Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Typography
Last updated: September 2024
This document presents information that will help font developers in creating OpenType fonts for complex scripts included in the Unicode Standard 16.0, but not otherwise supported by a dedicated shaping engine.
Introduction
This document targets developers implementing shaping behavior compatible with the Microsoft OpenType specification for complex scripts not supported by a dedicated shaping engine. It contains information about terminology, font features and behavior of the Universal Shaping Engine (USE). While it does not contain instructions for creating fonts, it will help font developers understand how the Universal shaping engine processes complex script text.
How the Universal Shaping Engine works
The Universal Shaping Engine processes text in stages. The stages are:
- Character classification
- Split vowel handling
- Cluster validation
- OpenType feature application I
- Glyph reordering
- OpenType feature application II
Character classification
The run of text that the shaping engine receives for the purpose of shaping is a sequence of Unicode characters. Itemization preprocessing ensures that the runs of text being shaped contain characters belonging to a single script but may include SCRIPT_COMMON characters. The shaping engine divides the text into syllable clusters and identifies character properties. Character properties are used in parsing syllables and identifying their parts as well as determining whether any special behavior or contextual reordering is required. The Universal Shaping Engine (USE) generates character properties from Unicode data. There is a mapping between Unicode’s categories and the classes used internally by USE. This section defines how USE’s classes and subclasses are derived from Unicode data.
Unicode categories:
AJT = Unicode, Arabic Joining Type
UISC = Unicode, Indic Syllabic Category
UGC = Unicode, General Category
UIPC = Unicode, Indic Positional Category, prior to Unicode 8.0 this property was known as Indic Matra Category.
Note: Non-Indic complex scripts are not included in Unicode's UISC and UIPC data. Where necessary for USE's processing, data for such scripts has been provided in supplementary data files included in USE's GitHub archive. Hieroglyphic scripts require syllabic categories not defined in UISC. The use of these hieroglyphic categories is documented in this specification and the values are defined in the ISC-Additional data file.
Extended categories:
ESC = USE, Extended Syllabic Category
| Sigla | USE class | Derivation |
|---|---|---|
| B | BASE |
AJT = C, D, L, or R; UISC = Number; UISC = Avagraha & UGC = Lo; UISC = Bindu & UGC = Lo; UISC = Consonant; UISC = Consonant_Final & UGC = Lo; UISC = Consonant_Head_Letter; UISC = Consonant_Medial & UGC = Lo; UISC = Consonant_Subjoined & UGC = Lo; UISC = Tone_Letter; UISC = Vowel & UGC = Lo; UISC = Vowel_Independent; UISC = Vowel_Dependent & UGC = Lo |
| CGJ | CGJ |
U+034F |
| CM | CONS_MOD |
UISC = Nukta; UISC = Gemination_Mark; UISC = Consonant_Killer; UISC = Symbol_Modifier |
| CS | CONS_WITH_STACKER |
UISC = Consonant_With_Stacker |
| F | CONS_FINAL |
UISC = Consonant_Final & UGC != Lo; UISC = Consonant_Succeeding_Repha |
| FM | CONS_FINAL_MOD |
UISC = Syllable_Modifier |
| G | HIEROGLYPH |
ESC = Hieroglyph |
| GB | BASE_OTHER |
UISC = Consonant_Placeholder; U+2015, U+2022, U+25FB–25FE |
| H | HALANT |
UISC = Virama; UISC = Invisible_Stacker |
| HM | HIEROGLYPH_MOD |
ESC = Hieroglyph_Modifier |
| HN | HALANT_NUM |
UISC = Number_Joiner |
| HR | HIEROGLYPH_MIRROR |
ESC = Hieroglyph_Mirror |
| IND | BASE_IND |
UISC = Consonant_Dead; UISC = Modifying_Letter; UISC = Other; UGC = Po (Punctuation signs), except U+104E, U+2022 |
| J | HIEROGLYPH_JOINER |
ESC = Hieroglyph_Joiner |
| M | CONS_MED |
UISC = Consonant_Medial & UGC != Lo |
| N | BASE_NUM |
UISC = Brahmi_Joining_Number |
| O | OTHER |
Any other SCRIPT_COMMON characters; White space characters, UGC=Zs |
| R | REPHA |
UISC = Consonant_Preceding_Repha; UISC = Consonant_Prefixed |
| RK | Reordering Killer |
UISC = Reordering_Killer |
| Rsv | Reserved characters |
Any character not currently assigned or otherwise reserved in Unicode |
| S | SYM |
UGC = So except U+25CC; UGC = Sc |
| SB | HIEROGLYPH_SEGMENT_BEGIN |
ESC = Hieroglyph_Mark_Begin; ESC = Hieroglyph_Segment_Begin |
| SE | HIEROGLYPH_SEGMENT_END |
ESC = Hieroglyph_Mark_End; ESC = Hieroglyph_Segment_End |
| SUB | CONS_SUB |
UISC = Consonant_Subjoined & UGC != Lo |
| V | VOWEL |
UISC = Vowel & UGC != Lo; UISC = Vowel_Dependent & UGC != Lo; UISC = Pure_Killer |
| VM | VOWEL_MOD |
UISC = Bindu & UGC != Lo; UISC = Tone_Mark; UISC = Cantillation_Mark; UISC = Register_Shifter; UISC = Visarga |
| VS | VARIATION_SELECTOR |
U+FE00‒FE0F |
| WJ | Word joiner |
U+2060 |
| ZWJ | Zero width joiner |
UISC = Joiner |
| ZWNJ | Zero width non-joiner |
UISC = Non_Joiner |
Classes that can vary by position are defined in Unicode’s Indic_Positional_Category (UIPC), additional subclasses are defined:
| Sigla | USE subclass | Derivation |
|---|---|---|
| CMAbv | CONS_MOD_ABOVE | UIPC = Top |
| CMBlw | CONS_MOD_BELOW | UIPC = Bottom |
| FAbv | CONS_FINAL_ABOVE | UIPC = Top |
| FBlw | CONS_FINAL_BELOW | UIPC = Bottom |
| FPst | CONS_FINAL_POST | UIPC = Right |
| MAbv | CONS_MED_ABOVE | UIPC = Top |
| MBlw | CONS_MED_BELOW | UIPC = Bottom |
| MPre | CONS_MED_PRE | UIPC = Left |
| MPst | CONS_MED_POST | UIPC = Right |
| VAbv | VOWEL_ABOVE | UIPC = Top |
| VOWEL_ABOVE_BELOW | UIPC = Top_And_Bottom | |
| VOWEL_ABOVE_BELOW_POST | UIPC = Top_And_Bottom_And_Right | |
| VOWEL_ABOVE_POST | UIPC = Top_And_Right | |
| VBlw | VOWEL_BELOW |
UIPC = Bottom; UIPC = Overstruck |
| VOWEL_BELOW_POST | UIPC = Bottom_And_Right | |
| VPre | VOWEL_PRE | UIPC = Left |
| VOWEL_PRE_ABOVE | UIPC = Top_And_Left | |
| VOWEL_PRE_ABOVE_POST | UIPC = Top_And_Left_And_Right | |
| VOWEL_PRE_POST | UIPC = Left_And_Right | |
| VPst | VOWEL_POST | UIPC = Right |
| VMAbv | VOWEL_MOD_ABOVE | UIPC = Top |
| VMBlw | VOWEL_MOD_BELOW |
UIPC = Bottom; UIPC = Overstruck |
| VMPre | VOWEL_MOD_PRE | UIPC = Left |
| VMPst | VOWEL_MOD_POST | UIPC = Right |
Overrides to Unicode categories
USE makes use of overrides to Unicode categories to achieve the desired shaping behavior when the Unicode value is not well aligned with shaping requirements or when no Unicode value is provided. These overides are available in two data files:
Split vowel handling
USE decomposes split vowel characters belonging to UISC = Vowel_Dependent according to character decomposition mappings defined in UnicodeData.txt:
0DCF;SINHALA VOWEL SIGN AELA-PILLA;Mc;0;L;;;;;N;;;;;
0DD9;SINHALA VOWEL SIGN KOMBUVA;Mc;0;L;;;;;N;;;;;
0DDC;SINHALA VOWEL SIGN KOMBUVA HAA AELA-PILLA;Mc;0;L;0DD9 0DCF;;;;N;;;;;
When a decomposition is not defined in UnicodeData.txt, it is up to the font developer to handle any required decomposition during GSUB processing.
Cluster validation, is done based on the decomposed state of a split vowel. Therefore, the validation schemas only take into account the cardinal positions (Pre, Above, Below, Post) since the full decompositions occupy one position only. Therefore cluster validation depends on the sequence of decompositions which may be more restrictive than with ordinary vowels.
- Split vowel decomposition needs to be applied recursively so that split vowels get fully decomposed before shaping is applied
- Note, if a character belonging to a split vowel class that includes Pre, does not have a canonical decomposition, it is up to the font developer to specify a decomposition. The logical first glyph in that decomposition will be considered to be the VPre. Any subsequent glyphs from that decomposition will not reorder. There are no characters of this category in the currently supported scripts
Note: Font developers must include glyphs for all required decompositions.
Cluster validation
Cluster validation allows sequences of characters to be arranged into groups called “clusters” based on their classification (both class and subclass). In Abugida writing systems, a cluster is an orthographic unit of text that combines multiple phonetic and orthographic elements. It is desirable to control the sequence of characters forming a cluster so that a single visual cluster does not have multiple different encoding sequences as that would create problems for data interchange in terms of stability and security.
USE employs a generalized and permissive cluster structure in order to be flexible enough to accommodate a wide range of script needs. The goal of the clustering logic is to enable what is graphically consistent with a given script’s rules, rather than enforcing particular orthographic or linguistic rules. Such considerations should be applied at another layer, such as a spelling checker.
The maximal cluster scheme used by USE may be visualized as follows:
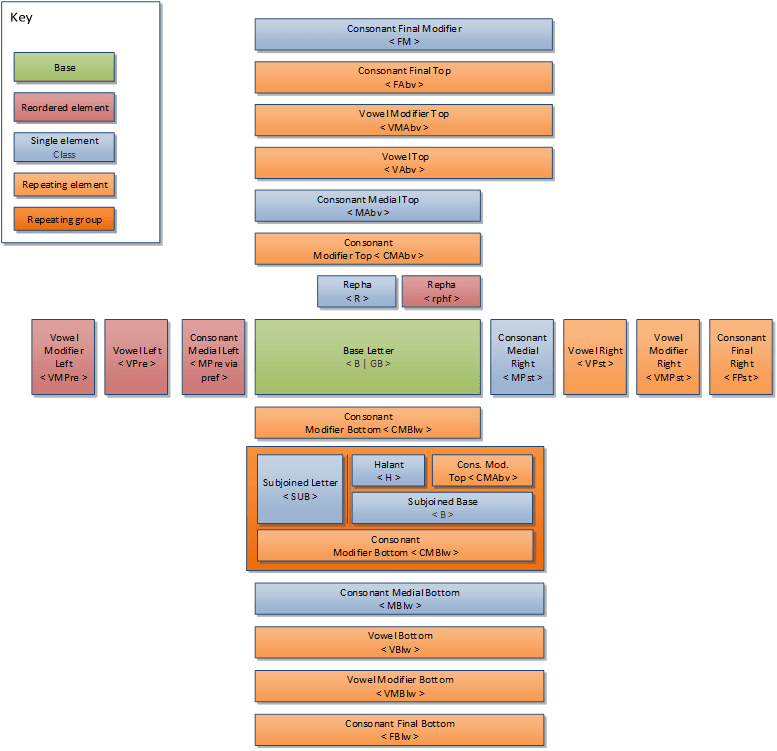
Visualized form of standard cluster in the Universal Shaping Engine
Schemas and rules for cluster analysis and syllable analysis use the following additional symbols:
| X* | sequence of zero or more occurrences of X |
| X+ | sequence of one or more occurrences of X |
| <X | Y> | disjunction of elements: X or Y |
| [X] | optional (zero or one) occurrence of X |
| # | occurrence of a boundary |
| × | no boundary allowed at indicated position |
| ÷ | boundary allowed at indicated position |
| ^ | Except |
Well-formed character clusters can have combinations of groups as defined below. There are four options:
Independent cluster
< IND | O | Rsv | WJ > [VS]The independent cluster normally consists of a single member. The only other character class it can combine with is VARIATION_SELECTOR. The BASE_IND, OTHER, Reserved Characters and the word joiner (WJ) can only have a single code point per cluster. When a VARIATION_SELECTOR occurs in any context other than immediately following one of the valid bases (IND, O, Rsv, WJ, B, GB, N, S), it forms an independent cluster.
Standard cluster
[< R | CS >] < B | GB > [VS] (CMAbv)* (CMBlw)* (< H B [VS] | SUB > (CMAbv)* (CMBlw)*)* [MPre] [MAbv] [MBlw] [MPst] (VPre)* (VAbv)* (VBlw)* (VPst)* (VMPre)* (VMAbv)* (VMBlw)* (VMPst)* (FAbv)* (FBlw)* (FPst)* [FM]The only required component of a standard cluster is a BASE or BASE_OTHER. A cluster may optionally begin with a REPH or CONS_WITH_STACKER. A BASE or BASE_OTHER may be followed immediately by a VARIATION_SELECTOR and/or multiple CONS_MOD characters in the order CONS_MOD_ABOVE CONS_MOD_BELOW. Multiple sequences of a HALANT BASE with optional VARIATION_SELECTOR or optional CONS_MOD can occur. The sequence can continue with zero or one CONS_MED for each cardinal position (Pre, Above, Below, Post); zero to many VOWEL characters in each cardinal position; zero to many VOWEL_MODs in each cardinal position; zero to many CONS_FINALs in each of Above, Below, and Post; and lastly, an optional FINAL_MOD.
Virama terminated cluster
[< R | CS >] < B | GB > [VS] (CMAbv)* (CMBlw)* (< H B [VS] | SUB > (CMAbv)* (CMBlw)*)* < H | RK >This is similar to the Standard cluster but terminates in a final HALANT or RK. When a HALANT or RK follows a BASE or BASE_OTHER it will form a cluster. When any character other than a Base follows the Virama or RK there will be a cluster break between the Virama and the following character. Multiple sequences of a HALANT BASE with optional VARIATION_SELECTOR or optional CONS_MOD can occur. A CONS_SUB is equivalent to the sequence HALANT BASE.
Number-joiner terminated cluster
N [VS] (HN N [VS])* HNWhen HALANT_NUM follows a BASE_NUM it will form a cluster. When any character other than BASE_NUM follows the HALANT_NUM there will be a cluster break between the HALANT_NUM and the following character. A BASE_NUM may be followed immediately by a VARIATION_SELECTOR. Multiple sequences of a HALANT_NUM BASE_NUM with optional VARIATION_SELECTOR can occur.
Numeral cluster
N [VS] (HN N [VS])*A BASE_NUM may form a cluster with another BASE_NUM when joined using a HALANT_NUM. The join may be repeated. Any BASE_NUM may be followed by a VARIATION_SELECTOR.
Symbol cluster
< S | GB > [VS] (CMAbv)* (CMBlw)*A SYM character may be followed by an optional VARIATION_SELECTOR and zero to many CONS_MOD_ABOVE, then zero to many CONS_MOD_BELOW.
Hieroglyph cluster
SB* G [VS] [HR] [HM] SE* ( J SB* G [VS] [HR] [HM] SE* )*The basic unit of a Hieroglyph cluster is a HIEROGLYPH character. Each HIEROGLYPH character may be modified by zero or one of each of the following in this order:
- VARIATION_SELECTOR — used to select a specific graphic variant of the base HIEROGLYPH
- HIEROGLYPH_MIRROR — used to select a horizontally mirrored alternate of the base
- HIEROGLYPH_MODIFIER — used to specify graphic variation of the base
The base HIEROGLYPH may be preceded by zero or more HIEROGLYPH_SEGMENT_BEGIN characters and and may be followed by zero or more HIEROGLYPH_SEGMENT_END characters. This basic unit may be extended by joining additional instances of this unit using a HIEROGLYPH_JOINER.
Hieroglyph clusters may be nested. Hieroglyph clusters are attested with three levels of nested segments. Therefore, at least two HIEROGLYPH_SEGMENT_BEGIN and at least two HIEROGLYPH_SEGMENT_END characters can occur in sequence. So, at minimum SB* and SE* should be SB{0,2} and SE{0,2}, respectively, in the above model.
To support input of Hieroglyph clusters character-by-character, implementations should support a Hieroglyph cluster terminated by a joiner so the cluster is valid prior to input of a following HIEROGLYPH character.
Note: Superfluous use of nested segments may prevent text matching in collation scenarios. However, this cluster model does not check for or enforce the minimal use of nested segments. Marking superfluous use of nested segments is left to a higher-level protocol such as orthographic checking.
Independent Vowel (IV) plus Dependent Vowel constraints (DV)
The core-specification of the Unicode standard prohibits forming certain IV forms from other bases plus a DV (e.g., TUS Table 13-0). Since these combinations apply to particular pairs and not globally across classes, USE maintains a list of prohibited sequences where they would not be prohibited by the cluster model. The list of prohibited sequences is available as a data file: IndicShapingInvalidCluster.txt.
Combining Grapheme Joiner (CGJ)
CGJ has been omitted from the above schema in order to avoid unnecessary complexity. It may occur anywhere in a cluster with no effect. The purpose of CGJ is to block normalization processing which could change the order of marks in a sequence. CGJ handling will need to be updated if USE is modified to support normalization.
Zero-width non-joiner (ZWNJ)
The zero-width non-joiner is used to prevent a fusion of two characters. It continues a preceding cluster but causes a cluster break after itself when the following character is not a mark character (gc=Mn or gc=Mc). ZWNJ does not reset the cluster model.
Zero-width joiner (ZWJ)
The zero-width joiner is used to fuse two characters. It continues a preceding cluster and joins it to a following character unless the following character is another ZWJ. In which case there will be a cluster break between the two ZWJs. ZWJ does not reset the cluster model.
Standalone characters
Characters of the class BASE_IND occur as standalone characters and do not form clusters with following characters. When a character belong to class VS or WJ occurs outside of a cluster, i.e., at the start of a run, or following one of these standalone characters, they should also be treated as standalone characters.
Defective clusters
When a cluster starts with any character that has UGC=Mc or UGC=Mn, USE inserts a dotted circle glyph (U+25CC) to indicate a broken cluster. Defective clusters do not form extended clusters themselves. A sequence of marks without a valid base forms separate clusters for each mark. Note that an explicit character U+25CC is a valid generic base (GB, BASE_OTHER) and so can form extended clusters.
Cluster length
A practical maximum cluster length is 31 characters. After this limit is reached, a cluster break may be forced and a new cluster is started. During GSUB processing a cluster may expand considerably beyond 31 glyphs.
OpenType feature application I
Basic cluster formation GSUB
Default glyph pre-processing group
These features are applied together, one cluster at a time. Lookups associated with any of these features will be triggered in the lookup-order specified by the font developer. It is possible to interleave lookups for different features. The order of features given here is recommended.
- locl — Localized forms
This provides a starting point to shape any language-specific forms. USE leverages any language system tags provided by the edit control to trigger language-specific substitutions. - ccmp — Glyph composition/decomposition
- nukt ― Nukta forms
This feature is intended to enable substitutions with a combining nukta. In general terms, a nukta is a consonant modifier that may be used to indicate an alternate phoneme, often used to indicate foreign sounds to the native language of the writing system. - akhn ― Akhands
Used to form traditional ligatures from sequences
Reordering group
These features are applied individually in this order, rphf, pref. The output of each of these features is reordered as specified in the next section.
- rphf ― Reph form
This feature is traditionally applied to invoke a combining form of a preconsonantal r, which reorders after the following base. This feature may be used generically to identify any component which has the reordering properties of a reph. Feature application is scoped to the first three glyphs in a cluster. - pref — Pre-base forms
This feature may be used generically to identify a post-base component that has the reordering properties of a pre-base medial consonant. The feature is applied to the entire cluster.
Note that reordering is not done until after all of the basic features have been applied.
Orthographic unit shaping group
Like the Default glyph pre-processing group, these features are applied together, one cluster at a time. It is, therefore, up to the font developer to specify the order of lookups for these features in the font’s OTL. The order given here is recommended but not required.
- rkrf — Rakar forms
- abvf — Above-base forms
This feature should be used to trigger substitutions relating to above-base components. - blwf — Below-base forms
This feature should be used to trigger substitutions relating to below-base components. - half ― Half forms
This feature is used to invoke half forms for scripts that use them. - pstf — Post-base forms
This feature should be used to trigger substitutions relating to post-base components. - vatu ― Vattu variants
This feature is used to trigger ligatures with a below-base form. - cjct ― Conjunct forms
This feature is used to complete basic conjunct forms not already covered by other features.
Glyph reordering
All reordering and anchoring of marks is done in relation to the base consonant. USE does reordering in a single late phase. This is because all reordering is dependent on the formation of the base which may be modified during basic cluster formation. USE does not do checks or look-ahead in a font’s feature tables. Therefore feature lookups for the basic features must be designed for the logical glyph order before any reordering has been applied. There are two categories of glyphs that reorder: feature based and property based. Actual glyph reordering is done between basic cluster formation (OpenType feature application I) and Topographical substitutions (first part of OpenType feature application II). Reordering is applied in logical order: rphf, pref, VPre, VMPre:
| Before reordering |  |
| After reordering |  |
When the base cluster is broken by an explicit virama that has not been replaced during basic cluster formation the reordering is impacted since reordering components do not reorder past an explicit virama:
| Before reordering |  |
| After reordering |  |
If a font developer wants the reordering behavior to not be blocked by an explicit virama, they can substitute the virama for an alternate glyph during basic cluster formation so that USE treats the cluster as a continuous cluster without explicit virama.
Feature-based reordering
| Sigla | Name | Description |
|---|---|---|
| rphf | Reph form | Many abugida scripts render a preconsonantal r as a sign above the consonant it precedes. This sign is called reph. For the purposes of OT layout, reph is normally rendered with a mark glyph, and as such, must follow the base to which it applies. Contexts which produce the reph glyph must use the 'rphf' feature. The output of this feature reorders after the following full base. Reph does not reorder past an explicit Virama. Lookups under the rphf feature should output no more than one glyph per cluster. |
| pref | Pre-base form | Scripts (e.g., Javanese) may reorder a medial consonant to the beginning of a cluster based on context. The contextual logic is encoded in the font’s OT logic. Cases which require reordering should use the 'pref' feature to identify the glyph or glyphs that is or are to be reordered. One or more glyphs may be substituted for a single feature glyph that is to be reordered before the first spacing glyph in the cluster or the first spacing glyph after an explicit virama if present. Only one such glyph is reordered per cluster. |
- Note that prebase medial consonants (CONS_MED_PRE) do not get reordered automatically by USE. Rather, the font designer is expected to use the 'pref' feature to signal when a glyph belonging to this class should be reordered through the application of the pref feature. Only one glyph per cluster can be reordered using 'pref'.
Property-based reordering
| Sigla | Name | Description |
|---|---|---|
| R | REPHA | Pre-base REPHA is reordered by USE after a following full base as if the 'rphf' feature has been applied. Font developers do not need to use the 'rphf' feature explicitly. |
| VPre | VOWEL_PRE | Pre-base vowels and pre-base vowel components from split vowels are reordered before the base glyph and, if present, before a pre-base glyph reordered via the 'pref' feature. |
| VMPre | VOWEL_MOD_PRE | Pre-base vowel modifiers are reordered before the base glyph and, if present, before a pre-base vowel and/or before a pre-base glyph reordered via the 'pref' feature. |
- Note that the category REPHA is not currently supported by USE.
- Note that the split vowels, VOWEL_PRE_ABOVE, VOWEL_PRE_ABOVE_POST, and VOWEL_PRE_POST have multiple positions that include a pre-base element. Since split vowel decomposition is done before reordering, only one glyph will have the VOWEL_PRE class, and so only this vowel class needs special handling at this stage.
OpenType feature application II
Topographical features, GSUB
USE applies positional features required for scripts like Arabic which have alternate glyph shapes depending on the position of a glyph within a word.
- isol ― Isolated forms
- init ― Initial forms
- medi ― Medial forms
- fina ― Final forms
USE applies these as required features on a per cluster basis in order to invoke a particular form based on non-joining or white space boundaries. Non-joining boundaries occur between glyphs belonging to a joining script when one or both characters have a non-joining property that applies to the side of the connection on which a join would occur. The control characters ZWJ and ZWNJ may be used to artificially invoke or prevent a join. Joining properties are defined by the Unicode property Joining Type in ArabicShaping.txt.
Note:Support for topographical features for non-joining scripts is not currently implemented in USE. Additional specification is required.
Standard typographic presentation, GSUB
The remaining required features are applied all together to the entire run. It is up to the font developer to specify the order of lookups for this set of features:
- abvs — Above-base substitutions
- blws — Below-base substitutions
- calt — Contextual alternates
- clig — Contextual ligature
- haln ― Virama forms
- liga — Standard ligatures [horizontal text only]
- pres — Pre-base substitutions
- psts — Post-base substitutions
- rclt ― Required contextual forms
- rlig — Required ligatures [horizontal text only]
- vert — Vertical writing [implemented by edit control]
- vrt2 — Vertical alternates and rotation [implemented by edit control]
The vertical layout features are applied when text layout is vertical and triggered by the edit control as a custom feature. Only one feature vert or vrt2 should be applied, not both.
Custom substitution features requested by the application, GSUB
Positional feature application, GPOS
During GPOS processing, these required features are applied simultaneously to the entire run. The order specified here is recommended, but it is up to font developers to define the order of GPOS lookups for this set of features in OTL.
- curs — Cursive positioning
This feature should be used to position bases in relation to other bases. - dist — distances
This feature should be used to make required width adjustments. - kern — Kerning
This feature should be used to provide optimal letter spacing. This feature can be disabled by edit controls. - mark — Mark positioning
This feature should be used to position marks in relation to a base sign. - abvm — Above-base mark positioning
This feature is functionally equivalent to the mark feature. It may be used as an organizing mechanism to separate above mark processing from below mark processing. - blwm — Below-base mark positioning
This feature is functionally equivalent to the mark feature. It may be used as an organizing mechanism to separate below mark processing from above mark processing. - mkmk — Mark to Mark Positioning
This feature should be used to position marks in relation to preceding marks.
An important OT technique for excluding certain base glyphs from contextual lookups is to classify the base glyph as a mark in the font's GDEF table, since marks can be selectively included or omitted from OT processing. However, whenever this technique is used, the width of the base glyph must be added back using the 'dist' feature. This is necessary because OT processing cancels the width associated with a mark. It is necessary to cancel the width of a non-spacing mark because it is not clear where to apply the width of a non-spacing mark during OpenType processing.
A typical use case of this is Javanese which has prebase vowels. Since the prebase vowels do not reorder until after basic cluster formation, they are present in their logical position. This may interrupt other contextual substitutions. If the vowels are treated as marks, they can be excluded from OT context, and thus reduce the number of contextual rules required for processing. Consequently the expected width of the prebase vowels may be restored with the dist feature, for example (in VOLT OT Language):
DEF_LOOKUP "j.dist_preVowel" PROCESS_BASE PROCESS_MARKS ALL DIRECTION LTR
AS_POSITION
ADJUST_SINGLE
GLYPH "jSignE" BY POS ADV 1433 END_POS
GLYPH "jSignAi" BY POS ADV 1433 END_POS
END_ADJUST
END_POSITION
END
Other encoding issues
Handling invalid combining marks
Combining marks and signs that do not occur in conjunction with a valid base are considered invalid. USE treats an invalid mark as a separate cluster and displays the stand-alone mark positioned on a dotted circle (U+25CC). If multiple marks are required to position on a dotted circle, the dotted circle can be explicitly inserted into the text stream followed by any marks in accordance with the standard clustering rules.
To allow for shaping engine implementations that expect to position an invalid mark on a dotted circle, it is recommended that font using USE contain glyphs for the dotted circle character, U+25CC. If this character is not supported in the font, such implementations will display invalid signs on the missing glyph shape (white box).
Recommended Glyphs
Unicode code points that are recommended for inclusion in any font using USE are:
| Code point | Description |
|---|---|
| U+200B | Zero Width Space |
| U+200C | Zero Width Non-Joiner |
| U+200D | Zero Width Joiner |
| U+25CC | Dotted Circle |
| U+00A0 | No-break space |
| U+00D7 | Multiplication sign |
| U+2012 | Figure dash |
| U+2013 | En dash |
| U+2014 | Em dash |
| U+2015 | Horizontal bar |
| U+2022 | Bullet |
| U+25FB | White medium square |
| U+25FC | Black medium square |
| U+25FD | White medium small square |
| U+25FE | Black medium small square |
Appendix
Writing system and language tags
OpenType features are enabled in a font according to both a designated script and language system. The language system tag specifies a typographic convention associated with a language or linguistic subgroup. Not all software applications support specific language tags for use when rendering text runs.
Note: It is strongly recommended to include the “dflt” language tag in all OpenType fonts because it defines the basic script handling for a font. The “dflt” language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the “dflt” tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts currently supported by USE. This list will grow as new complex scripts are enabled by Unicode and USE is updated. Language system tags are not listed here and should be determined by font developers as appropriate for the script concerned.
| Registered tags for the Universal Shaping Engine | |
|---|---|
| Script | Script tag |
| ADLaM | adlm |
| Ahom | ahom |
| Bhaiksuki | bhks |
| Balinese | bali |
| Batak | batk |
| Brahmi | brah |
| Buginese | bugi |
| Buhid | buhd |
| Chakma | cakm |
| Cham | cham |
| Chorasmian | chrs |
| Cypro Minoan | cpmn |
| Dives Akuru | diak |
| Dogra | dogr |
| Duployan | dupl |
| Egyptian Hieroglyphs | egyp |
| Elymaic | elym |
| Garay | gara |
| Grantha | gran |
| Gunjala Gondi | gong |
| Gurung Khema | gukh |
| Hanifi Rohingya | rohg |
| Hanunoo | hano |
| Javanese | java |
| Kaithi | kthi |
| Kawi | kawi |
| Kayah Li | kali |
| Kharoshthi | khar |
| Khitan Small Script | kits |
| Khojki | khoj |
| Khudawadi | sind |
| Kirat Rai | krai |
| Lepcha | lepc |
| Limbu | limb |
| Mahajani | mahj |
| Makasar | maka |
| Mandaic | mand |
| Manichaean | mani |
| Marchen | marc |
| Masaram Gondi | gonm |
| Medefaidrin | medf |
| Meitei Mayek | mtei |
| Miao | plrd |
| Modi | modi |
| Mongolian | mong |
| Multani | mult |
| Nag Mundari | nagm |
| Nandinagari | nand |
| Newa | newa |
| N’Ko | nko |
| Nyiakeng Puachue Hmong | hmnp |
| Old Sogdian | sogo |
| Old Uyghur | ougr |
| Ol Onal | onao |
| Pahawh Hmong | hmng |
| Phags-pa | phag |
| Psalter Pahlavi | phlp |
| Rejang | rjng |
| Saurashtra | saur |
| Sharada | shrd |
| Siddham | sidd |
| Sinhala | sinh |
| Sogdian | sogd |
| Soyombo | soyo |
| Sunuwar | sunu |
| Sundanese | sund |
| Syloti Nagri | sylo |
| Tagalog | tglg |
| Tagbanwa | tagb |
| Tai Le | tale |
| *Tai Tham | lana |
| Tai Viet | tavt |
| Takri | takr |
| Tangsa | tnsa |
| Tibetan | tibt |
| Tifinagh | tfng |
| Tirhuta | tirh |
| Todhri | todr |
| Toto | toto |
| Tulu Tigalari | tutg |
| Vithkuqi | vith |
| Wancho | wcho |
| Yezidi | yezi |
| Zanabazar Square | zanb |
Note: script tags are case sensitive (script tags should be lowercase) and must contain four characters.
Note: Tai Tham support is currently limited. Additional encoding work is required for full text representation to be possible.
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.
Script development specifications