Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This guide helps you diagnose and resolve performance issues with the admin console in System Center 2016 Data Protection Manager (DPM 2016) and System Center 2012 Data Protection Manager (DPM 2012 or DPM 2012 R2).
Original product version: System Center 2016 Data Protection Manager, System Center 2012 Data Protection Manager, System Center 2012 R2 Data Protection Manager
This guide focuses on the most common database-related issues. If general performance issues are observed across the server as a whole, then the server may be overused. A performance monitor trace is a good place to start if you suspect server-wide performance issues. While server performance evaluation is something best left to experts, we have some general instructions for server performance analysis at Use PerfMon to diagnose common server performance problems.
In this guide, we will only look at performance issues limited to the DPM console with the assumption that the rest of the server is working normally.
Before you start troubleshooting, make sure that you have the latest update rollup package for System Center Data Protection Manager installed. Several known performance issues have been resolved in these rollup packages. For the latest version, see System Center - Data Protection Manager build versions.
Check if the DPM database is getting bloated
If the DPM database is getting bloated (larger than it should be) for any reason, it can slow down queries returning data and also cause other issues such as filling the C: drive on the DPM server with the database data files.
To check the size of DPMDB, right-click the database and select Properties:
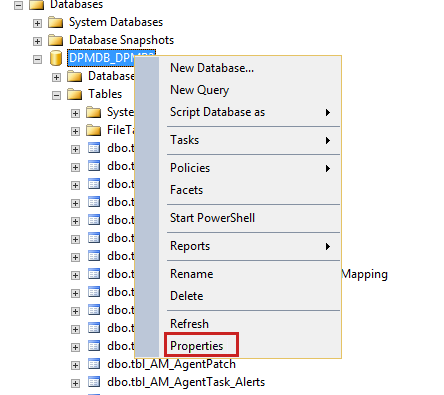
Find the size in the properties:
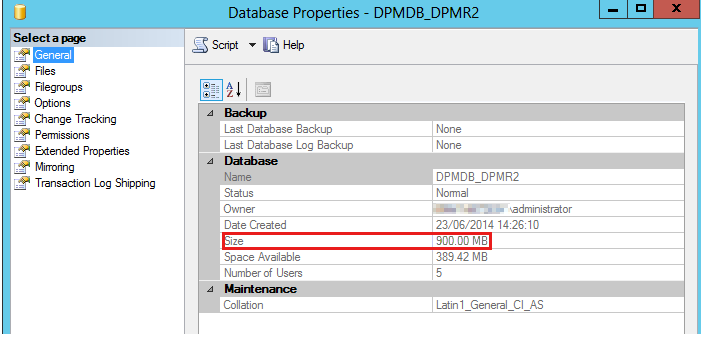
If the database is large, we need to identify which tables are responsible. Large can be fairly subjective because certain configurations such as protection of large SharePoint farms naturally leads to database growth. However, if it is causing issues with disk space or other performance issues, run the Disk Usage by Top Table report against the DPMDB database.

Based on the report, take a look at the largest tables. The following are some of the tables that are usually found to be large:
Tbl_RM_SharePointRecoverableObjectTbl_ARM_DirAndFileand/orTbl_ARM_PathTbl_TE_TaskTrail
If the database and table sizes appear normal, check the database index size and fragmentation.
The Tbl_RM_SharePointRecoverableObject table is large
This table can become large when large SharePoint farms are being protected (such as farms with millions of items) or multiple farms are protected. The following formula shows approximately how large DPMDB can get when protecting a large SharePoint farm:
((Number of items in the farm in millions) x 3) + ((number of content DBs x Number of SQL Servers in the farm x 30) / 1024) = size of DPMDB (GB)
This formula only considers the SharePoint farm related database growth. The actual size may be larger. In this scenario, there is not much you can do to reduce the disk space used. However, you can inspect the database index size and fragmentation if performance is impacted.
Check database index size and fragmentation
Large or highly fragmented indexes can cause significant performance issues for SQL queries running against them and take up more disk space than required. To check fragmentation, run the following SQL query that returns all indexes with fragmentation larger than 20%:
SELECT OBJECT_NAME(i.OBJECT_ID) AS TableName,
i.name AS IndexName,
indexstats.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') indexstats
INNER JOIN sys.indexes i ON i.OBJECT_ID = indexstats.OBJECT_ID
AND i.index_id = indexstats.index_id
WHERE indexstats.avg_fragmentation_in_percent > 20
order by TableName
If there's a large index for one or more tables, it can usually be resolved by rebuilding the index.
Run the following SQL query to rebuild an index on a particular table:
ALTER INDEX ALL ON <table_name>
rebuild
go
If there are many fragmented tables, run the following query to rebuild every index on a database:
DECLARE @TableName VARCHAR(255)
DECLARE @sql NVARCHAR(500)
DECLARE @fillfactor INT
SET @fillfactor = 80
DECLARE TableCursor CURSOR FOR
SELECT OBJECT_SCHEMA_NAME([object_id])+'.'+name AS TableName
FROM sys.tables
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @sql = 'ALTER INDEX ALL ON ' + @TableName + ' rebuild'
EXEC (@sql)
FETCH NEXT FROM TableCursor INTO @TableName
END
CLOSE TableCursor
DEALLOCATE TableCursor
GO
Running the query shouldn't affect the ability of DPM to run as usual. However, DPM may possibly run a little slower when rebuilding the index.
For more information about rebuilding indexes in DPMDB, see Improve DPM recoverable object search.
If SharePoint Catalog creation takes a long time, it is recommended to rebuild the indexes for the tbl_RM_SharePointRecoverableObject and tbl_RM_RecoverySource tables.
The Tbl_ARM_DirAndFile and/or Tbl_ARM_Path tables are large
The tape catalog pruning settings can cause these tables to be quite large. To reduce the size of these tables, modify the tape catalog retention values to reduce the data stored in DPMDB.
The default setting is to remove the entries as the tapes expire. If tapes are kept for multiple years, this can lead to a large amount of data retained in the database. In this case, change the settings to Prune catalog for tapes older than <a short period of time>. For example, set it to 4 weeks.

Updating this setting doesn't delete the data on tape. Tapes older than the specified value need to be recataloged in order to restore data from them. Make sure that you comply with any data retention policies in your organization before making any changes.
The Tbl_TE_TaskTrail table is large
If this table is growing large, the overnight jobs to clean up the database may be failing as garbage collection should clean up any data older than 33 days in the task trail table.
To check if garbage collection is working correctly, run the following SQL query:
select * from tbl_TE_TaskTrail tt where datediff (day, tt.stoppeddatetime, getutcdate()) > 33
If the result is 0, garbage collection is working correctly. Otherwise, you can use the following script to manually clean up the tables.
Important
Back up the database before you run any script against the database.
------------------------- start --------------------------
USE [DPMDB_MUKESH]
GO
select * into dbo.tbl_TE_TaskTrail1 from tbl_TE_TaskTrail where IsGCed = '0'
IF EXISTS (SELECT * FROM sys.foreign_keys WHERE object_id = OBJECT_ID(N'[dbo].[fk_TE_TaskTrail__JM_JobTrail]') AND parent_object_id = OBJECT_ID(N'[dbo].[tbl_TE_TaskTrail]'))
ALTER TABLE [dbo].[tbl_TE_TaskTrail] DROP CONSTRAINT [fk_TE_TaskTrail__JM_JobTrail]
GO
IF EXISTS (SELECT * FROM dbo.sysobjects WHERE id = OBJECT_ID(N'[DF_tbl_TE_TaskTrail_IsGCed]') AND type = 'D')
BEGIN
ALTER TABLE [dbo].[tbl_TE_TaskTrail] DROP CONSTRAINT [DF_tbl_TE_TaskTrail_IsGCed]
END
GO
USE [DPMDB_MUKESH]
GO
alter table dbo.tbl_AM_AgentDeploymentTrail DROP CONSTRAINT fk__AM_AgentDeploymentTrail__TE_TaskTrail__TaskID
alter table dbo.tbl_ARM_TaskTrail DROP CONSTRAINT fk__ARM_TaskTrail__TE_TaskTrail__TaskId
alter table dbo.tbl_CM_InquiryResult DROP CONSTRAINT fk__CM_InquiryResult__TE_Task__TaskID
alter table dbo.tbl_MM_MediaRequiredAlert DROP CONSTRAINT fk__MM_MediaRequiredAlert__TE_TaskTrail
alter table dbo.tbl_MM_Task DROP CONSTRAINT FK_tbl_MM_Task_tbl_TE_TaskTrail
alter table dbo.tbl_MM_TaskTrail DROP CONSTRAINT fk__MM_TaskTrail__TE_TaskTrail__TaskId
alter table dbo.tbl_PRM_CloudRecoveryPointTrail DROP CONSTRAINT fk_PRM_CloudRecoveryPointTrail
alter table dbo.tbl_PRM_ReferencedTaskTrail DROP CONSTRAINT fk__PRM_ReferentialTask_TaskTrail_TaskId
alter table dbo.tbl_RM_CandidateDatasetsForSCAssociation DROP CONSTRAINT fk_RM_CandidateDatasetsForSCAssociation_RM_TaskTrail
alter table dbo.tbl_RM_RecoveryTrail DROP CONSTRAINT fk__RM_RecoveryTrail__TE_TaskTrail__TaskId
alter table dbo.tbl_RM_ReplicaTrail DROP CONSTRAINT fk_RM_ReplicaTrail__TE_Task
alter table dbo.tbl_RM_ShadowCopyTrail DROP CONSTRAINT fk_RM_ShadowCopyTrail__TE_Task
alter table dbo.tbl_TE_TaskError DROP CONSTRAINT FK_tbl_TE_TaskError_tbl_TE_TaskTrail
/****** Object: Table [dbo].[tbl_TE_TaskTrail] Script Date: 07/18/2011 00:25:30 ******/
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[tbl_TE_TaskTrail]') AND type in (N'U'))
DROP TABLE [dbo].[tbl_TE_TaskTrail]
GO
USE [DPMDB_MUKESH]
GO
/****** Object: Table [dbo].[tbl_TE_TaskTrail] Script Date: 07/18/2011 00:25:30 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[tbl_TE_TaskTrail](
[TaskID] [dbo].[GUID] NOT NULL,
[TaskDefinitionID] [dbo].[GUID] NOT NULL,
[JobID] [dbo].[GUID] NOT NULL,
[VerbID] [dbo].[GUID] NOT NULL,
[ExecutionState] [smallint] NOT NULL,
[ErrorCode] [int] NOT NULL,
[ErrorDetailsXml] [ntext] NOT NULL,
[LastStateName] [nvarchar](128) NULL,
[CreatedDateTime] [datetime] NOT NULL,
[StartedDateTime] [datetime] NULL,
[StoppedDateTime] [datetime] NULL,
[TaskXml] [ntext] NOT NULL,
[ErrorStateName] [nvarchar](128) NULL,
[IsGCed] [bit] NOT NULL,
CONSTRAINT [pk_TE_TaskTrail] PRIMARY KEY NONCLUSTERED
(
[TaskID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
insert into tbl_TE_TaskTrail select * from tbl_te_tasktrail1
ALTER TABLE [dbo].[tbl_TE_TaskTrail] WITH CHECK ADD CONSTRAINT [fk_TE_TaskTrail__JM_JobTrail] FOREIGN KEY([JobID])
REFERENCES [dbo].[tbl_JM_JobTrail] ([JobId])
GO
ALTER TABLE [dbo].[tbl_TE_TaskTrail] CHECK CONSTRAINT [fk_TE_TaskTrail__JM_JobTrail]
GO
ALTER TABLE [dbo].[tbl_TE_TaskTrail] ADD CONSTRAINT [DF_tbl_TE_TaskTrail_IsGCed] DEFAULT ((0)) FOR [IsGCed]
GO
alter table dbo.tbl_AM_AgentDeploymentTrail ADD CONSTRAINT fk__AM_AgentDeploymentTrail__TE_TaskTrail__TaskID foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_ARM_TaskTrail ADD CONSTRAINT fk__ARM_TaskTrail__TE_TaskTrail__TaskId foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_CM_InquiryResult ADD CONSTRAINT fk__CM_InquiryResult__TE_Task__TaskID foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_MM_MediaRequiredAlert ADD CONSTRAINT fk__MM_MediaRequiredAlert__TE_TaskTrail foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_MM_Task ADD CONSTRAINT FK_tbl_MM_Task_tbl_TE_TaskTrail foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_MM_TaskTrail ADD CONSTRAINT fk__MM_TaskTrail__TE_TaskTrail__TaskId foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_PRM_CloudRecoveryPointTrail ADD CONSTRAINT fk_PRM_CloudRecoveryPointTrail foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_PRM_ReferencedTaskTrail ADD CONSTRAINT fk__PRM_ReferentialTask_TaskTrail_TaskId foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_RM_CandidateDatasetsForSCAssociation ADD CONSTRAINT fk_RM_CandidateDatasetsForSCAssociation_RM_TaskTrail foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_RM_RecoveryTrail ADD CONSTRAINT fk__RM_RecoveryTrail__TE_TaskTrail__TaskId foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_RM_ReplicaTrail ADD CONSTRAINT fk_RM_ReplicaTrail__TE_Task foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_RM_ShadowCopyTrail ADD CONSTRAINT fk_RM_ShadowCopyTrail__TE_Task foreign key (taskid) references tbl_te_tasktrail (taskid)
alter table dbo.tbl_TE_TaskError ADD CONSTRAINT FK_tbl_TE_TaskError_tbl_TE_TaskTrail foreign key (taskid) references tbl_te_tasktrail (taskid)
DROP TABLE [dbo].[tbl_TE_TaskTrail1]
GO
Tempdb is getting bloated
This is not as common as bloating of the DPMDB, but it can cause some performance-related issues.
For more information about tempdb, see tempdb Database.
When you have a query working with a large amount of data, tempdb grows. However, if tempdb grows by several GB, it's usually caused by a long running transaction. This can prevent cleanup of the transaction log and causes it to continue growing until the transaction completes, or indefinitely if the transaction never completes.
If other databases are colocated on the same SQL Server instance, it may cause a problem with tempdb and affect the DPM console performance.
To verify if this is a problem with tempdb, open tempdb properties in SQL Server Management Studio:

If the size of tempdb is in GB, there may be a problem. You can also see if there's any Space Available in tempdb. If so, it is unlikely that whatever caused the growth is currently happening.
Note
It's impossible to enable AutoShrink with tempdb. If AutoGrow is enabled, once tempdb grows to a large size, it won't drop back in size. For more information about AutoShrink and AutoGrow, see Considerations for the "autogrow" and "autoshrink" settings in SQL Server.
There is free space available in tempdb
From the SQL Server Management Studio, try to shrink the tempdb size:
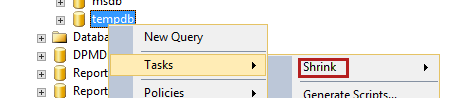
If the size doesn't decrease as much as expected, check the Initial Size:

If it's set to a very large value, drop it back to 8 MB and try to shrink tempdb again. Restarting the SQL Server instance also resets the tempdb size back to its initial size.
There is no free space in tempdb and the size still grows
In this case, it is likely the problematic query is still running. If it is causing an urgent issue such as consuming all available disk space, restart the SQL Server instance. However, this temporary relief makes it harder to identify the cause of the problem.
If the issue is caused by a long running query, the following query shows the longest running transactions:
SELECT transaction_id, session_id, elapsed_time_seconds FROM sys.dm_tran_active_snapshot_database_transactions ORDER BY elapsed_time_seconds DESC;
Here is a sample output:

Used together with a SQL Server Profiler trace, you should be able to work out what's happening in the session by filtering on that session_id:

You can find which database the query is running against and see the content of the query in the details pane. Check if the database is DPMDB. If not, then it's another application that is causing the issue and you have to troubleshoot that application.
If the query is running against DPMDB, check what the query does. If it's calling a stored procedure, take a closer look at the stored procedure. To do this, open SQL Server Management Studio and locate the procedure under DPMDB > Programmability > Stored Procedures. Right-click the stored procedure to see more details. Clicking Modify will allow you to see the actual query. Take a look at the tables that are selecting from (or updating) to check if they have any problems.
While it's beyond the scope of this guide to resolve complex table and query issues, this should help pinpoint where the problem may reside. For more information, consult your local SQL Server expert or search on the DPM support forum.
Important
Before making any changes, make sure that you back up DPMDB.