Introduction
In machine learning, models are trained to predict unknown labels for new data based on correlations between known labels and features found in the training data. Depending on the algorithm used, you may need to specify hyperparameters to configure how the model is trained.
For example, the logistic regression algorithm uses a regularization rate hyperparameter to counteract overfitting; and deep learning techniques for convolutional neural networks (CNNs) use hyperparameters like learning rate to control how weights are adjusted during training, and batch size to determine how many data items are included in each training batch.
Note
Machine Learning is an academic field with its own particular terminology. Data scientists refer to the values determined from the training features as parameters, so a different term is required for values that are used to configure training behavior but which are not derived from the training data - hence the term hyperparameter.
The choice of hyperparameter values can significantly affect the resulting model, making it important to select the best possible values for your particular data and predictive performance goals.
Tuning hyperparameters
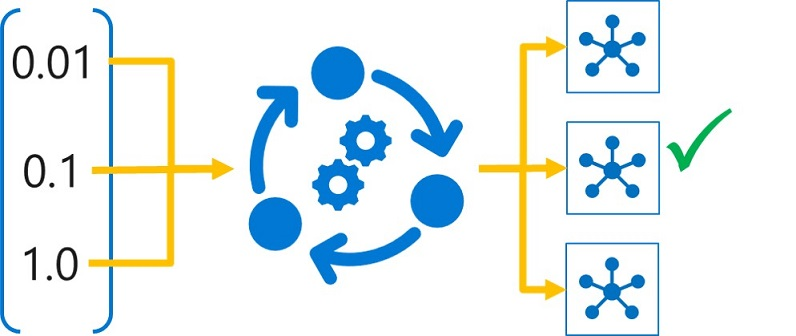
Hyperparameter tuning is accomplished by training the multiple models, using the same algorithm and training data but different hyperparameter values. The resulting model from each training run is then evaluated to determine the performance metric for which you want to optimize (for example, accuracy), and the best-performing model is selected.
In Azure Machine Learning, you can tune hyperparameters by submitting a script as a sweep job. A sweep job will run a trial for each hyperparameter combination to be tested. Each trial uses a training script with parameterized hyperparameter values to train a model, and logs the target performance metric achieved by the trained model.
Learning objectives
In this module, you'll learn how to:
- Define a hyperparameter search space.
- Configure hyperparameter sampling.
- Select an early-termination policy.
- Run a sweep job.