Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Performs a (standard layers) one-layer gated recurrent unit (GRU) function on the input. This operator uses multiple gates to perform this layer. These gates are performed multiple times in a loop dictated by the sequence length dimension and the SequenceLengthsTensor.
Equation for the forward direction
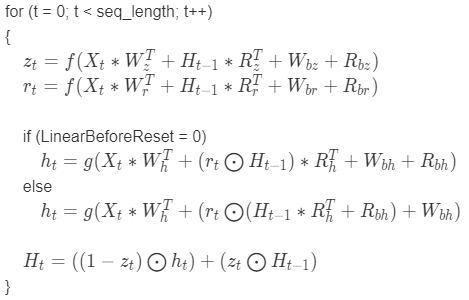
Equation for the backward direction
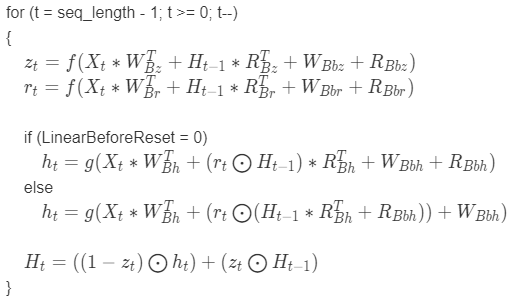
Equation legend

Syntax
struct DML_GRU_OPERATOR_DESC {
const DML_TENSOR_DESC *InputTensor;
const DML_TENSOR_DESC *WeightTensor;
const DML_TENSOR_DESC *RecurrenceTensor;
const DML_TENSOR_DESC *BiasTensor;
const DML_TENSOR_DESC *HiddenInitTensor;
const DML_TENSOR_DESC *SequenceLengthsTensor;
const DML_TENSOR_DESC *OutputSequenceTensor;
const DML_TENSOR_DESC *OutputSingleTensor;
UINT ActivationDescCount;
const DML_OPERATOR_DESC *ActivationDescs;
DML_RECURRENT_NETWORK_DIRECTION Direction;
BOOL LinearBeforeReset;
};
Members
InputTensor
Type: const DML_TENSOR_DESC*
A tensor containing the input data, X. Packed (and potentially padded) into one 4D tensor with the Sizes of { 1, seq_length, batch_size, input_size }. seq_length is the dimension that is mapped to the index, t. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
WeightTensor
Type: const DML_TENSOR_DESC*
A tensor containing the weight data, W. Concatenation of W_[zrh] and W_B[zrh] (if bidirectional). The tensor has Sizes { 1, num_directions, 3 * hidden_size, input_size }. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
RecurrenceTensor
Type: const DML_TENSOR_DESC*
A tensor containing the recurrence data, R. Concatenation of R_[zrh] and R_B[zrh] (if bidirectional). The tensor has Sizes { 1, num_directions, 3 * hidden_size, hidden_size }. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
BiasTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
An optional tensor containing the bias data, B. Concatenation of (W_b[zrh], R_b[zrh]) and (W_Bb[zrh], R_Bb[zrh]) (if bidirectional). The tensor has Sizes { 1, 1, num_directions, 6 * hidden_size }. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
HiddenInitTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
An optional tensor containing the hidden node initializer tensor, H_t-1 for the first loop index t. If not specified, then defaults to 0. This tensor has Sizes { 1, num_directions, batch_size, hidden_size }. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
SequenceLengthsTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
An optional tensor containing an independent seq_length for each element in the batch. If not specified, then all sequences in the batch have length seq_length. This tensor has Sizes { 1, 1, 1, batch_size }. The tensor doesn't support the DML_TENSOR_FLAG_OWNED_BY_DML flag.
OutputSequenceTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
An optional tensor with which to write the concatenation of all the intermediate output values of the hidden nodes, H_t. This tensor has Sizes { seq_length, num_directions, batch_size, hidden_size }. seq_length is mapped to the loop index t.
OutputSingleTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
An optional tensor with which to write the last output value of the hidden nodes, H_t. This tensor has Sizes { 1, num_directions, batch_size, hidden_size }.
ActivationDescCount
Type: UINT
This field determines the size of the ActivationDescs array.
ActivationDescs
Type: _Field_size_(ActivationDescCount) const DML_OPERATOR_DESC*
An array of DML_OPERATOR_DESC containing the descriptions of the activation operators, f() and g(). Both f() and g() are defined independently of direction, meaning that if DML_RECURRENT_NETWORK_DIRECTION_FORWARD or DML_RECURRENT_NETWORK_DIRECTION_BACKWARD are supplied in Direction, then two activations must be provided. If DML_RECURRENT_NETWORK_DIRECTION_BIDIRECTIONAL is supplied, then four activations must be provided. For bidirectional, activations must be provided f() and g() for forward followed by f() and g() for backwards.
Direction
Type: const DML_RECURRENT_NETWORK_DIRECTION*
The direction of the operator—forward, backwards, or bidirectional.
LinearBeforeReset
Type: BOOL
TRUE to specify that, when computing the output of the hidden gate, the linear transformation should be applied before multiplying by the output of the reset gate. Otherwise, FALSE.
Availability
This operator was introduced in DML_FEATURE_LEVEL_1_0.
Tensor constraints
BiasTensor, HiddenInitTensor, InputTensor, OutputSequenceTensor, OutputSingleTensor, RecurrenceTensor, and WeightTensor must have the same DataType.
Tensor support
| Tensor | Kind | Supported dimension counts | Supported data types |
|---|---|---|---|
| InputTensor | Input | 4 | FLOAT32, FLOAT16 |
| WeightTensor | Input | 4 | FLOAT32, FLOAT16 |
| RecurrenceTensor | Input | 4 | FLOAT32, FLOAT16 |
| BiasTensor | Optional input | 4 | FLOAT32, FLOAT16 |
| HiddenInitTensor | Optional input | 4 | FLOAT32, FLOAT16 |
| SequenceLengthsTensor | Optional input | 4 | UINT32 |
| OutputSequenceTensor | Optional output | 4 | FLOAT32, FLOAT16 |
| OutputSingleTensor | Optional output | 4 | FLOAT32, FLOAT16 |
Requirements
| Requirement | Value |
|---|---|
| Header | directml.h |