Evaluate different types of clustering
Training a clustering model
There are multiple algorithms you can use for clustering. One of the most commonly used algorithms is K-Means clustering that, in its simplest form, consists of the following steps:
- The feature values are vectorized to define n-dimensional coordinates (where n is the number of features). In the flower example, we have two features: number of petals and number of leaves. So, the feature vector has two coordinates that we can use to conceptually plot the data points in two-dimensional space.
- You decide how many clusters you want to use to group the flowers - call this value k. For example, to create three clusters, you would use a k value of 3. Then k points are plotted at random coordinates. These points become the center points for each cluster, so they're called centroids.
- Each data point (in this case a flower) is assigned to its nearest centroid.
- Each centroid is moved to the center of the data points assigned to it based on the mean distance between the points.
- After the centroid is moved, the data points may now be closer to a different centroid, so the data points are reassigned to clusters based on the new closest centroid.
- The centroid movement and cluster reallocation steps are repeated until the clusters become stable or a predetermined maximum number of iterations is reached.
The following animation shows this process:

Hierarchical Clustering
Hierarchical clustering is another type of clustering algorithm in which clusters themselves belong to larger groups, which belong to even larger groups, and so on. The result is that data points can be clusters in differing degrees of precision: with a large number of very small and precise groups, or a small number of larger groups.
For example, if we apply clustering to the meanings of words, we may get a group containing adjectives specific to emotions ('angry,' 'happy,' and so on). This group belongs to a group containing all human-related adjectives ('happy,' 'handsome,' 'young'), which belongs to an even higher group containing all adjectives ('happy,' 'green,' 'handsome,' 'hard,' and so on).
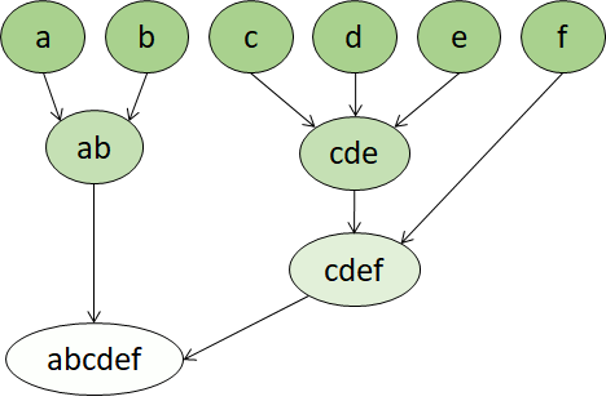
Hierarchical clustering is useful for not only breaking data into groups, but understanding the relationships between these groups. A major advantage of hierarchical clustering is that it doesn't require the number of clusters to be defined in advance. And, it can sometimes provide more interpretable results than nonhierarchical approaches. The major drawbacks are that these approaches can take longer to compute than simpler approaches, and sometimes they aren't suitable for large datasets.