Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This document presents information that will help font developers create or support OpenType fonts for all "standard" scripts covered by the Unicode Standard, for example: Latin, Cyrillic, Greek and Armenian.
Introduction
In this document, "standard" refers to any non-complex script, that is, any script that does not require re-ordering or contextual analysis.
Font developers will learn how to encode script features in their fonts, choose character sets, organize font information, and use existing tools to produce standard script fonts. Registered features of standard scripts are defined and illustrated, encodings are listed, and templates are included for compiling layout tables for OpenType fonts.
This document also presents information about the standard OpenType shaping engine of Uniscribe, an operating system component responsible for text layout.
In addition to being a primer and specification for the creation and support of standard script fonts, this document is intended to more broadly illustrate the OpenType Layout architecture, feature schemes, and operating system support for shaping and positioning text.
Glossary
The following terms are useful for understanding the layout features and script rules discussed in this document.
Base Glyph - Any glyph that can have a diacritic mark above or below it. Layout operations are defined in terms of a base glyph, not a base character, as a ligature may act as the base.
Character - Each character represents a Unicode character code point. For example the 'A' character is U+0041. A character may have multiple forms of glyphs.
Diacritic Marks - A character that is positioned above or below a character to provide pronunciation guidance (i.e. accent acute, grave, tilde, etc.)
Glyph - A glyph represents a form of one or more characters.
Ligature - A combination of glyphs that join to form a single glyph. It is up to the font designer to create the ligatures as he deems best for the font he is working with.
Standard Script - Any non-complex script; any script that does not require re-ordering or contextual analysis in the shaping process.
Shaping Engine
The Uniscribe standard shaping engine processes text in stages. The stages are:
- Shaping (substituting) glyphs with OTLS (OpenType Library Services)
- Positioning glyphs with OTLS
The descriptions which follow will help font developers understand the rationale for the standard feature encoding model, and help application developers better understand how layout clients can divide responsibilities with operating system functions.
Shaping with OTLS
The first step Uniscribe takes in shaping the character string is to map all characters to their nominal form glyphs.
Next, Uniscribe calls OTLS to apply the features. All OTL processing is divided into a set of predefined features (described and illustrated in the Features section of this document). Each feature is applied, one by one, to the appropriate glyphs in the syllable and OTLS processes them. Uniscribe makes as many calls to the OTL Services as there are features. This ensures that the features are executed in the desired order.
The steps of the shaping process are outlined below. Not all of the features listed apply to all standard script languages, but are features that are 'on' by default. However, you may choose to implement more features based on the script or language system.
Shaping features:
- Language forms
- Apply feature 'ccmp' to preprocess any glyphs that require composition or decomposition
- Typographical forms
- Apply feature 'liga' to compose any optional standard ligatures, like fi or fl
- Apply feature 'clig' to compose any optional contextual ligatures
Positioning glyphs with OTLS
Uniscribe next applies features concerned with positioning, calling functions of OTLS to position glyphs.
Positioning features:
- Kerning
- Apply feature 'kern' to provide pair kerning between base glyphs requiring adjustment for better typographical quality
- Mark to base
- Apply feature 'mark' to position diacritic glyphs to the base glyph
- Mark to Mark
- Apply feature 'mkmk' to position diacritic glyphs to other diacritic glyphs
Features
The features listed below have been defined to create the basic forms for standard scripts and languages. Regardless of the model an application chooses for supporting layout of standard scripts, Uniscribe requires a fixed order for executing features within a run of text to consistently obtain the proper basic form. This is achieved by calling features one-by-one in the standard order listed below.
The order of the lookups within each feature is also very important. For more information on lookups and defining features in OpenType fonts, see Encoding feature information in the OpenType font development section.
In the table below, required means that the feature will be applied during the shaping process and cannot be suppressed by the application where the text is being rendered. Applications may supress non-required features and they may trigger optional features (usually based on user’s discretion). The complete list of features is defined in the OpenType Spec.
The order for applying standard features encoded in OpenType fonts:
| Feature | Feature function | Layout operation | Required | ||
|---|---|---|---|---|---|
| Language based forms: | |||||
| ccmp | Character composition/decomposition substitution | GSUB | |||
| Typographical forms: | |||||
| liga | Standard ligature substitution | GSUB | |||
| clig | Contextual ligature substitution | GSUB | |||
| Positioning features: | |||||
| dist | Distances | GPOS | X | ||
| kern | Pair kerning | GPOS | |||
| mark | Mark to base positioning | GPOS | X | ||
| mkmk | Mark to mark positioning | GPOS | X | ||
| [GSUB = glyph substitution, GPOS = glyph positioning] | |||||
Descriptions and examples of above features
Character composition (and decomposition)
Feature Tag: "ccmp"
The 'ccmp' feature is used to compose a number of glyphs into one glyph, or decompose one glyph into a number of glyphs. This feature is implemented before any other features because there may be times when a font vender wants to control certain shaping of glyphs. An example of using this table is seen below. The 'ccmp' table maps default alphabetic forms to both a composed form (essentially a ligature, GSUB lookup type 4), and decomposed forms (GSUB lookup type 2).
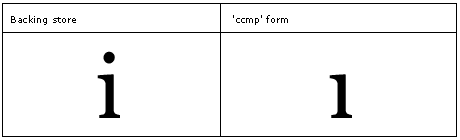
Example: The 'ccmp' feature is used to form the dotless i (used when the 'i' is followed by an above diacritic mark).
Standard ligatures
Feature Tag: "liga"
The 'liga' feature is used to map glyphs to their optional ligated form. Font developers should use this table for all ligatures that they want the user to be able to control by user preference. Uniscribe has a flag that will allow this type of feature to be deactivated. The 'liga' feature maps sequences of glyphs to corresponding ligatures (GSUB lookup type 4). Ligatures with more components must be stored ahead of those with fewer components in order to be found. See Ordering ligatures in the Encoding Feature Information section. The set of optional ligatures will vary by typeface design and script.
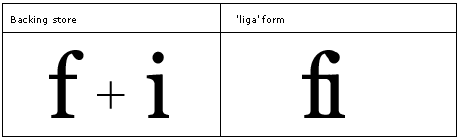
Example: a standard fi ligature.
Contextual ligatures
Feature Tag: "clig"
The 'clig' feature is used to map glyphs to their contextual ligated form which may be preferred for typographic purposes. Unlike other ligature features, 'clig' specifies the context in which the ligature is recommended. This capability is important in some script designs and for swash ligatures. The 'clig' table maps sequences of glyphs to corresponding ligatures in a chained context (GSUB lookup type 8). Ligatures with more components must be stored ahead of those with fewer components in order to be found. See Ordering ligatures in the Encoding Feature Information section. The set of optional contextual ligatures will vary by typeface design and script.
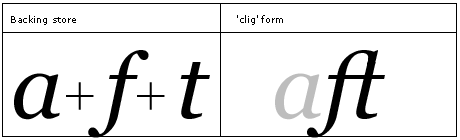
Example: The ligature glyph 'ft' replaces the sequence f t, except when preceded by an ascending letter.
Kerning
Feature Tag: "kern"
The 'kern' feature is used to adjust amount of space between glyphs, generally to provide optically consistent spacing between glyphs. Although a well-designed typeface has consistent inter-glyph spacing overall, some glyph combinations require adjustment for improved legibility. Besides standard adjustment in either horizontal or vertical direction, this feature can supply size-dependent kerning data via device tables, "cross-stream" kerning in the Y text direction, and adjustment of glyph placement independent of the advance adjustment. Note that this feature would not be used in monospaced fonts.
The font stores a set of adjustments for pairs of glyphs (GPOS lookup type 2 or 8). These may be stored as one or more tables matching left and right classes, and/or as individual pairs. If both forms are used, the classes should be listed last, so as to provide a means to replace any non-ideal values that may result from the class tables. Additional adjustments may be provided for larger sets of glyphs (e.g., triplets, quadruplets, etc.) to overwrite the results of pair kerns in particular combinations. These should precede the pairs.
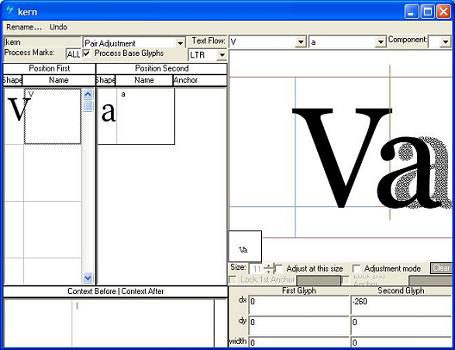
Creating a kerning pair using Microsoft VOLT
Mark to base positioning
Feature Tag: "mark"
The 'mark' feature positions mark glyphs in relation to a base glyph, or a ligature glyph. This feature may be implemented as a MarkToBase Attachment lookup (GPOS LookupType = 4) or a MarkToLigature Attachment lookup (GPOS LookupType = 5).
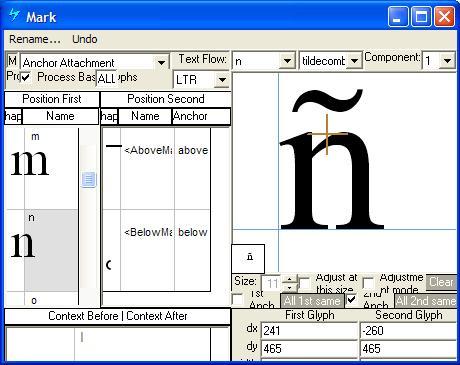
Positioning mark to base using Microsoft VOLT
Mark to mark positioning
Feature Tag: "mkmk"
The 'mkmk' feature positions mark glyphs in relation to another mark glyph. This feature may be implemented as a MarkToMark Attachment lookup (GPOS LookupType = 6).
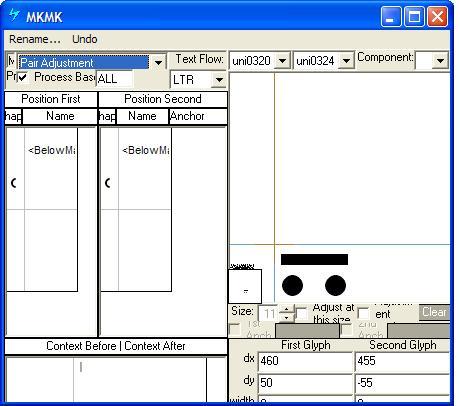
Positioning mark to mark using Microsoft VOLT
Appendix
Appendix: Writing System Tags
Features are encoded according to both a designated script and language system. The language system tag specifies a typographic convention associated with a language or linguistic subgroup. For example, there are different language systems defined for the Latin script; English, German, Spanish, etc.
Currently, the Uniscribe engine only supports the "default" language for each script. However, font developers may want to build language specific features which are supported in other applications and will be supported in future Microsoft OpenType implementations.
- NOTE: It is strongly recommended to include the "dflt" language tag in all OpenType fonts because it defines the basic script handling for a font. The "dflt" language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the "dflt" tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts and language systems.
| Registered tags for standard scripts | Registered tags for standard language systems | ||
|---|---|---|---|
| Script tag | Script | Language system tag | Language |
| "latn" | Latin | "dflt" | *default script handling |
| languages with Basic Latin & Latin-1: | |||
| "DAN " | Danish | ||
| "NLD " | Dutch | ||
| "ENG " | English | ||
| "FOS " | Faroese | ||
| "FIN " | Finnish | ||
| "FLE " | Flemish | ||
| "DEU " | German | ||
| "ISL " | Icelandic | ||
| "IRI " | Irish | ||
| "ITA " | Italian | ||
| "NOR " | Norwegian | ||
| "PTG " | Portuguese | ||
| "ESP " | Spanish | ||
| "SVE " | Swedish | ||
| languages with Unicode Extended Latin: | |||
| "AFK " | Afrikaans | ||
| "EUQ " | Basque | ||
| "BRE " | Breton | ||
| "CAT " | Catalan | ||
| "HRV " | Croatian | ||
| "CSY " | Czech | ||
| "NTO " | Esperanto | ||
| "ETI " | Estonian | ||
| "FRA " | French | ||
| "FRI " | Frisian | ||
| "GRN " | Greenlandic | ||
| "HUN " | Hungarian | ||
| "LAT " | Latin | ||
| "LVI " | Latvian | ||
| "LTH " | Lithuanian | ||
| "MTS " | Maltese | ||
| "PLK " | Polish | ||
| "PRO " | Provencal | ||
| "RMS " | Romansh | ||
| "ROM " | Romanian | ||
| "ROY " | Romany | ||
| "SKY " | Slovak | ||
| "SLV " | Slovenian | ||
| "LSB " | Sorbian (Lower) | ||
| "USB " | Sorbian (Upper) | ||
| "TRK " | Turkish | ||
| "WEL " | Welsh | ||
| "VIT " | Vietnamese | ||
| "cyrl" | Cyrillic | "dflt" | *default script handling |
| "RUS " | Russian | ||
| "grek" | Greek | "dflt" | *default script handling |
| "COP " | Coptic | ||
| "ELL " | Greek | ||
| "armn" | Armenian | "dflt" | *default script handling |
| "HYE " | Armenian | ||
| "geor" | Georgian | "dflt" | *default script handling |
| "KAT " | Georgian | ||
| "runr" | Runic | "dflt" | *default script handling |
| "ogam" | Ogham | "dflt" | *default script handling |
Note: both the script and language tags are case sensitive (script tags should be lowercase, language tags are all caps) and must contain four characters (ie. you must add a space to the three character language tags).
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.
Script development specifications