Index any data using the Azure AI Search push API
The REST API is the most flexible way to push data into an Azure AI Search index. You can use any programming language or interactively with any app that can post JSON requests to an endpoint.
Here, you'll see how to use the REST API effectively and explore the available operations. Then you'll look at .NET Core code and see how to optimize adding large amounts of data through the API.
Supported REST API operations
There are two supported REST APIs provided by AI Search. Search and management APIs. This module focuses on the search REST APIs that provide operations on five features of search:
| Feature | Operations |
|---|---|
| Index | Create, delete, update, and configure. |
| Document | Get, add, update, and delete. |
| Indexer | Configure data sources and scheduling on limited data sources. |
| Skillset | Get, create, delete, list, and update. |
| Synonym map | Get, create, delete, list, and update. |
How to call the search REST API
If you want to call any of the search APIs you need to:
- Use the HTTPS endpoint (over the default port 443) provided by your search service, you must include an api-version in the URI.
- The request header must include an api-key attribute.
To find the endpoint, api-version, and api-key go to the Azure portal.

In the portal, navigate to your search service, then select Search explorer. The REST API endpoint is in the Request URL field. The first part of the URL is the endpoint (for example https://azsearchtest.search.windows.net), and the query string shows the api-version (for example api-version=2023-07-01-Preview).

To find the api-key on the left, select Keys. The primary or secondary admin key can be used if you're using the REST API to do more than just querying the index. If all you need is to search an index, you can create and use query keys.
To add, update, or delete data in an index you need to use an admin key.
Add data to an index
Use an HTTP POST request using the indexes feature in this format:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
The body of your request needs to let the REST endpoint know the action to take on the document, which document to apply the action too, and what data to use.
The JSON must be in this format:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Action | Description |
|---|---|
| upload | Similar to an upsert in SQL, the document will be created or replaced. |
| merge | Merge updates an existing document with the specified fields. Merge will fail if no document can be found. |
| mergeOrUpload | Merge updates an existing document with the specified fields, and uploads it if the document doesn't exist. |
| delete | Deletes the whole document, you only need to specify the key_field_name. |
If your request is successful, the API will return a 200 status code.
Note
For a full list of all the response codes and error messages, see Add, Update or Delete Documents (Azure AI Search REST API)
This example JSON uploads the customer record in the previous unit:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
You can add as many documents in the value array as you want. However, for optimal performance consider batching the documents in your requests up to a maximum of 1,000 documents, or 16 MB in total size.
Use .NET Core to index any data
For best performance use the latest Azure.Search.Document client library, currently version 11. You can install the client library with NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
How your index performs is based on six key factors:
- The search service tier and how many replicas and partitions you've enabled.
- The complexity of the index schema. Reduce how many properties (searchable, facetable, sortable) each field has.
- The number of documents in each batch, the best size will depend on the index schema and the size of documents.
- How multithreaded your approach is.
- Handling errors and throttling. Use an exponential backoff retry strategy.
- Where your data resides, try to index your data as close to your search index. For example, run uploads from inside the Azure environment.
Work out your optimal batch size
As working out the best batch size is a key factor to improve performance, let's look at an approach in code.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
The approach is to increase the batch size and monitor the time it takes to receive a valid response. The code loops from 100 to 1000, in 100 document steps. For each batch size, it outputs the document size, time to get a response, and the average time per MB. Running this code gives results like this:
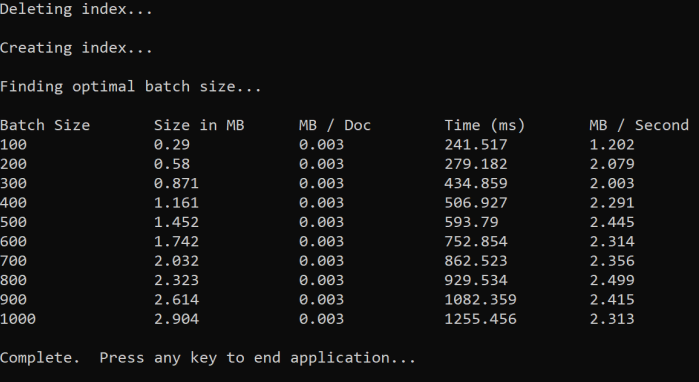
In the above example, the best batch size for throughput is 2.499 MB per second, 800 documents per batch.
Implement an exponential backoff retry strategy
If your index starts to throttle requests due to overloads, it responds with a 503 (request rejected due to heavy load) or 207 (some documents failed in the batch) status. You have to handle these responses and a good strategy is to backoff. Backing off means pausing for some time before retrying your request again. If you increase this time for each error, you'll be exponentially backing off.
Look at this code:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
The code keeps track of failed documents in a batch. If an error happens, it waits for a delay and then doubles the delay for the next error.
Finally, there's a maximum number of retries, and if this maximum number is reached the program exists.
Use threading to improve performance
You can complete your document uploading app by combing the above backoff strategy with a threading approach. Here's some example code:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
This code uses asynchronous calls to a function ExponentialBackoffAsync that implements the backoff strategy. You call the function using threads, for example, the number of cores your processor has. When the maximum number of threads has been used, the code waits for any thread to finish. It then creates a new thread until all the documents are uploaded.