Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This document presents information that will help font developers create or support OpenType fonts for the Korean Hangul script covered by the Unicode Standard.
Introduction
The Korean Hangul script is a 'syllabic' script. The syllables are formed by combining sequences of elemental, alphabetic consonants and vowels. The process of composing syllables is additive in nature and follows a set of predefined rules. The glyph elements of each composed syllable are shaped and positioned into a square display cell, often referred to as a 'syllable block', or 'syllable glyph'.
The Unicode Standard provides encodings for pre-composed Hangul syllables known as 'Modern Hangul', as well as encodings for individual Hangul alphabetic elements, called 'Jamo' and known as 'Old Hangul'. 'Modern Hangul' has 11,172 pre-composed characters in the Unicode range U+AC00 through U+D7AF. 'Old Hangul' syllables can be composed from the individual Hangul Jamos encoded in the Unicode Hangul Jamo block (U+1100 through U+11FF). More specifically, only certain sequences of these Jamo characters can combine to form Old Hangul syllables. These sequences are defined in Appendix B. Only sequences defined in Appendix B will result in formation of Old Hangul syllables. Sequences of character codes from the Hangul Jamo Block that do not match any sequence pattern in Appendix B, will be considered as a sequence of individual non-Old Hangul characters.
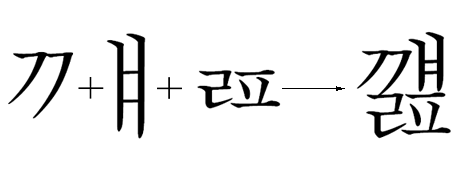
In this specification, font developers will learn how to address Old Hangul syllable formation, encode complex script features in their fonts, choose character sets, organize font information, and use existing tools to produce Old Hangul fonts. Registered features of the Korean Hangul script are defined and illustrated, encodings are listed, and templates are included for compiling Korean Hangul layout tables for OpenType fonts.
This document also presents information about the Korean OpenType shaping engine of Uniscribe, the Windows component responsible for text layout.
In addition to being a primer and specification for the creation and support of Hangul fonts, this document is intended to more broadly illustrate the OpenType Layout architecture, feature schemes, and operating system support for shaping and positioning text.
Glossary
The following terms are useful for understanding the layout features and script rules discussed in this document.
Jamo - Individual Hangul alphabetic elements or atomic unit in a syllable. Consonants and vowels are both known as Jamos.
Consonant - Represents a single consonant sound. Consonants are further divided into leading consonants and trailing consonants.
- Leading consonant (Leading Jamo) "Choseong" - the syllable initial character
- Trailing Consonant (Trailing Jamo) "Jongseong" - the syllable final character
Vowel (Vowel Jamo) "Jungseong" - A phoneme; an independent unit in a syllable. It does not combine with any consonant to result in the transformation of any consonant-vowel combination.
Notation
The following notation is used in this document to illustrate layout operations:
L – Leading consonant
V – Vowel
T – Trailing consonant
S – Syllable
X – Non-Jamo character
{ } – Indicates 0, 1 or multiple occurrence
[ ] – Indicates 0 or 1 occurrence
() – Indicates 1 or multiple occurrence
Shaping Engine
- Compose Old Hangul Jamo Combinations
- Analyze the Syllables
- Shape Glyphs with OTLS
- Handling Invalid Combining Marks
The Uniscribe Korean shaping engine processes text in stages. The stages are:
- Compose Old Hangul Jamo combinations
- Identify syllable boundaries with OTLS
- Analyze the syllables
- Shape glyphs with OTLS (OpenType Library Services)
The descriptions which follow will help font developers understand the rationale for the Korean Hangul feature encoding model, and help application developers better understand how layout clients can divide responsibilities with operating system functions.
Compose Old Hangul Jamo combinations
The shaping engine receives a sequence of characters (character run), which have been identified into sequences of leading consonant (L), vowel (V) and trailing consonant (T) Jamos. In each of these sequences, the shaping engine identifies the maximum length of characters which can combine to form registered Jamos. This is done according to the list of standard character combinations in Appendix B.
Next, it replaces these with the corresponding old Hangul Jamo. This process is repeated on the next longest string in the sequence. This process of identification and replacement is repeated for all sequences.
The result of this process is a string of registered Old Hangul Jamos like the example below:
V1L1L2L3V2V3T1T2T3L4L5V4T4V5V6L6V7
---> V1L1(L2L3)V2V3(T1T2T3)L4L5V4T4(V5V6)L6V7
---> V1L1(L23)V2V3(T123)L4L5V4T4(V56)L6V7
Analyze the Syllables
The syllable unit that the shaping engine receives for the purpose of shaping is a string of Unicode characters, in a sequence. Since each Hangul syllable has the canonical format of LVT, fillers Lf and Vf, are then added, where required, in the registered Jamo sequence to convert each of them to canonical form. The shaping engine then flags each of these for appropriate feature processing. OTLS will then be called to perform OpenType layout processing for each syllable in turn.
It is important to note that if any of the Jamo sequences being analyzed is capable of forming a Modern Hangul Syllable, the shaping engine does not apply OpenType features to shape them. Composition of Modern Hangul syllables is expected to be done using the pre-composed section (U+AC00 – U+D7AF), as described in the Unicode Standard.
Shaping with OTLS
The first step Uniscribe takes in shaping the character string is to map all characters to their nominal form glyphs.
Next, Uniscribe calls the OTL Services Library to shape the Old Hangul syllable. All OTL processing is divided into a set of predefined features (described and illustrated in the Features section of this document). Each feature is applied, one by one, to the appropriate glyphs in the syllable and OTLS processes them. Uniscribe makes as many calls to the OTL Services as there are features. This ensures that the features are executed in the desired order.
The steps of the shaping process are outlined below.
Shaping features:
- Language forms
- Apply feature 'ccmp' to preprocess any glyphs that require composition
- Apply feature 'ljmo' to get the leading consonant Jamo
- Apply feature 'vjmo' to get the vowel Jamo
- Apply feature 'tjmo' to get the trailing consonant Jamo
Handling Invalid Combining Marks
Combining marks and signs that appear in text not in conjunction with a valid consonant base are considered invalid. When an invalid combination of letters is encountered, Uniscribe simply starts a new syllable/cluster.
Please note that to render a sign standalone (in apparent isolation from any base) one should apply it on a space (see section 2.5 'Combining Marks' of Unicode Standard 3.1). Uniscribe requires a ZWJ to be placed between the space and a mark for them to combine into a standalone sign.

While not required for OpenType functionality, inclusion of the ZWJ (zero width joiner; U+200C), the ZWNJ (zero width non-joiner; U+200D) and the ZWSP (zero width space; U+200B) are recommended for inclusion in Korean Hangul fonts.
Features
The features listed below have been defined to create the basic forms for the languages that are supported on Korean Hangul systems. Regardless of the model an application chooses for supporting layout of complex scripts, Uniscribe requires a fixed order for executing features within a run of text to consistently obtain the proper basic form. This is achieved by calling features one-by-one in the standard order listed below.
The order of the lookups within each feature is also very important. For more information on lookups and defining features in OpenType fonts, see the Encoding section of the OpenType Development document.
The standard order for applying Korean Hangul features encoded in OpenType fonts:
| Feature | Feature function | Layout operation | Required |
|---|---|---|---|
| Language based forms: | |||
| ccmp | Character composition/decomposition substitution | GSUB | |
| ljmo | Leading consonant Jamo | GSUB | X |
| vjmo | Vowel Jamo | GSUB | X |
| tjmo | Trailing consonant Jamo | GSUB | X |
| [GSUB = glyph substitution, GPOS = glyph positioning] | |||
Descriptions and examples of above features
Character composition (and decomposition)
Feature Tag: "ccmp"
The 'ccmp' feature is used to compose a number of glyphs into one glyph (GSUB lookup type 4). This feature is implemented before any other features because there may be times when a font vender wants to control certain shaping of glyphs.
This feature permits the composition of Old Hangul Jamos corresponding to sequences described in Appendix B. To compose Old Hangul syllables, these Jamo glyphs are then substituted to the appropriate form using the 'ljmo', 'vjmo' and 'tjmo' features. The 'ccmp' feature should be implemented before any other feature, so that these actions are given topmost priority. It is applicable to each of: Leading, Vowel and Trailing Jamo sequences.
For example: the below sequence (U1107 + U1109 + U1110) of leading Jamos composed with the 'ccmp' feature.

Leading consonant Jamo
Feature Tag: "ljmo"
The 'ljmo' feature is used to substitute the correct shape of a leading consonant Jamo for a Hangul syllable. The shaping of leading consonant Jamos is context based and depends on whether the leading Jamo is followed by a vowel Jamo alone or a sequence of vowel and trailing Jamo.
For example: the leading Jamo (U1113) is replaced by the correct leading form when followed by a vowel Jamo alone.
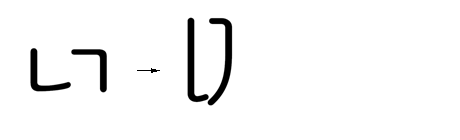
Vowel Jamo
Feature Tag: "vjmo"
The 'vjmo' feature is used to substitute the correct shape of a vowel Jamo for a Hangul syllable. The shaping of vowel Jamos is context based and depends on whether it is preceded by a leading Jamo alone, or a leading Jamo and followed by a trailing Jamo.
For example: the Hangul vowel Jungseong AE (U1162) is replaced by the correct form when preceded by a leading Jamo alone.

Trailing consonant Jamo
Feature Tag: "tjmo"
The 'tjmo' feature is used to substitute the correct shape of a trailing consonant Jamo for a Hangul syllable. The shaping of trailing consonant Jamos is context based and depends on whether the trailing Jamo is preceded by a leading Jamo filler and vowel Jamo or by a leading Jamo and vowel Jamo.
For example: U11C7 is replaced by the correct trailing consonant when preceded by a leading Jamo and vowel Jamo.

More Examples
1. Old Hangul Jamo containing leading consonants, vowels and trailing Jamos.
Input sequence: This sequence consists of: Choseong Pieup, Choseong Sios, Choseong Thieuth, Jungseong O, Jungseong Ya, Jungseong I, Jongseong Rieul, Jongseong Mieum, Jongseong Hieuh.

'ccmp' feature applied:
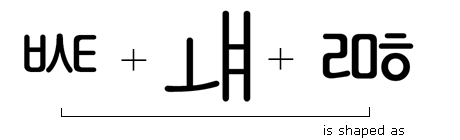
'ljmo', 'vjmo' and 'tjmo' features applied:

2. Leading consonant Jamo + vowel Jamo + trailing Jamo.
Input sequence: This sequence consists of: Choseong Ssangkiyeok, Jungseong A, Jongseong Nieun-Sios.

'ljmo', 'vjmo' and 'tjmo' features applied:

3. Leading consonant Jamo + vowel Jamo
Input sequence: This sequence consists of: Choseong Nieun-Kiyeok, Jungseong Ae.

'ljmo' and 'vjmo' features applied:

Appendices
Appendix A: Writing System Tags
Features are encoded according to both a designated script and language system. The language system tag specifies a typographic convention associated with a language or linguistic subgroup.
Currently, the Uniscribe engine only supports the "default" language for each script. However, font developers may want to build language specific features which are supported in other applications and will be supported in future Microsoft OpenType implementations.
- NOTE: It is strongly recommended to include the "dflt" language tag in all OpenType fonts because it defines the basic script handling for a font. The "dflt" language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the "dflt" tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts and language systems.
| Registered tags for the Korean Hangul script | Registered tags for Korean Hangul language systems | ||
|---|---|---|---|
| Script tag | Script | Language system tag | Language |
| "hang" | Korean Hangul | "dflt" | *default script handling |
| "KOR " | Korean | ||
Note: both the script and language tags are case sensitive (script tags should be lowercase, language tags are all caps) and must contain four characters (ie. you must add a space to the three character language tags).
Appendix B: Standard Composition for Old Hangul Jamos
| Leading Consonants | |||||||
|---|---|---|---|---|---|---|---|
| Code point | Glyph | Code point | Glyph | Code point | Glyph | ||
| U+115F | |||||||
| U+1100 |  |
||||||
| U+1101 | 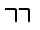 |
||||||
| U+1102 |  |
||||||
| U+1113 |  |
||||||
| U+1114 |  |
||||||
| U+1115 |  |
||||||
| U+1116 |  |
||||||
| U+1102 | |
+ | U+1109 | 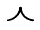 |
|||
| U+1102 | |
+ | U+110C |  |
|||
| U+1102 | |
+ | U+1112 |  |
|||
| U+1103 |  |
||||||
| U+1117 |  |
||||||
| U+1104 |  |
||||||
| U+1103 | |
+ | U+1105 |  |
|||
| U+1103 | |
+ | U+1106 |  |
|||
| U+1103 | |
+ | U+1107 | 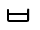 |
|||
| U+1103 | |
+ | U+1109 | |
|||
| U+1103 | |
+ | U+110C | |
|||
| U+1105 | |
||||||
| U+1105 | |
+ | U+1100 | |
|||
| U+1105 | |
+ | U+1100 | |
+ | U+1100 | |
| U+1118 |  |
||||||
| U+1105 | |
+ | U+1103 | |
|||
| U+1105 | |
+ | U+1103 | |
+ | U+1103 | |
| U+1119 |  |
||||||
| U+1105 | |
+ | U+1106 | |
|||
| U+1105 | |
+ | U+1107 | |
|||
| U+1105 | |
+ | U+1107 | |
+ | U+1107 | |
| U+1105 | |
+ | U+112B |  |
|||
| U+1105 | |
+ | U+1109 | |
|||
| U+1105 | |
+ | U+110C | |
|||
| U+1105 | |
+ | U+110F |  |
|||
| U+111A |  |
||||||
| U+111B |  |
||||||
| U+1106 | |
||||||
| U+1106 | |
+ | U+1100 | |
|||
| U+1106 | |
+ | U+1103 | |
|||
| U+111C |  |
||||||
| U+1106 | |
+ | U+1109 | |
|||
| U+111D |  |
||||||
| U+1107 | |
||||||
| U+111E |  |
||||||
| U+111F |  |
||||||
| U+1120 |  |
||||||
| U+1108 |  |
||||||
| U+1121 |  |
||||||
| U+1122 |  |
||||||
| U+1123 |  |
||||||
| U+1124 |  |
||||||
| U+1125 |  |
||||||
| U+1126 |  |
||||||
| U+1107 | |
+ | U+1109 | |
+ | U+1110 |  |
| U+1127 |  |
||||||
| U+1128 |  |
||||||
| U+1107 | |
+ | U+110F | |
|||
| U+1129 |  |
||||||
| U+112A |  |
||||||
| U+1107 | |
+ | U+1112 | |
|||
| U+112B | |
||||||
| U+112C |  |
||||||
| U+1109 | |
||||||
| U+112D |  |
||||||
| U+112E |  |
||||||
| U+112F |  |
||||||
| U+1130 |  |
||||||
| U+1131 |  |
||||||
| U+1132 |  |
||||||
| U+1133 |  |
||||||
| U+110A |  |
||||||
| U+1109 | |
+ | U+1109 | |
+ | U+1107 | |
| U+1134 |  |
||||||
| U+1135 |  |
||||||
| U+1136 |  |
||||||
| U+1137 | 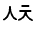 |
||||||
| U+1138 |  |
||||||
| U+1139 |  |
||||||
| U+113A |  |
||||||
| U+113B |  |
||||||
| U+113C |  |
||||||
| U+113D |  |
||||||
| U+113E | 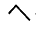 |
||||||
| U+113F |  |
||||||
| U+1140 |  |
||||||
| U+110B |  |
||||||
| U+1141 | 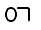 |
||||||
| U+1142 |  |
||||||
| U+110B | |
+ | U+1105 | |
|||
| U+1143 | 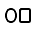 |
||||||
| U+1144 |  |
||||||
| U+1145 |  |
||||||
| U+1146 | 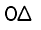 |
||||||
| U+1147 |  |
||||||
| U+1148 |  |
||||||
| U+1149 |  |
||||||
| U+114A |  |
||||||
| U+114B |  |
||||||
| U+110B | |
+ | U+1112 | |
|||
| U+114C |  |
||||||
| U+110C | |
||||||
| U+114D |  |
||||||
| U+110D |  |
||||||
| U+110C | |
+ | U+110C | |
+ | U+1112 | |
| U+114E |  |
||||||
| U+114F |  |
||||||
| U+1150 |  |
||||||
| U+1151 |  |
||||||
| U+110E |  |
||||||
| U+1152 |  |
||||||
| U+1153 |  |
||||||
| U+1154 |  |
||||||
| U+1155 |  |
||||||
| U+110F | |
||||||
| U+1110 | |
||||||
| U+1110 | |
+ | U+1110 | |
|||
| U+1111 |  |
||||||
| U+1156 |  |
||||||
| U+1111 | |
+ | U+1112 | |
|||
| U+1157 |  |
||||||
| U+1112 | |
||||||
| U+1112 | |
+ | U+1109 | |
|||
| U+1158 |  |
||||||
| U+1159 |  |
||||||
| U+1159 | |
+ | U+1159 | |
|||
| Vowels | |||||||
|---|---|---|---|---|---|---|---|
| Code point | Glyph | Code point | Glyph | Code point | Glyph | ||
| U+1160 | |||||||
| U+1161 |  |
||||||
| U+1176 |  |
||||||
| U+1177 | 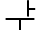 |
||||||
| U+1161 | |
+ | U+1173 |  |
|||
| U+1162 |  |
||||||
| U+1163 |  |
||||||
| U+1178 |  |
||||||
| U+1179 |  |
||||||
| U+1163 | |
+ | U+116E |  |
|||
| U+1164 |  |
||||||
| U+1165 |  |
||||||
| U+117A |  |
||||||
| U+117B |  |
||||||
| U+117C | 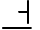 |
||||||
| U+1166 |  |
||||||
| U+1167 |  |
||||||
| U+1167 | |
+ | U+1163 | |
|||
| U+117D |  |
||||||
| U+117E |  |
||||||
| U+1168 |  |
||||||
| U+1169 |  |
||||||
| U+116A |  |
||||||
| U+116B |  |
||||||
| U+1169 | |
+ | U+1163 | |
|||
| U+1169 | |
+ | U+1163 | |
+ | U+1175 |  |
| U+117F |  |
||||||
| U+1180 |  |
||||||
| U+1169 | |
+ | U+1167 | |
|||
| U+1181 |  |
||||||
| U+1182 |  |
||||||
| U+1169 | |
+ | U+1169 | |
+ | U+1175 | |
| U+1183 |  |
||||||
| U+116C |  |
||||||
| U+116D |  |
||||||
| U+116D | |
+ | U+1161 | |
|||
| U+116D | |
+ | U+1161 | |
+ | U+1175 | |
| U+1184 |  |
||||||
| U+1185 |  |
||||||
| U+116D | |
+ | U+1165 | |
|||
| U+1186 |  |
||||||
| U+1187 |  |
||||||
| U+1188 |  |
||||||
| U+116E | |
||||||
| U+1189 |  |
||||||
| U+118A |  |
||||||
| U+116F |  |
||||||
| U+118B |  |
||||||
| U+1170 |  |
||||||
| U+116E | |
+ | U+1167 | |
|||
| U+118C |  |
||||||
| U+118D |  |
||||||
| U+1171 |  |
||||||
| U+116E | |
+ | U+1175 | |
+ | U+1175 | |
| U+1172 |  |
||||||
| U+118E |  |
||||||
| U+1172 | |
+ | U+1161 | |
+ | U+1175 | |
| U+118F |  |
||||||
| U+1190 | 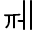 |
||||||
| U+1191 |  |
||||||
| U+1192 |  |
||||||
| U+1172 | |
+ | U+1169 | |
|||
| U+1193 |  |
||||||
| U+1194 |  |
||||||
| U+1173 | |
||||||
| U+1173 | |
+ | U+1161 | |
|||
| U+1173 | |
+ | U+1165 | |
|||
| U+1173 | |
+ | U+1165 | |
+ | U+1175 | |
| U+1173 | |
+ | U+1169 | |
|||
| U+1195 |  |
||||||
| U+1196 | 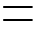 |
||||||
| U+1174 |  |
||||||
| U+1197 |  |
||||||
| U+1175 | |
||||||
| U+1198 |  |
||||||
| U+1199 |  |
||||||
| U+1175 | |
+ | U+1163 | |
+ | U+1169 | |
| U+1175 | |
+ | U+1163 | |
+ | U+1175 | |
| U+1175 | |
+ | U+1167 | |
|||
| U+1175 | |
+ | U+1167 | |
+ | U+1175 | |
| U+119A | 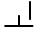 |
||||||
| U+1175 | |
+ | U+1169 | |
+ | U+1175 | |
| U+1175 | |
+ | U+116D | |
|||
| U+119B |  |
||||||
| U+1175 | |
+ | U+1172 | |
|||
| U+119C |  |
||||||
| U+1175 | |
+ | U+1175 | |
|||
| U+119D |  |
||||||
| U+119E |  |
||||||
| U+119E | |
+ | U+1161 | |
|||
| U+119F |  |
||||||
| U+119E | |
+ | U+1165 | |
+ | U+1175 | |
| U+11A0 |  |
||||||
| U+11A1 |  |
||||||
| U+11A2 |  |
||||||
| **Trailing Consonants** | |||||||
|---|---|---|---|---|---|---|---|
| Code point | Glyph | Code point | Glyph | Code point | Glyph | ||
| U+11A8 |  |
||||||
| U+11A9 |  |
||||||
| U+11A8 | |
+ | U+11AB |  |
|||
| U+11C3 |  |
||||||
| U+11A8 | |
+ | U+11B8 |  |
|||
| U+11AA |  |
||||||
| U+11C4 |  |
||||||
| U+11A8 | |
+ | U+11BE |  |
|||
| U+11A8 | |
+ | U+11BF |  |
|||
| U+11A8 | |
+ | U+11C2 |  |
|||
| U+11AB | |
||||||
| U+11C5 |  |
||||||
| U+11AB | |
+ | U+11AB | |
|||
| U+11C6 |  |
||||||
| U+11AB | |
+ | U+11AF |  |
|||
| U+11C7 |  |
||||||
| U+11C8 |  |
||||||
| U+11AC |  |
||||||
| U+11AB | |
+ | U+11BE | |
|||
| U+11C9 |  |
||||||
| U+11AD |  |
||||||
| U+11AE |  |
||||||
| U+11CA |  |
||||||
| U+11AE | |
+ | U+11AE | |
|||
| U+11AE | |
+ | U+11AE | |
+ | U+11B8 | |
| U+11CB |  |
||||||
| U+11AE | |
+ | U+11B8 | |
|||
| U+11AE | |
+ | U+11BA |  |
|||
| U+11AE | |
+ | U+11BA | |
+ | U+11A8 | |
| U+11AE | |
+ | U+11BD |  |
|||
| U+11AE | |
+ | U+11BE | |
|||
| U+11AE | |
+ | U+11C0 |  |
|||
| U+11AF | |
||||||
| U+11B0 |  |
||||||
| U+11AF | |
+ | U+11A8 | |
+ | U+11A8 | |
| U+11CC |  |
||||||
| U+11AF | |
+ | U+11A8 | |
+ | U+11C2 | |
| U+11CD |  |
||||||
| U+11CE |  |
||||||
| U+11CF |  |
||||||
| U+11D0 |  |
||||||
| U+11AF | |
+ | U+11AF | |
+ | U+11BF | |
| U+11B1 |  |
||||||
| U+11D1 |  |
||||||
| U+11D2 |  |
||||||
| U+11AF | |
+ | U+11B7 |  |
+ | U+11C2 | |
| U+11B2 | 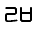 |
||||||
| U+11AF | |
+ | U+11B8 | |
+ | U+11AE | |
| U+11D3 |  |
||||||
| U+11AF | |
+ | U+11B8 | |
+ | U+11C1 | 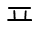 |
| U+11D4 |  |
||||||
| U+11D5 |  |
||||||
| U+11B3 |  |
||||||
| U+11D6 |  |
||||||
| U+11D7 |  |
||||||
| U+11AF | |
+ | U+11F0 |  |
|||
| U+11D8 |  |
||||||
| U+11B4 |  |
||||||
| U+11B5 |  |
||||||
| U+11B6 |  |
||||||
| U+11D9 |  |
||||||
| U+11AF | |
+ | U+11F9 |  |
+ | U+11C2 | |
| U+11AF | |
+ | U+11BC |  |
|||
| U+11B7 | |
||||||
| U+11DA |  |
||||||
| U+11B7 | |
+ | U+11AB | |
|||
| U+11B7 | |
+ | U+11AB | |
+ | U+11AB | |
| U+11DB |  |
||||||
| U+11B7 | |
+ | U+11B7 | |
|||
| U+11DC |  |
||||||
| U+11B7 | |
+ | U+11B8 | |
+ | U+11BA | |
| U+11DD |  |
||||||
| U+11DE |  |
||||||
| U+11DF |  |
||||||
| U+11B7 | |
+ | U+11BD | |
|||
| U+11E0 |  |
||||||
| U+11E1 |  |
||||||
| U+11E2 |  |
||||||
| U+11B8 | |
||||||
| U+11B8 | |
+ | U+11AE | |
|||
| U+11E3 |  |
||||||
| U+11B8 | |
+ | U+11AF | |
+ | U+11C1 | |
| U+11B8 | |
+ | U+11B7 | |
|||
| U+11B8 | |
+ | U+11B8 | |
|||
| U+11B9 |  |
||||||
| U+11B8 | |
+ | U+11BA | |
+ | U+11AE | |
| U+11B8 | |
+ | U+11BD | |
|||
| U+11B8 | |
+ | U+11BE | |
|||
| U+11E4 |  |
||||||
| U+11E5 |  |
||||||
| U+11E6 |  |
||||||
| U+11BA | |
||||||
| U+11E7 |  |
||||||
| U+11E8 |  |
||||||
| U+11E9 |  |
||||||
| U+11BA | |
+ | U+11B7 | |
|||
| U+11EA |  |
||||||
| U+11BA | |
+ | U+11E6 | |
|||
| U+11BB |  |
||||||
| U+11BA | |
+ | U+11BA | |
+ | U+11A8 | |
| U+11BA | |
+ | U+11BA | |
+ | U+11AE | |
| U+11BA | |
+ | U+11EB |  |
|||
| U+11BA | |
+ | U+11BD | |
|||
| U+11BA | |
+ | U+11BE | |
|||
| U+11BA | |
+ | U+11C0 | |
|||
| U+11BA | |
+ | U+11C2 | |
|||
| U+11EB | |
||||||
| U+11EB | |
+ | U+11B8 | |
|||
| U+11EB | |
+ | U+11E6 | |
|||
| U+11BC | |
||||||
| U+11EC |  |
||||||
| U+11ED |  |
||||||
| U+11BC | |
+ | U+11B7 | |
|||
| U+11BC | |
+ | U+11BA | |
|||
| U+11EE | 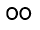 |
||||||
| U+11EF |  |
||||||
| U+11BC | |
+ | U+11C2 | |
|||
| U+11F0 | |
||||||
| U+11F0 | |
+ | U+11A8 | |
|||
| U+11F1 |  |
||||||
| U+11F2 | 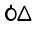 |
||||||
| U+11F0 | |
+ | U+11BF | |
|||
| U+11F0 | |
+ | U+11C2 | |
|||
| U+11BD | |
||||||
| U+11BD | |
+ | U+11B8 | |
|||
| U+11BD | |
+ | U+11B8 | |
+ | U+11B8 | |
| U+11BD | |
+ | U+11BD | |
|||
| U+11BE | |
||||||
| U+11BF | |
||||||
| U+11C0 | |
||||||
| U+11C1 | |
||||||
| U+11F3 |  |
||||||
| U+11C1 | |
+ | U+11BA | |
|||
| U+11C1 | |
+ | U+11C0 | |
|||
| U+11F4 |  |
||||||
| U+11C2 | |
||||||
| U+11F5 | 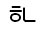 |
||||||
| U+11F6 |  |
||||||
| U+11F7 |  |
||||||
| U+11F8 |  |
||||||
| U+11F9 | |
||||||
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.
Script development specifications