Describe Apache HBase
Apache HBase is an open-source, NoSQL database that is built on Apache Hadoop. HBase provides random access and strong consistency for large amounts of unstructured and semi structured data in a schemaless database organized by column families. HDInsight 4.0 HBase clusters come with Apache HBase 2.1.6 and Apache Phoenix 5.
From a user perspective, HBase is similar to a database. Data is stored in the rows and columns of a table, and data within a row is grouped by column family. HBase is a schemaless database in the sense that neither the columns nor the type of data stored in them need to be defined before using them. The open-source code scales linearly to handle petabytes of data on thousands of nodes.
HBase has the following features that make it unique
Consistent read and writes
Low latency operations
Automatic Sharding
Automatic Region Server failovers
Hadoop/HDFS/MapReduce integration
Java Client API
Supports Thrift and REST for non-java front ends
Block cache and Bloom Filters
Azure HDInsight HBase with Apache Phoenix brings the following extra benefits
SQL and No SQL interfaces
Flexible capacity planning
Global distribution and replication with Azure networking
Separation of Compute and Storage
Tightly integrated with HDInsight Enterprise security features
HDInsight HBase accelerated writes for ultra-low latency reads and writes
Apache Phoenix for real time SQL like querying
Using Azure HDInsight with HBase enables you to run NoSQL databases at massive scale. As a Data Engineer for a Contoso, you need to be able to run benchmark tests to understand the performance and scale of HDInsight HBase before you use the platform for mission critical production scenarios.
HBase on HDInsight runs with the separation of compute and storage. HDInsight HBase clusters are configured to store data directly in Azure Storage, which provides low latency and increased elasticity in performance and cost choices. This property enables customers to build interactive websites that work with large datasets. To build services that store sensor and telemetry data from millions of end points, and to analyze this data with Hadoop jobs. HBase and Hadoop are good starting points for big data projects in Azure. The services can enable real-time applications to work with large datasets. HDInsight HBase implementations use a scale-out architecture of HBase to provide automatic sharding of tables. It also provides strong consistency for reads and writes, and automatic failover. Performance is enhanced by in-memory caching for reads and high-throughput streaming for writes. HBase cluster can be created inside virtual network. For details, see Create HDInsight clusters on Azure Virtual Network.
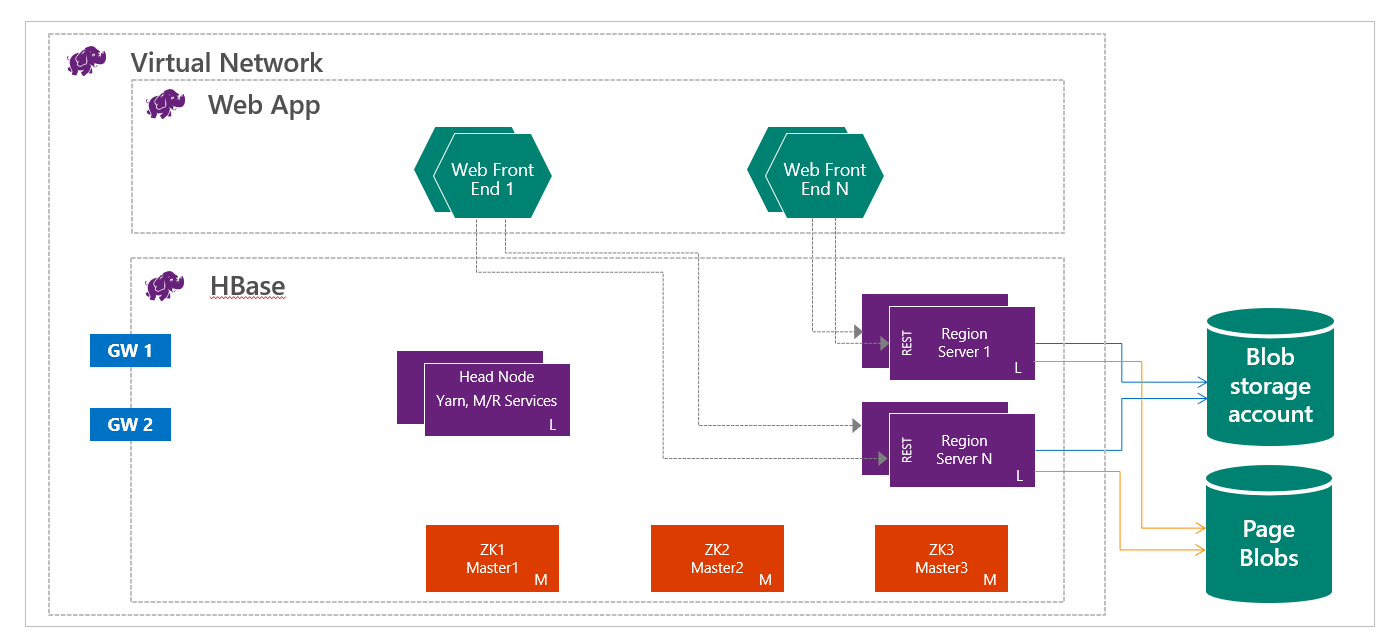
As a data engineer, you need to determine the most appropriate kind of HDInsight cluster to create in order to build your solution. You'll use HBase clusters in HDInsight for a NoSQL database that scales linearly, achieving massive amount of throughput, provides low latency reads and unlimited storage at the fraction of the cost.
The following are the key scenarios for using HBase in HDInsight.
Key-value store
HBase is typically used as a key-value store, and it's suitable for managing message systems.
Sensor data
HBase is useful for capturing data that is collected incrementally from various sources, which includes social analytics, time series, keeping interactive dashboards up to date with trends and counters, and managing audit log systems.
Real-time query
Apache Phoenix is a SQL query engine for Apache HBase. It's accessed as a JDBC driver, and it enables querying and managing HBase tables by using SQL.
HBase as a platform
Applications can run on top of HBase by using it as a datastore. Examples include Phoenix, OpenTSDB, Kiji, and Titan. Applications can also integrate with HBase. Examples include Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia, and Apache Drill.
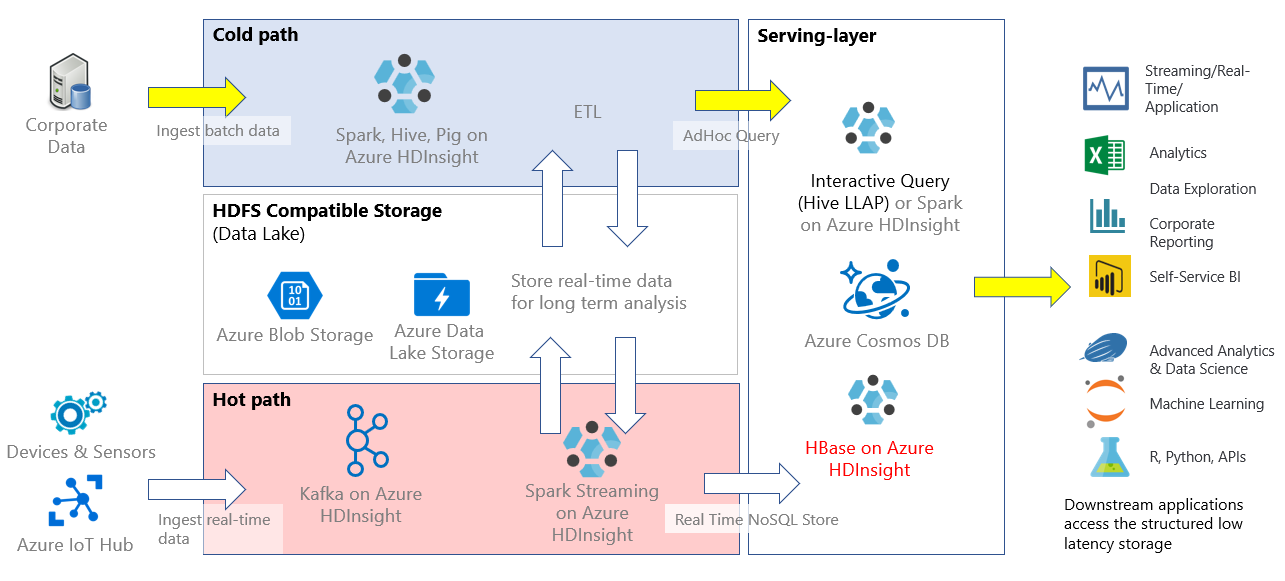
In HDInsight, HBase can be used as standalone application, or deployed along with other big data analytics applications such as Spark, Hadoop, Hive, or Kafka.
The HBase data model stores semi-structured data having different data types, varying column size and field size. The layout of the HBase data model eases data partitioning and distribution across the cluster. HBase data model consists of several logical components- row keys, column family, table name, timestamp, etc.
A Row Key is used to uniquely identify the rows in HBase tables. In HDInsight, you can either write the data to HBase directly using the multiple available APIs such as HBase REST, HBase RPC, Phoenix Query Server, HBase bulk load, or use the integration with several big data frameworks such as Apache Spark, Hive etc.
You can leverage the HBase accelerated writes feature to enable high write throughput. To learn more about HBase Architecture and best practices, refer to HBase Book.