transformer-based architecture allows the model to understand and generate text based on the tokens and the context provided by the prompts.