Configure storage and databases
Often, part of your deployment process requires that you connect to databases or storage services. This connection might be necessary to apply a database schema, to add some reference data to a database table, or to upload some blobs. In this unit, you learn about how you can extend your pipeline to work with data and storage services.
Configure your databases from a pipeline
Many databases have schemas, which represent the structure of the data contained in the database. It's often a good practice to apply a schema to your database from your deployment pipeline. This practice helps to ensure that everything your solution needs is deployed together. It also ensures that if there's a problem when the schema is applied, your pipeline displays an error. The error allows you to fix the issue and redeploy.
When you work with Azure SQL, you need to apply database schemas by connecting to the database server and executing commands by using SQL scripts. These commands are data plane operations. Your pipeline needs to authenticate to the database server and then execute the scripts. Azure Pipelines provides the SqlAzureDacpacDeployment task that can connect to an Azure SQL database server and execute commands.
Some other data and storage services don't need to be configured by using a data plane API. For example, when you work with Azure Cosmos DB, you store your data in a container. You can configure your containers by using the control plane, right from within your Bicep file. Similarly, you can deploy and manage most aspects of Azure Storage blob containers within Bicep. In the next exercise, you'll see an example of how to create a blob container from Bicep.
Add data
Many solutions require reference data to be added to their databases or storage accounts before they work. Pipelines can be a good place to add this data. After the pipeline runs, your environment is fully configured and ready to use.
It's also helpful to have sample data in your databases, especially for nonproduction environments. Sample data helps testers and other people who use those environments to be able to test your solution immediately. This data might include sample products or things like fake user accounts. Generally, you don't want to add this data to your production environment.
The approach you use to add data depends on the service you use. For example:
- To add data to an Azure SQL database, you need to execute a script, much like configuring a schema.
- To insert data in an Azure Cosmos DB, you need to access its data plane API, which might require you to write some custom script code.
- To upload blobs to an Azure Storage blob container, you can use various tools from pipeline scripts, including the AzCopy command-line application, Azure PowerShell, or Azure CLI. Each of these tools understands how to authenticate to Azure Storage on your behalf, and how to connect to the data plane API to upload blobs.
Idempotence
One of the characteristics of deployment pipelines and infrastructure as code is that you should be able to redeploy repeatedly without any adverse side effects. For example, when you redeploy a previously deployed Bicep file, Azure Resource Manager compares the file you submitted with the existing state of your Azure resources. If there are no changes, Resource Manager doesn't do anything. The ability to re-execute an operation repeatedly is called idempotence. It's a good practice to make sure your scripts and other pipeline steps are idempotent.
Idempotence is especially important when you interact with data services, because they maintain state. Imagine you're inserting a sample user into a database table from your pipeline. If you're not careful, every time you run your pipeline a new sample user is created. This result likely isn't what you want.
When you apply schemas to an Azure SQL database, you can use a data package, also called a DACPAC file, to deploy your schema. Your pipeline builds a DACPAC file from source code and creates a pipeline artifact, just like with an application. Then, the deployment stage in your pipeline publishes the DACPAC file to the database:
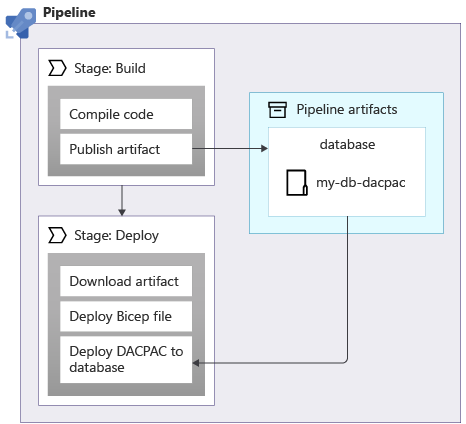
When a DACPAC file is deployed, it behaves in an idempotent way. It compares the target state of your database to the state defined in the package. In many situations, this means you don't need to write scripts that follow the principle of idempotence because the tooling handles it for you. Some of the tooling for Azure Cosmos DB and Azure Storage also behaves correctly.
But when you create sample data in an Azure SQL database, or another storage service that doesn't automatically work in an idempotent way. It's a good practice to write your script so that it creates the data only if it doesn't exist already.
It's also important to consider whether you might need to roll back deployments, such as by rerunning an older version of a deployment pipeline. Rollback of changes to your data can become complicated, so carefully consider how your solution works if you need to roll back.
Network security
Sometimes, you might apply network restrictions to some of your Azure resources. These restrictions can enforce rules about requests made to the data plane of a resource, such as:
- This database server is accessible only from a specified list of IP addresses.
- This storage account is accessible only from resources that are deployed within a specific virtual network.
Network restrictions are common with databases, because it might seem like there's no need for anything on the internet to connect to a database server.
However, network restrictions can also make it difficult for your deployment pipelines to work with your resources data planes. When you use a Microsoft-hosted pipeline agent, its IP address can't be easily known in advance, and it might be assigned from a large pool of IP addresses. Additionally, Microsoft-hosted pipeline agents can't be connected to your own virtual networks.
Some of the Azure Pipelines tasks that help you to perform data plane operations can work around these issues. For example, the SqlAzureDacpacDeployment task:
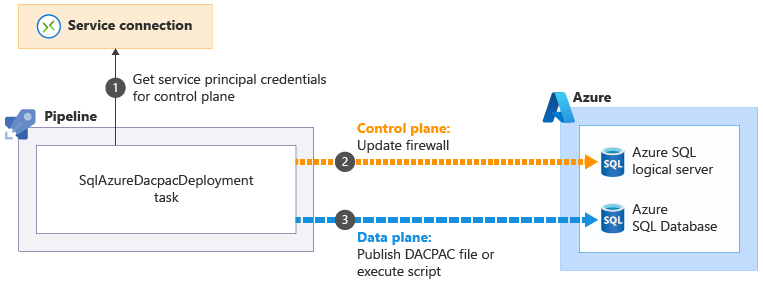
When you use the SqlAzureDacpacDeployment task to work with an Azure SQL logical server or database, it uses your pipeline's service principal to connect to the control plane for the Azure SQL logical server. It updates the firewall to allow the pipeline agent to access the server from its IP address
to connect to the control plane for the Azure SQL logical server. It updates the firewall to allow the pipeline agent to access the server from its IP address . Then, it can successfully submit the DACPAC file or script for execution
. Then, it can successfully submit the DACPAC file or script for execution . The task then automatically removes the firewall rule when it completes.
. The task then automatically removes the firewall rule when it completes.
In other situations, it's not possible to create these types of exceptions. In these circumstances, consider using a self-hosted pipeline agent, which runs on a virtual machine or other compute resource that you control. You can then configure this agent however you need. It can use a known IP address, or it can be connected to your own virtual network. We don't discuss self-hosted agents in this module, but we provide links to more information on the Summary page at the end of the module.
Your deployment pipeline
In the next exercise, you'll update your deployment pipeline to add new jobs to build your website's database components, deploy the database, and add seed data:
