Create primary and secondary keys on a table
In tables, keys are essential because you use keys to make records unique and to optimize the performance of the database when you search or filter table data.
In AL, a key definition is a sequence of one or more field IDs from a table. You can define keys in table objects and table extension objects, depending on the type of key. There are two types of keys: primary and secondary.
Primary keys
A primary key uniquely identifies each record in a table. Every table has a primary key, and there can only be one primary key per table. Primary keys are defined on table objects only. In SQL, table extension objects inherit the primary key of the table object they extend (the base table object). So any key that you define in a table extension object is considered a secondary key.
Secondary keys
Secondary keys create indexes in SQL. They're defined in both table objects and table extension objects. You can define multiple secondary keys for a single table object and table extension object.
A key in table extension object can include fields from the base table object or the table extension object.
Each table in Dynamics 365 Business Central needs a primary key. You can't have tables without keys in your application. In a table, you can have primary and secondary keys.
The primary key is always the first in the list. It's always active, and it makes records unique. You can have up to 40 keys for each table, and each key can consist of a maximum of 20 fields.
The primary key keeps track of data in a table. The primary key is composed of up to 16 fields in a record. The combination of values in fields in the primary key makes it possible to uniquely identify each record. In AL, the first key defined in a table object is the primary key. The primary key determines the logical order in which records are stored, no matter the physical placement of the fields in the table object.
Logically, records are stored sequentially in ascending order and sorted by the primary key. Before adding a new record to a table, SQL Server checks if the information in the record's primary key fields is unique. If so, it then inserts the record into the correct logical position. Records are sorted dynamically so the database is always structurally correct. This sorting allows for fast data manipulation and retrieval.
The primary key is always active. SQL Server keeps the table sorted in primary key order and rejects records with duplicate values in primary key fields. That's why the values in the primary key must always be unique. It's not the value in each field in the primary key that must be unique. Instead, it's the combination of values in all fields that make up the primary key.
Secondary keys are optional, and they can help you perform search actions faster. They might have an impact on performance because they're indexes in SQL Server. A best practice is to limit secondary keys to a maximum of three to five for each table.
In a table object, any keys defined after the primary key are called secondary keys. All keys defined in a table extension object are considered secondary keys.
A secondary key is implemented on SQL Server using a structure that is called an index. This structure is like an index that is used in textbooks. A textbook index alphabetically lists important terms at the end of a book. Next to each term are page numbers. You can quickly search the index to find a list of page numbers (addresses), and you can locate the term by searching the specified pages. The index is an exact indicator that shows where each term occurs in the textbook.
When you define a secondary key and mark it as enabled, an index is automatically maintained on SQL Server. The index reflects the sorting order that is defined by the key. Several secondary keys can be active at the same time.
A secondary key can be disabled so that it doesn't occupy database space or use time during updates to maintain its index. Disabled keys can be re-enabled, although this operation can be time-consuming because SQL Server must scan the whole table to rebuild the index.
The fields that make up the secondary keys don't always contain unique data. SQL Server doesn't reject records with duplicate data in secondary key fields. So if two or more records contain identical information in the secondary key, SQL Server uses the table's primary key to resolve this conflict.
When you look at master tables, such as Customer, Vendor, or Item, notice that the primary key is the same for every table. All master tables use the No. field as their primary key. This field is implemented with a data type of Code, meaning that the primary key values are always set in uppercase and the length is set to 20.
A primary key can also consist of more than one field. For example, the Sales Header table uses a combination of Document Type and No. fields. In the Sales Header table, you keep the quotes, invoices, orders, and so on.
The type of document is stored in the Document Type field. Because you can have the same No. for an invoice and for an order, you need a primary key that contains both fields.
Unique secondary keys
A key definition includes the Unique property that you can use to create a unique constraint on the table in SQL Server. A unique key ensures that records in a table don't have identical field values. With a unique key, when table is validated, the key value is checked for uniqueness. If the table includes records with duplicate values, the validation fails. Another benefit of unique indexes is providing information to the query optimizer that helps produce more efficient execution plans.
You can create unique secondary keys that are composed of multiple fields, like with primary keys. In this case, it's the combination of the values in the secondary key that must be unique. Consider the Customer table, for example. Suppose you wanted to make sure there are no customers that have the same combination of values for the Name, Address, and City fields. You could create a unique key for these fields.
Unlike primary keys, it's possible to define multiple unique secondary keys on a table.
There's always a unique secondary key on the SystemId field.
Secondary keys with included fields
With non-clustered secondary keys, you can use the IncludedFields property to add fields that aren't part of the key itself. In SQL server, these non-key fields correspond to what are called included columns. Using included fields lets you create indexes that cover more queries, and lets you bypass the maximum number of fields in a key.
A secondary key with included fields can improve SQL query performance, especially when SQL index contains all columns in the query, either as key columns or included columns. The performance improves because the query optimizer can locate all the column values within the index. And, it doesn't access table or clustered index data, which results in fewer disk I/O operations. For more information about included columns in SQL, see Create indexes with included columns.
Non-clustered Columnstore keys
Non-clustered columnstore indexes (sometimes referred to as NCCIs) are supported on tables.
With the ColumnStoreIndex property, you create a non-clustered columnstore index on the table in SQL server. Using a non-clustered columnstore key can improve query performance when doing analytics on large tables. This index type uses column-based data storage and query processing to achieve gains up to 10 times the query performance in analytical queries over traditional row-oriented storage. You can also achieve gains up to 10 times the data compression over the uncompressed data size on normal tables.
You can use a non-clustered columnstore index to efficiently run real-time operational analytics on the Business Central database without the need to define SIFT indexes up front (and without the locking issues that SIFT indexes sometimes impose on the system.) Whenever you would normally add a SIFT key on fields to do summation/count operations on, use a non-clustered columnstore key to add all the fields to the index instead.
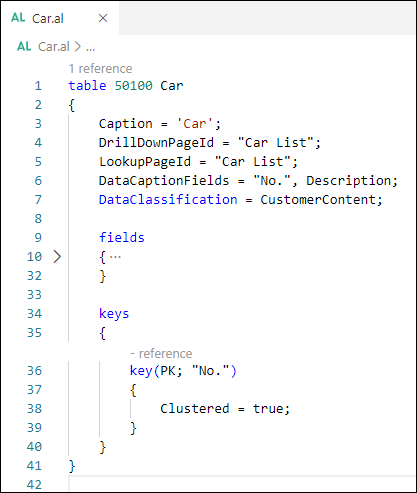
To illustrate, here's a simple example of replacing two SIFT keys with a single non-clustered columnstore index. Suppose you already have implemented two SIFT keys:
Key1: "WareHouseId, Color" SumField: "OnStock"
Key2: "WareHouseId, ItemId, Size" SumField: "OnStock"
With a non-clustered columnstore index, you could just have one index defined as: ColumnStoreIndex = WareHouseId,Color,ItemId,Size,OnStock
Clustered and non-clustered keys
A key definition includes the Clustered property that you use to create a clustered index. A clustered index determines the physical order in which records are stored in the table. Based on the key value, records are sorted in ascending order. Using a clustered key can speed up the retrieval of records.
There can be only one clustered index per table. By default the primary is configured as a clustered key.
How keys affect performance
Searching for specific data is easier if several keys are defined and maintained for the table that holds the wanted data. The indexes for each key provide specific views that enable quick and flexible searches. There are advantages and disadvantages to using many keys.
The decision whether to use a few or many keys isn't easy. The appropriate keys and the number of active keys to use is a compromise between maximizing the speed of data retrieval and data updates (operations that insert, delete, or modify data). In general, it may be worthwhile to deactivate complex keys if they're rarely used.
The overall speed depends on the following factors:
Size of the database.
Number of active keys.
Complexity of the keys.
Number of records in your tables.
Speed of your computer and its hard disk.
Indexes are an effective feature in relational databases, like SQL, to speed up the process of finding data. By indexing your frequently needed data, the overall performance of your application is optimized. For example, when you need to see some information in your application, a database query runs behind the scene to complete your request and it looks up every record until it finds the required information. This process of finding information is time consuming and slows down the application performance. However, if you index the data, like those columns that are referred more often, the database directly goes to that column instead of looking up all records in the table. This significantly increases the efficiency and overall performance of your application.
When you run a database query, the query optimizer, which is an important database component, analyzes and chooses the best possible plan to complete the instruction. In doing so, it provides additional information about the ongoing operation that the operation might perform well if the particular column (or columns) is indexed. The SQL server's Query optimizer gets this information from Dynamic Management Views (DMV), in our case, sys.dm_db_missing_index_details. It returns details about missing indexes, which helps you in creating the right indexes.
To get information on missing indexes, go to Database Missing Indexes in Business Central, and you'll see the data in the following columns:
Table Name - The name of the table on which the suggested columns are based.
Extension ID - The ID of your application to which this data is related.
Index Equality Columns - The data in these columns is based on equality queries. For example,
Select * from customer where id = 021.Index Inequality Columns - The data in these columns comes from queries, which aren't based on equality operations. For example,
Select * from customer where id < 200.Index Include Columns - These columns have a copy of associated data for fast retrieval of information, which is based on the columns suggested in Index Equality Columns and Index Inequality Columns. Include columns aren't indexed columns themselves but point to the additional information linked to the indexed columns. For example, they include the fields in the Select part.

The information provided on the Database Missing Indexes page are the suggestions and must not be taken as mandatory actions. You need to analyze where and how many indexes are best suited for optimal performance of your application. Indexes also take storage space, can affect updates for the tables where insertions and deletions are more common, and therefore can be an expensive operation if you overdo it.
Limitations and restrictions
There are some limitations and restrictions to be aware of in regards to keys.
Keys in table extension objects
In table extension objects, you can define multiple keys, just like in a table object. However, the following limitations apply:
In Business Central 2020 release wave 2 and earlier, keys in table extension objects can only include fields from the table extension object itself.
In Business Central 2021 release wave 1 and later, keys in table extension objects can include fields from the base table object and table extension object. However, a single key can't include fields from both the base table object and table extension object. In other words, each key must contain fields from either the base table object or the table extension object.
You can use the same key name in the table extension, unless the key contains fields from the base table object.
Total number of keys
Up to 40 keys can be associated with a table.
Key modifications
When developing a new version of an extension, be aware of the following restrictions to avoid schema synchronization errors that prevent you from publishing the new version:
Don't delete primary keys.
Don't add or remove primary key fields, nor change their order.
Don't change properties of existing primary keys.
Don't add more unique keys.
Don't add more clustered keys.
Don't add keys that are fields of the base table.